Fast, faster, Qwen. 🚀
Thrilled to see Qwen3.5 reaching a record-breaking 580 tps for agentic workloads on the TokenSpeed engine! This milestone wouldn't be possible without our incredible partners.
Huge thanks to @lightseekorg, @NVIDIAAI, the Mooncake team, and @tri_dao for the pioneering FA4 optimization. Together, we are pushing the boundaries of open-source LLM inference. 🤝✨
Dive into the full @PyTorch blog post below! 👇
https://t.co/p04wookcZj
#Qwen #Qwen3_5 #TokenSpeed #LLM #Inference #AI #PyTorch #OpenSource #AgenticAI #HighPerformance
This 2 hour Stanford lecture shows exactly how Stanford trains it's engineers to build AI systems. It's more practical than every Claude tutorial & prompting threads you've seen.
Bookmark & give it 2 hours, no matter what. It'll be the most productive thing you do this weekend.
🚨📄 New preprint! We find the “boiling the frog” equivalent of AI use. In a series of RCTs, we show that after just 10 min of AI assistance people perform worse and give up more often than those who never used AI.
w Grace Liu @brianchristian Mira Dumbalska and Rachit Dubey 🧵
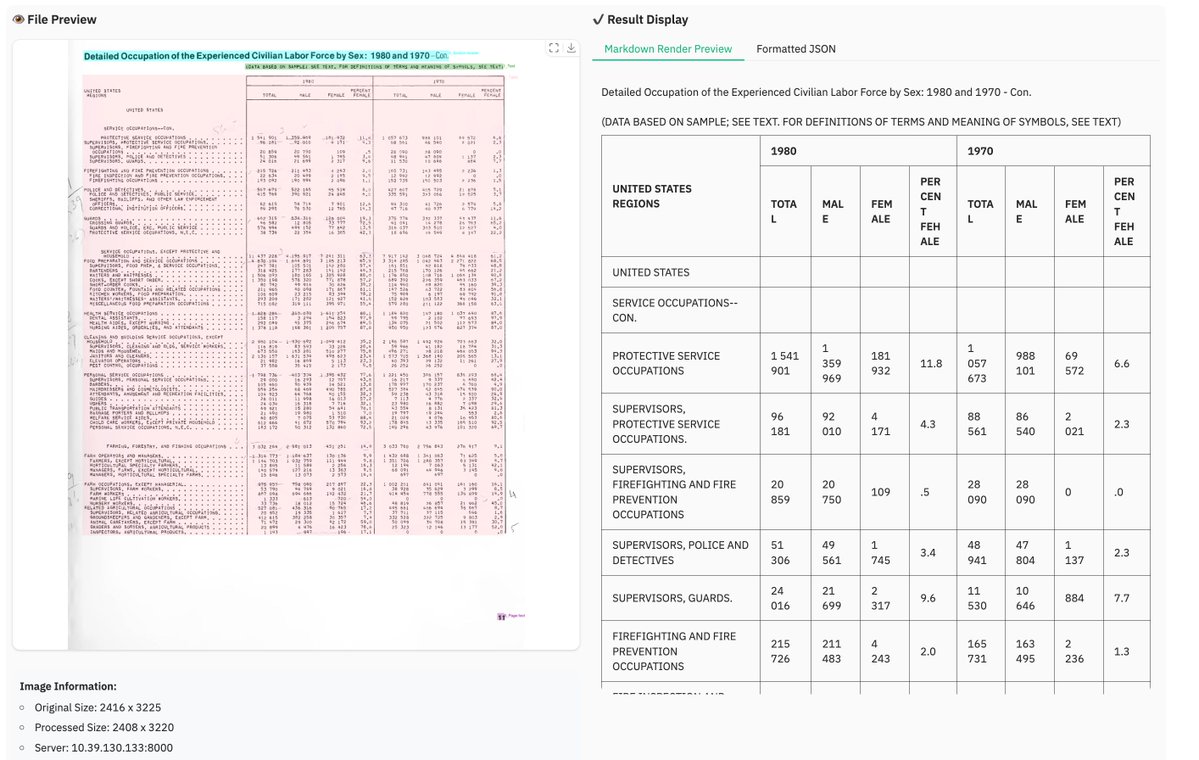
New blog post: converting 30k @arxiv papers to Markdown using SOTA OCR models to enable chat with paper functionality
Includes:
> leveraging an open OCR model (Chandra 2 by @datalabto)
> running on GPU infra - @huggingface Jobs
> using Codex with a SKILL.md
I made a Claude Code skill that turns any arxiv paper into working code.
Every line traces back to the paper section it came from & any implementation detail the paper skips will be flagged, and not assumed.
open sourcing it -
https://t.co/sSio4JfpIo
Farzapedia, personal wikipedia of Farza, good example following my Wiki LLM tweet.
I really like this approach to personalization in a number of ways, compared to "status quo" of an AI that allegedly gets better the more you use it or something:
1. Explicit. The memory artifact is explicit and navigable (the wiki), you can see exactly what the AI does and does not know and you can inspect and manage this artifact, even if you don't do the direct text writing (the LLM does). The knowledge of you is not implicit and unknown, it's explicit and viewable.
2. Yours. Your data is yours, on your local computer, it's not in some particular AI provider's system without the ability to extract it. You're in control of your information.
3. File over app. The memory here is a simple collection of files in universal formats (images, markdown). This means the data is interoperable: you can use a very large collection of tools/CLIs or whatever you want over this information because it's just files. The agents can apply the entire Unix toolkit over them. They can natively read and understand them. Any kind of data can be imported into files as input, and any kind of interface can be used to view them as the output. E.g. you can use Obsidian to view them or vibe code something of your own. Search "File over app" for an article on this philosophy.
4. BYOAI. You can use whatever AI you want to "plug into" this information - Claude, Codex, OpenCode, whatever. You can even think about taking an open source AI and finetuning it on your wiki - in principle, this AI could "know" you in its weights, not just attend over your data.
So this approach to personalization puts *you* in full control. The data is yours. In Universal formats. Explicit and inspectable. Use whatever AI you want over it, keep the AI companies on their toes! :)
Certainly this is not the simplest way to get an AI to know you - it does require you to manage file directories and so on, but agents also make it quite simple and they can help you a lot. I imagine a number of products might come out to make this all easier, but imo "agent proficiency" is a CORE SKILL of the 21st century. These are extremely powerful tools - they speak English and they do all the computer stuff for you. Try this opportunity to play with one.
Ever wanted to work through a YouTube video with an AI companion. I wanted this too, so I built it with SolveIt!
Now I have a super-easy way to digest YT videos, pull out individual video frames (plus the relevant context) and have a conversation about them with the LLM. 🔥🤯
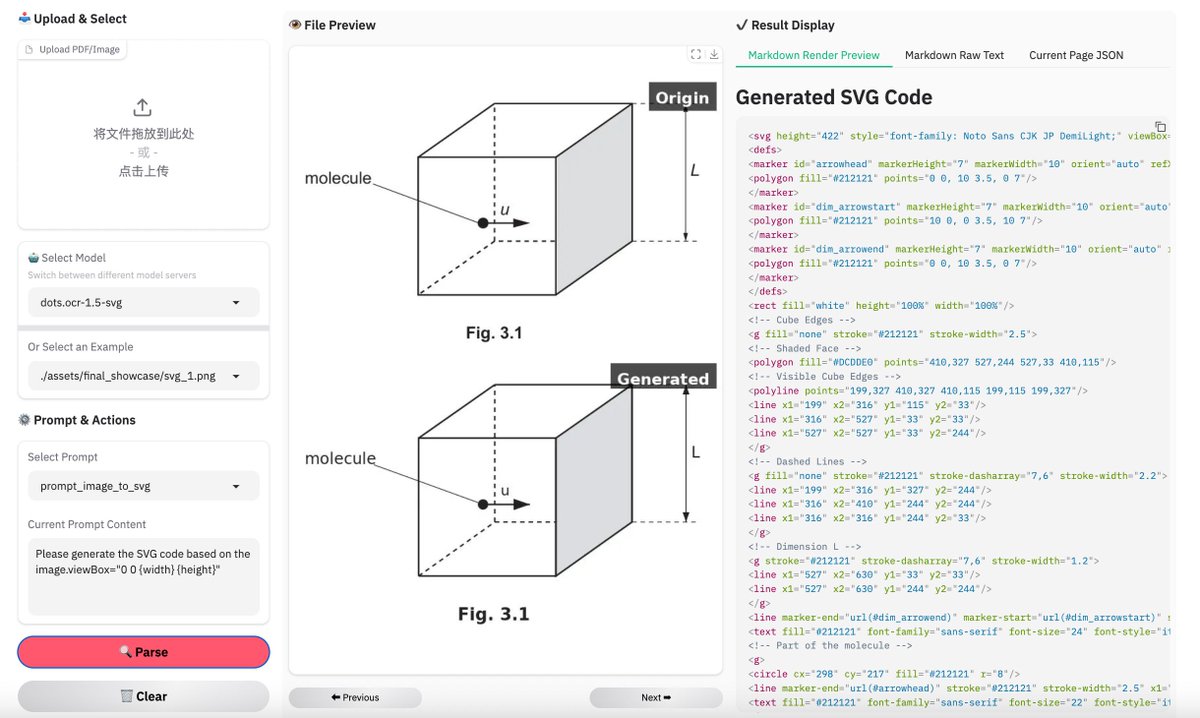
🔥 Meet dots.ocr-1.5: 3B OCR model from Rednote-hilab , SOTA multilingual document parsing, virtually any writing system.
📊 Elo 1089 on olmOCR-Bench, 1157 on XDocParse — above GLM-OCR, and PaddleOCR-VL-1.5
📄 OmniDocBench text edit 0.031, beats Qwen3-VL-235B (0.069) and Gemini 2.5 Pro (0.075)
🎨 SVG code output for charts, diagrams, and chemical formulas
🌐 Web parsing, scene text spotting, and object counting included
⚡ vLLM supported, single GPU
🤖 Model: https://t.co/aTqXUALT5u
🔗 GitHub: https://t.co/nYtek81lm4
�� Demo: https://t.co/q5RBPWpdpS
fastai close reading repo. The repo is primarily designed for use with https://t.co/ovvXlGNmQO, thought it should work with other LLM tools.
If you encounter any issues, feel free to make a pull request so we can make this even better.
https://t.co/Cve7EERYbn
I accidentally discovered how to compress a semester of learning into 48 hours.
A grad student at MIT showed me his NotebookLM setup. I thought he was just organized. Then I watched him pass a qualifying exam on a subject he'd never studied before.
Here's exactly what he did:
First: he didn't upload a textbook.
He uploaded 6 textbooks, 15 research papers, and every lecture transcript he could find on the subject.
Then he asked NotebookLM one question:
"What are the 5 core mental models that every expert in this field shares?"
Not "summarize this." Not "explain this topic."
Mental models. The stuff that takes professors years to develop.
But the next part is what broke my brain.
He followed up with:
"Now show me the 3 places where experts in this field fundamentally disagree, and what each side's strongest argument is."
In 20 minutes he had a map of the entire intellectual landscape of the field:
the debates, the consensus, the open questions.
Most students spend a full semester just figuring out what those debates even are.
Then he did something I've never seen before.
He asked:
"Generate 10 questions that would expose whether someone deeply understands this subject versus someone who just memorized facts."
He spent the next 6 hours answering those questions using the source material. Every wrong answer triggered a follow-up:
"Explain why this is wrong and what I'm missing."
By hour 48, he could hold a conversation with his thesis advisor without getting destroyed.
The tool didn't change. The questions did.
Most people treat NotebookLM like a fancy highlighter.
These students are using it like a private tutor who has read everything ever written on the subject.
The difference between a semester and 48 hours isn't the amount of content.
It's knowing which questions to ask.
You can now fine-tune Qwen3.5 with our free notebook! 🔥
You just need 5GB VRAM to train Qwen3.5-2B LoRA locally!
Unsloth trains Qwen3.5 1.5x faster with 50% less VRAM.
GitHub: https://t.co/2kXqhhvLsb
Guide: https://t.co/JCPGIRo99s
Qwen3.5-4B Colab: https://t.co/2Aj1mZ3f5j
Honestly, WHAT
Here, I asked Codex to port the new SAM3-LiteText model to @huggingface Transformers.
It replaces the heavy text encoder of SAM-3 with a smaller MobileCLIP one from @Apple. The size gets reduced from 3.45GB to 2.12 GB while mostly achieving the same results
- done in 2 hours and 10 prompts!
In January, @jonhoo, @jjgort, and I returned to @MIT_CSAIL to teach Missing Semester, a class on topics missing from most CS programs—tools and techniques that everyone should know, like Bash, Git, CI/CD, and AI tools. Today, we’re releasing the course for free online!
this is still the best guide on Claude Code I've seen that covers basically how you should (and shouldn't) use it. comprehensive, practical, and to-the-point.
https://t.co/1P847kkROo
In collaboration with @AIatMeta, we added support for Pixio in the Transformers library!
It proposes 4 changes to Masked AutoEncoders (MAE), including scaling it to 2B images. It outperforms/matches DINOv3 trained at similar scales
Find the models here: https://t.co/iUE8fQbmOp