This year, we won 2 Best Paper Awards at #CVPR2026 workshops:
Humanoid Everyday (https://t.co/KBJqdH54Iv) won a Best Paper Award at the Embodied AI Workshop
Ψ0 (https://t.co/lROJkZG3BE) won a Best Paper Award at the 3D-LLM/VLA Workshop
Congratulations to the team!
@zhenyuzhao123, Hongyi Jing, @SonglWei, @Boqian_Li_ , @yuewang314
Thanks @oier_mees and the team for this excellent survey! Proud to see DreamPlan, led by our students @JiaEmily84473 and Weiduo Yuan, featured among so many inspiring works in this space.
DreamPlan fine-tunes VLM planners entirely inside the "imagination" of a learned video world model, sidestepping costly real-robot RL for deformable manipulation.
Huge congrats to Emily and Weiduo on this recognition!
DreamPlan: https://t.co/Il5pFaR2js
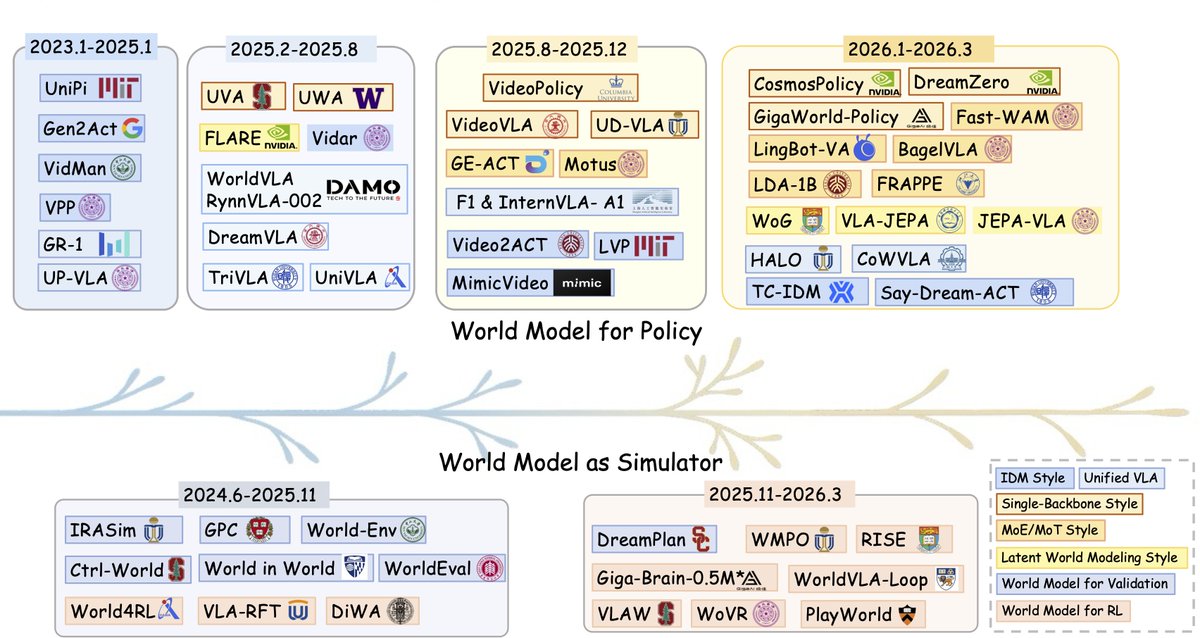
𝐀𝐟𝐭𝐞𝐫 𝐕𝐋𝐀𝐬, 𝐰𝐨𝐫𝐥𝐝 𝐦𝐨𝐝𝐞𝐥𝐬 𝐚𝐫𝐞 𝐛𝐞𝐜𝐨𝐦𝐢𝐧𝐠 𝐭𝐡𝐞 𝐧𝐞𝐱𝐭 𝐛𝐢𝐠 𝐭𝐡𝐢𝐧𝐠 𝐢𝐧 𝐫𝐨𝐛𝐨𝐭 𝐥𝐞𝐚𝐫𝐧𝐢𝐧𝐠 — 𝐚𝐧𝐝 𝐭𝐡𝐞 𝐩𝐚𝐜𝐞 𝐢𝐬 𝐛𝐫𝐞𝐚𝐭𝐡𝐭𝐚𝐤𝐢𝐧𝐠 🚀 𝐒𝐨 𝐰𝐞 𝐰𝐫𝐨𝐭𝐞 𝐚 𝐬𝐮𝐫𝐯𝐞𝐲.
World models, predictive representations of how environments evolve under actions, have become one of the most important building blocks in modern robot learning. They power policy learning, planning, simulation, evaluation and data generation. And with the advent of large-scale generative video models, the field is moving faster than ever.
To help the community keep up, we wrote a comprehensive survey together with @pabbeel, @JitendraMalikCV, @jiajunwu_cs, @du_yilun, @mapo1, @philiptorr, @Jianfei_AI and many others 📖
"World Model for Robot Learning: A Comprehensive Survey"
Paper: https://t.co/puhn9HVDiH
Project: https://t.co/h5sTDOnVLj
@UCBerkeley@Stanford@Harvard@ETH@Microsoft@UniofOxford@NTUsg
Back in 2024, I talked to my labmates about the idea of leveraging massive ego-centric human videos for humanoid manipulation. Now we have made it! Happy to share our humanoid foundation model, Psi-0!
Introducing Ψ₀ (https://t.co/qqH1PiIJS8) — an open foundation model for universal humanoid loco-manipulation.
🏆 Outperforms GR00T N1.6 by 40%+ overall success rate
📉 Uses only ~10% of the pre-training data
📦 Fully open-source: model, data, code, and deployment pipeline
1/10
Introducing the USC Physical Superintelligence (PSI) Lab (https://t.co/nACO3kGxdD). We are rebranding to better reflect our current focus. From here on out, we are tackling one thing: solving robotics and physical intelligence with every model, every bug, and every line of code. And yes, we are hiring at all levels, especially PhDs in this cycle and potential PostDocs who are excited about robotics. We hope you can join us in this journey! 1/9
Full episode dropping soon!
Geeking out with @zhenyuzhao123, Hongyi Jing, Xiawei Liu, @PointsCoder@yuewang314 on Humanoid Everyday: A Comprehensive Robotic Dataset for Open-World Humanoid Manipulation https://t.co/cuj68kR0td
Co-hosted by @micoolcho@chris_j_paxton
I am incredibly honored to receive the NVIDIA Graduate Fellowship this year!
I'd like to express my sincere gratitude to @yuewang314 and @daniel_t_seita for their strongest support during the application.
I'd also like to thank the AV group at @NVIDIAResearch: @drmapavone,@iamborisi,@Boyiliee,@Yuxiao_Chen_,@yan_wang_9, Yurong You, @ChaoweiX, @danfei_xu for hosting me last and next summer. Their guidance has been instrumental to my research journey.
It's inspiring to witness @nvidia's continuous commitment to pioneering the future of Physical AI. 🤖🚀
https://t.co/GwxHOEyPqO
#NVIDIAFellowship #PhysicalAI #Robotics #AutonomousVehicles
"Who has seen the wind? Neither I nor you: But when the leaves hang trembling, the wind is passing through."
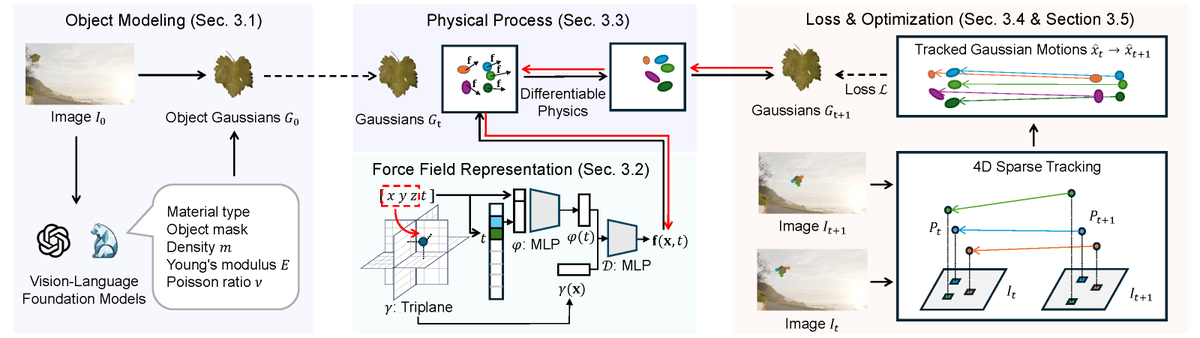
@ScottZhiyuanGao will present our work "Seeing the Wind from a Falling Leaf" at #NeurIPS2025! We teach AI to "see" invisible force fields directly from video using differentiable physics.
Project Page: https://t.co/fvNsGgH3b2
Paper: https://t.co/VHqzjxYBm1
(4/5) Physics-based Video Editing
Once we capture the wind field, we can seamlessly insert new objects into the original video.
These virtual objects interact with the real estimated wind, creating physically consistent simulations.
(3/5) We jointly model Geometry, Physics, & Interactions.
By integrating a differentiable physics simulator, we use backpropagation to minimize the error between simulated and observed motion, effectively "seeing" the force field.
(2/5) Humans have "Intuitive Physics"—we watch a leaf twirl and know the wind speed. But for computer vision, this is incredibly hard.
We propose an end-to-end Inverse Graphics framework that recovers complex, non-rigid force fields (like wind) purely from RGB pixels. No sensors, just vision.