I'll be in Denver for #CVPR this week. Happy to make new friends and also catch up with old friends at the conference! Shoot me a message if you are interested in having a coffee chat together.😃
We have an important result to share: if you reduce multiple dense vision tasks into a single RGB-image-prediction task, fine-tuning a strong image generator (in our case Nano Banana Pro) matches or beats all specialized models for monodepth, normals, and semantic segmentation.
vision🍌 is here https://t.co/Ued6GGk4Et
if you got into computer vision the way I did, starting with pixel-level labeling tasks like segmentation, edges, depth, or surface normals, you’ll probably feel the same seeing these results -- something big has quietly shifted, and it’s going to change how we approach these problems for good 🧵
Are we finally witnessing the GPT-3 moment for computer vision? We just dropped Vision Banana 🍌 , a vision foundation model that seamlessly unifies generation and perception by treating all vision tasks as just another image generation problem.
1/N
#googledeepmind#nanobanana
Vision Banana is also advised and supported by Oliver Wang, Saining Xie, Howard Zhou, Kaiming He, Thomas Funkhouser, Jean-Baptiste ALAYRAC, and Radu Soricut.
N/N
Are we finally witnessing the GPT-3 moment for computer vision? We just dropped Vision Banana 🍌 , a vision foundation model that seamlessly unifies generation and perception by treating all vision tasks as just another image generation problem.
1/N
#googledeepmind#nanobanana
Vision Banana achieves state-of-the-art performance under the zero-shot transfer setting across both 2D and 3D vision tasks, proving that generative vision models are the ultimate generalist foundation.
2/N
🚀 Excited to announce Vision Banana 🍌 and our new paper: “Image Generators are Generalist Vision Learners”. We turn Nano Banana Pro into a state-of-the-art visual generation and understanding model.
🖼️ Check out our gallery at https://t.co/CEQJXroPaE
🧵 (1/N) continue ⬇️
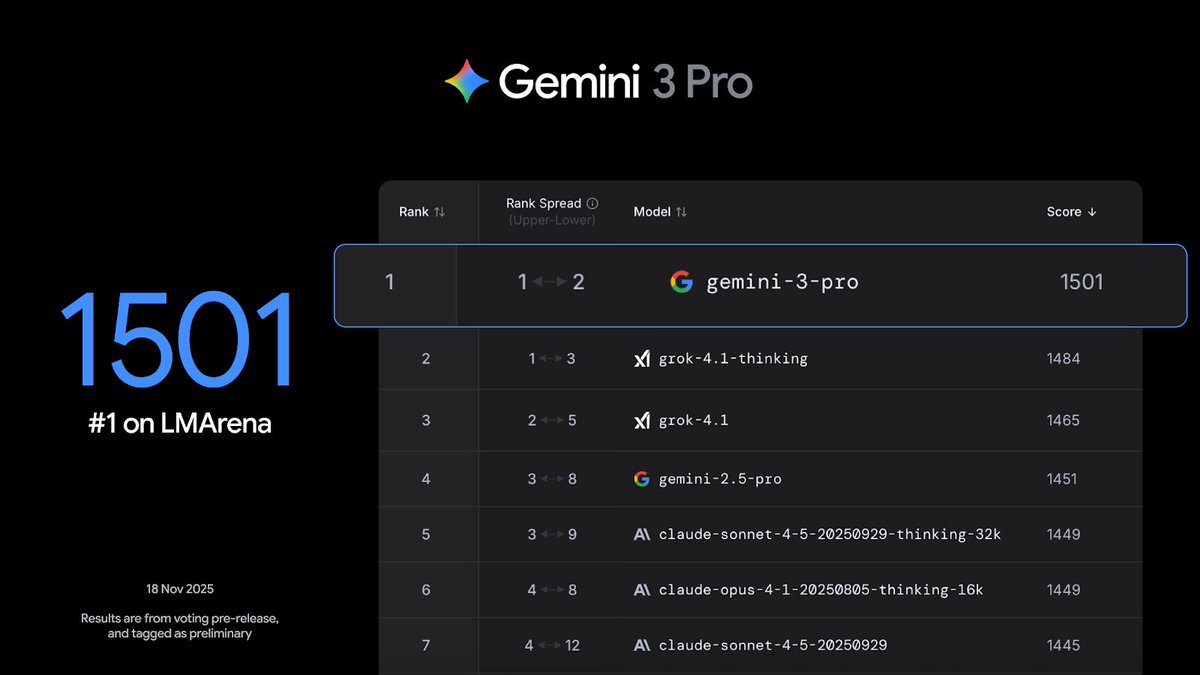
We’ve been intensely cooking Gemini 3 for a while now, and we’re so excited and proud to share the results with you all. Of course it tops the leaderboards, including @arena, HLE, GPQA etc, but beyond the benchmarks it’s been by far my favourite model to use for its style and depth, and what it can do to help with everyday tasks.
What if you could not only watch a generated video, but explore it too? 🌐
Genie 3 is our groundbreaking world model that creates interactive, playable environments from a single text prompt.
From photorealistic landscapes to fantasy realms, the possibilities are endless. 🧵
Project page: https://t.co/0B8KgNQDO2
Code: https://t.co/KiVv4Oy1rw
CPU Demo: https://t.co/SnZgwqhvMV
work done with @RunjiaLi , @philiptorr , @laoreja001 and Siyang Li from University of Oxford and Google DeepMind
I will be presenting our paper "Clip as RNN: Segment Countless Visual Concepts without Training Effort" at @CVPR poster #341, today (June 20th) at 10:30 am. If you're interested in open-vocabulary segmentation and multi-modal learning, please come and chat with me!
After almost a decade, I have made the decision to leave OpenAI. The company’s trajectory has been nothing short of miraculous, and I’m confident that OpenAI will build AGI that is both safe and beneficial under the leadership of @sama, @gdb, @miramurati and now, under the excellent research leadership of @merettm. It was an honor and a privilege to have worked together, and I will miss everyone dearly. So long, and thanks for everything. I am excited for what comes next — a project that is very personally meaningful to me about which I will share details in due time.
Unfortunately, I won't be able to attend ICLR in person due to visa issues. However, if you're keen on using synthetic data for training, I'd love for you to visit our poster Real-fake on Friday morning!