Flow models are a promising alternative to autoregression. But the current standard of evaluating flow models is broken.
The reported 3x improvement in 1024-step PPL since 2023 is closer to 1.1x if you control for sample entropy.
(1/12)
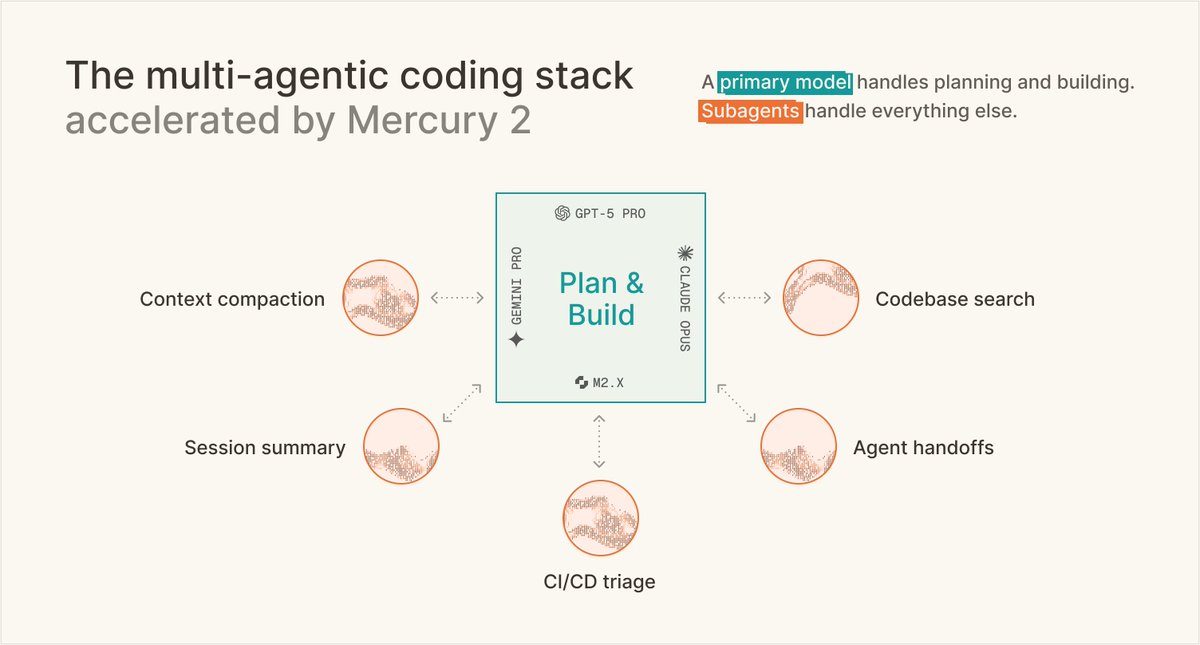
@augmentcode rebuilt their context compaction layer around Mercury 2. 82% latency cut. 90% cost cut. Comparable quality to Opus 4.7. Running in production today.
"We took a counter-intuitive bet. We decoupled summarization entirely, offloading it to Mercury 2 as a dedicated subagent. Mercury 2 is the highly efficient engine powering our most critical workflows."
-@RustagiAnkur & @jm1234567890, Members of Technical Staff at Augment Code
The subagent layer needs the most efficient model. Full methodology and eval setup in the writeup.
https://t.co/LPVTdaMjli
Mercury 2 is live 🚀🚀
The world’s first reasoning diffusion LLM, delivering 5x faster performance than leading speed-optimized LLMs.
Watching the team turn years of research into a real product never gets old, and I’m incredibly proud of what we’ve built.
We’re just getting started on what diffusion can do for language.
The more structure a language has, the faster diffusion can run. Code fits that profile.
Code has plenty of it.
Listen to @justkharbanda on how diffusion unlocks speed for real-world coding workloads.
#Diffusion#AIInfrastructure#DeveloperTools
🧵 LoRA vs full fine-tuning: same performance ≠ same solution.
Our NeurIPS ‘25 paper 🎉shows that LoRA and full fine-tuning, even when equally well fit, learn structurally different solutions and that LoRA forgets less and can be made even better (lesser forgetting) by a simple intervention!
Read on for behavioral differences (forgetting, continual learning) and other analysis!
Paper: https://t.co/XXyQn7uYmZ
(1/7)
Diffusion will obviously work on any bitstream.
With text, since humans read from first word to last, there is just the question of whether the delay to first sentence for diffusion is worth it.
That said, the vast majority of AI workload will be video understanding and generation, so good chance diffusion is the biggest winner overall.
Also means that the ratio of compute to memory bandwidth will increase.
Huge thank you to Pratyusha Sharma (@pratyusha_PS), Jacob Andreas (@jacobandreas), and Antonio Torralba for their collaboration on this work!
See code here: https://t.co/AJPxwKAIFb
🧵 LoRA vs full fine-tuning: same performance ≠ same solution.
Our NeurIPS ‘25 paper 🎉shows that LoRA and full fine-tuning, even when equally well fit, learn structurally different solutions and that LoRA forgets less and can be made even better (lesser forgetting) by a simple intervention!
Read on for behavioral differences (forgetting, continual learning) and other analysis!
Paper: https://t.co/XXyQn7uYmZ
(1/7)
Really cool to see @thinkymachines exploring similar ideas around LoRA recently! Check out our paper to see our other detailed investigations of diverse topics: How do LoRA initialization and learning rate impact learning? What role does LoRA’s alpha parameter and the product-of-matrices parameterization play in training dynamics observed? Plus mathematical explanations of this phenomenon and more!
1/7 Wondered what happens when you permute the layers of a language model? In our recent paper with @tegmark, we swap and delete entire layers to understand how models perform inference - in doing so we see signs of four universal stages of inference!