A group of developers gave away a piece of software for free that does what a $200-a-year premium subscription promises, except it works on every single device you own at once and nobody can ever shut it down.
It is called Pi-hole, and it runs on a computer so small and so cheap it costs less than a single month of most ad-free streaming plans.
Most people fight ads device by device. A blocker on the laptop. A premium account on one app. A different trick for the smart TV that usually fails anyway. It is exhausting and it never fully works.
Pi-hole ends the whole war in one move. It installs in one place and protects everything connected to your home network. Phones, tablets, consoles, speakers, the smart fridge nobody asked for.
The trick is where it sits. Every device on your wifi has to ask for directions before it can load anything, including ads. Pi-hole becomes the thing giving directions. When something asks for the address of an ad server, Pi-hole sends it nowhere.
No app to install on each phone. No login. No company holding your data, because the data never leaves your house.
The ad companies built their entire model on you not understanding the plumbing.
Pi-hole is just someone who understood the plumbing and refused to pay.
Your Chrome is eating 8GB of RAM right now.
If your laptop fan sounds like a jet engine and Chrome freezes every 5 minutes, this is for you.
10 settings that reclaimed 6GB of RAM on my machine.
Steal them 👇
Pixar hired a chef with three Michelin stars to design the dish in Ratatouille. Then they built the scene around the neuroscience of how taste triggers memory, and got Peter O’Toole to deliver one of the great monologues in animation history.
What you call “taste” is mostly smell. When you eat, molecules rise up the back of your throat into your nose. From there, smell takes a unique route. Every other sense (sight, sound, touch, even the actual taste your tongue picks up) gets filtered through a kind of switchboard in your brain first. Smell skips it. The smell heads straight to the parts of your brain that handle memory and emotion. Which is why one bite of food can drop you back into a moment from 30 years ago.
Ratatouille’s director, Brad Bird, built the entire flashback around this. Anton Ego takes one bite, and Pixar zooms the camera through his pupil into a childhood kitchen. The dish itself was Thomas Keller’s. His restaurant The French Laundry in California has three Michelin stars. He took a 1976 recipe by French chef Michel Guérard called confit byaldi (paper-thin vegetables spiraled over a tomato-pepper sauce) and adapted it for the film. Keller even had Pixar’s producer intern in his kitchen for months to get the look right.
Anton Ego is voiced by Peter O’Toole, the lead in Lawrence of Arabia. He was nominated for Best Actor eight times. Never won. He holds the record (tied with Glenn Close) for most nominations without a win, and once called himself the Academy’s “Biggest Loser.” He was 75 when he recorded the Anton Ego monologue. He died six years later, and it became one of his signature performances.
The speech was Brad Bird’s. In the review he writes the next morning, Anton Ego turns on his own profession. Critics risk almost nothing, he writes. They thrive on tearing strangers apart. The only risk that matters, he writes, is defending new talent when no one else will. He ends with the line everyone still quotes: “a great artist can come from anywhere.”
Ratatouille won Best Animated Feature at the 2008 Oscars, plus a Best Original Screenplay nomination on the strength of Bird’s speech. The film grossed $624 million on a $150 million budget.
In 90 seconds, a cartoon rat and a fictional food critic turn that science into something you can feel. Your best memories live in your stomach.
Anthropic loses money on every Claude Design session. That's the entire point.
The newsletter explaining the tool includes one line: "a complete prototype or 10-slide deck costs roughly $2 to $7." A Claude Pro seat is $20 a month. A user hitting Claude Design three times a week is over $20 in compute by week two. Anthropic eats the rest.
This is the WhatsApp playbook.
Facebook paid $19B for WhatsApp in 2014. WhatsApp had $20M in revenue, 55 employees, and 450M monthly users. Facebook was buying the seats. Eleven years later 450M became 3 billion and every conversation runs through Meta's infrastructure.
Anthropic is running the same trade. The Claude Pro seat is a long-duration option. A power user opens Claude in the morning, ships a landing page in 15 minutes, makes a deck after lunch, builds a clickable mockup before EOD. Compute cost that day is $20+. Anthropic ate it. The seat is locked in for another month.
The lock-in compounds. A user who replaces Figma, Canva, Adobe Express, and a freelance designer with one $20 subscription has switching cost approaching infinity. Every additional product Anthropic ships into the seat raises switching cost without raising the price.
OpenAI charges $5 per million input tokens and grows on usage. Anthropic charges $20 a month and grows on engagement. They are running opposite playbooks.
When the dust settles on this AI cycle, the company with the locked-in consumer seat wins. Facebook proved it with WhatsApp. Apple proved it with iCloud. Google proved it with Gmail. Anthropic just opened the trade for design software.
Anthropic shipped three automation surfaces in four weeks.
Most PMs are using the wrong one.
Cowork Scheduled Tasks landed in February. Runs on your machine. Reads your local files. Needs your laptop awake. The right answer when the work needs your hard drive: scanning your downloads folder, editing an Excel, parsing months of Granola transcripts in ~/Documents.
Claude Routines landed April 14. Runs on Anthropic's web infrastructure. Trigger from a schedule, a webhook, or a GitHub event. The tradeoff: no local file access. Pro gets 5 runs/day, Max 15, Team and Enterprise 25.
Claude Managed Agents landed April 8. Runs on Anthropic's infrastructure for your whole team. Each teammate gets their own scoped session, audit trail, and permissions. The catch: an engineer wires the initial connection. Notion, Asana, Sentry, and Rakuten are running this in production today.
Three questions, in order, route you to the right tool:
1. Does the work need your local files? Cowork.
2. Does it need to fire while you're offline? Routines.
3. Does it need to serve more than just you? Managed Agents.
Most PMs running into the "my Cowork task didn't fire because my laptop slept" problem should be on Routines. Most PMs trying to make their team faster by running personal Routines should be on Managed Agents.
Same prompt fits any of them. Only one is right for each job.
Rakuten went from quarterly releases to biweekly using Managed Agents. Critical errors dropped 97%. They deployed one specialist agent per department, each live in under a week.
Asana CTO Amritansh Raghav says Managed Agents "dramatically accelerated" their development of AI Teammates.
The teams who pick the right tool for each job are pulling ahead this quarter. Most PMs aren't.
Full playbook: https://t.co/C80GDh4Ybj
🚨 GOOGLE, META, OPENAI etc. BIG TECH are REJECTING JOB CANDIDATES BEFORE EVEN THEY FINISH TALKING.
50 LLM QUESTIONS. IF YOU CAN'T ANSWER THEM, THE INTERVIEW ENDS BEFORE IT STARTS.
The people passing these interviews are walking out with $200k+ offers.
Someone just LEAKED THE EXACT LLM INTERVIEW QUESTIONS these companies are asking right now.
And the gap between people who know these answers and people who do not is already costing careers.
Here is every category you need to know:
The Basics they always ask first:
↳ How does tokenization work and why does it matter
↳ How does attention actually work inside a transformer
↳ What is a context window and what breaks when it gets too big
↳ What are embeddings and how do they get initialized
↳ How does the model know word order without reading left to right
The fine-tuning questions that eliminate 80% of candidates:
↳ What is LoRA and why is it better than full fine-tuning
↳ What is QLoRA and when do you use it instead
↳ How do you fine-tune a model without making it forget everything it already knows
↳ What is model distillation and why do companies use it
↳ How do you handle vocabularies with millions of possible words
The generation questions most people guess on:
↳ Beam search vs greedy decoding, which one and when
↳ What temperature actually does to model output
↳ The difference between top-k and top-p sampling
↳ Why autoregressive models work differently from masked models
The advanced concepts that separate good from great:
↳ How RAG works and why it beats fine-tuning for factual accuracy
↳ Why Chain-of-Thought prompting makes models dramatically smarter
↳ What Mixture of Experts is and why every frontier model uses it now
↳ Zero-shot vs few-shot learning and when each one wins
The math questions that make people sweat:
↳ Why softmax is used inside attention and not something simpler
↳ What cross-entropy loss actually measures
↳ What KL divergence is and where it shows up in AI training
↳ Why vanishing gradients were destroying transformers and how they fixed it
If you are applying for any AI role in 2026 and you cannot answer at least 40 of these, you are not ready yet.
The full list of 50 questions is worth printing out and going through one by one.
Save this post. Your next interviewer has almost certainly pulled from this exact list.
🚨 In 1979 a 17-year-old was washing dishes to survive. No car. No money. No plan.
Nobody saw it coming.
He had just moved out of his family home to escape chaos.
He was so broke he washed his dishes in the bathtub because his apartment had no kitchen.
Three years later he was earning more than his teachers, his parents, and everyone who told him to be realistic.
Ten years later he was the highest paid speaker on earth.
His name was Tony Robbins. He did not discover a secret.
He discovered that human behavior follows patterns.
And patterns can be changed.
In 50 years he has worked with 4 million people in person.
50 million through his programs.
Presidents. Billionaires. World champions. Broken people rebuilding from nothing.
The patterns he found work every time.
On everyone. Without exception.
I turned Tony Robbins' core human performance principles into 12 Claude prompts.
You describe your situation and it gives you the exact intervention that changes the pattern.
Here are all 12:
No Netflix this Sunday, instead
Spend 50 minutes on this Claude tutorial (You’ll learn how to build Claude Skills from scratch)
Chapters:
0:00 - Full Claude Skills Guide
0:41 - What are Claude Skills
10:16 - Using Claude Cowork
11:12 - What are Connectors
12:52 - Claude’s Skill Creator
14:07 - The First Claude Skill Idea
14:55 - Installing DBS Framework
15:51 - Creating a Skill using Claude
20:00 - Testing the Skills on Claude
22:10 - Reviewing Skill Evaluations
23:12 - First Claude Skill Complete
24:00 - Using the Claude Skill
25:35 - Complex Claude Skill Idea
27:00 - Enabling Gamma
27:35 - Creating the Complex Claude Skill
29:14 - Answering Claude’s Questions
30:59 - Adding Brand Guide to References
32:05 - Reviewing Skill Draft
32:46 - Testing New Claude Skill
35:40 - Editing the Claude Skill
36:50 - Reviewing Skill Edits
38:10 - Finalizing the Claude Skill
39:30 - Using the Presentation Skill Live
42:15 - Scheduling a Claude Skill
43:55 - Organizing Skills in Departments
45:28 - The Best Way to Master Claude Skills
ANDREJ KARPATHY COULD HAVE CHARGED $2,000 FOR THIS.
he put it on YouTube for free.
3 hours.
the full picture of how LLMs actually work from the ground up.
not "here's how to write better prompts."
not "here's my AI workflow."
tokenization.
neural network internals.
why hallucinations happen.
tool use.
reinforcement learning.
RLHF.
DeepSeek.
AlphaGo.
the engineers who understand this build things the ones who only use the tools cannot even imagine.
most people will scroll past this.
watch the 3 hours.
the gap between you and the people who did is not 3 hours.
it is every single thing those 3 hours quietly unlock for the rest of your career.
follow @cyrilXBT if you want to know which resources actually matter.
The math on a single PM mockup just dropped from $1,500-6,000 down to $2-7. Most PMs haven't repriced their workflow yet.
Old path: PM writes a brief, waits 3-7 days for a designer slot, designer spends 6-15 hours building it. Loaded cost lands at $1,500-6,000 depending on team.
New path: PM opens https://t.co/1l65nzaBLo, attaches a screenshot, types a prompt, clicks generate. 12 minutes. $2-7 in tokens. Hands off to Claude Code with design intent embedded.
That's roughly 500x cost compression and 50x speed compression. Run the same math on decks. An investor-grade deck from a design agency runs $5,000-15,000 over 2-3 weeks. Claude Design produces it in 8 minutes for $5-10. Brilliant cut complex pages from 20+ prompts in competing tools to 2 prompts in Claude Design. Datadog reports going from rough idea to working prototype before anyone leaves the meeting room.
Two SaaS categories just collapsed into one workflow. AI prototyping (Figma Make, Lovable, v0, Bolt, Magic Patterns) and presentations (Figma Slides, Gamma, https://t.co/JTgqzJ7mhC) both got repriced in one product launch, with brand applied automatically from your codebase. Figma keeps the design system. Claude takes the first-draft work.
Aakash's piece walks the exact setup, including the one-hour design system config that compounds across every prototype after.
The PMs running this workflow this week walk into Q4 with six months of brand-consistent prototypes compounding behind them. Everyone else is still drafting Slack messages to a designer they cannot reach.
That gap widens every Monday.
There's a cognitive science concept that explains why every PM spec gets misinterpreted, and why shipping code is the only fix.
It's called the curse of knowledge. Once you understand something, your brain physically cannot simulate what it's like to not understand it. Elizabeth Newton's 1990 Stanford experiment proved this: tappers who tapped out a song predicted listeners would recognize it 50% of the time. Actual recognition rate was 2.5%. The tappers could hear the melody in their heads. The listeners heard random knocking.
Every PRD ever written has this problem baked in.
The PM hears the melody. They know what the feature should feel like, how users will navigate it, where the edge cases live. They write it down. The engineer reads it and hears knocking. They fill the gaps with their own assumptions. Two weeks later, both sides are frustrated and neither understands why.
Text is a lossy compression format for product intent. You can write 12 pages and still lose 30% of the signal in translation. You can add wireframes and lose 20%. You can add a Loom walkthrough and lose 10%.
Code loses 0%.
A working prototype is the only artifact that transfers product intent without compression loss. The engineer opens it, runs it, and sees exactly what the PM means. The conversation shifts from "what do you mean by X" to "here's how I'd improve X." That's a fundamentally different starting point.
AI coding tools didn't just give PMs a new skill. They gave PMs their first lossless communication channel with engineering.
A must read for anyone interested in building practical AI systems in 2026:
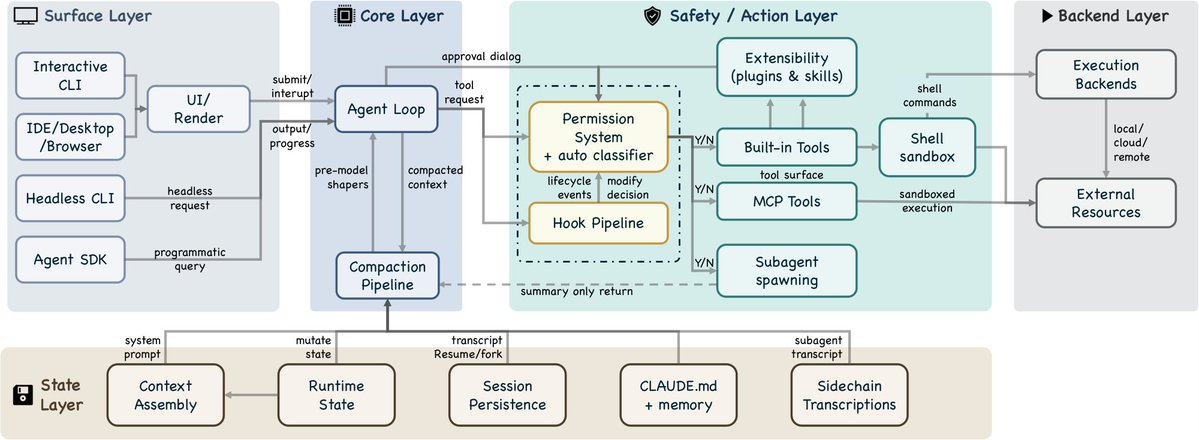
Dive into Claude Code: The Design Space of Today's and Future AI Agent Systems
The paper explains the architecture of a modern production-grade AI agent system (Claude Code) by analyzing its source code. This is what they call a "harness" of an agentic coding system.
Learn by reading with an AI tutor: https://t.co/sailmnkDcR
PDF: https://t.co/Jvl4HRMU4y
If I had to land a $200K AI engineer job in 90 days, I would not get a degree.
I would master these 10 GitHub repos.
1. awesome-llm-apps
The production AI playbook. RAG, agents, multimodal apps, all in working code. 106K+ stars.
Repo → https://t.co/oXrD5A8K6a
2. LangChain
The foundational framework. Used in production by Klarna, Replit, Elastic, and most AI startups in 2026.
Repo → https://t.co/alIh6rDDIu
3. LangGraph
The orchestration layer powering production agents. The skill on every senior AI engineer job description.
Repo → https://t.co/bzVBn9uecV
4. CrewAI
Multi-agent coordination. The framework most Fortune 500 teams reach for first.
Repo → https://t.co/0xohE065sD
5. Ollama
Run any open-source LLM on your own machine. The fastest way to learn how models actually work.
Repo → https://t.co/gyZhUdzsnZ
6. awesome-mcp-servers
MCP is the standard every major AI lab adopted in 2026. Knowing it puts you ahead of 99% of engineers.
Repo → https://t.co/ejVOgkRJDX
7. Qdrant
The vector database used for production RAG at scale. Embeddings and semantic search are non-negotiable for AI roles.
Repo → https://t.co/ziSSXW2dzZ
8. AI-Agents-for-Beginners
Microsoft's free 12-lesson course on building agents. Real code, real exercises, real prep.
Repo → https://t.co/7dNsDw6bTj
9. system-design-primer
Production AI is system design. The repo FAANG engineers use to prep for interviews.
Repo → https://t.co/AypwqcL1Xz
10. awesome-claude-code
The playbook for the tool now used inside FAANG, OpenAI, Anthropic, and most YC startups.
Repo → https://t.co/VhNjDoz7YM
Here's the wildest part:
A $200K AI engineer in 2026 isn't paid for a degree.
They are paid for what these 10 repos teach.
The market doesn't care where you learned it. It only cares if you can ship.
90 days. 10 repos. One portfolio that proves you can do the work.
That's it. That's the whole game.
Save this before you forget.
100% free. 100% open source.
Chris Camillo says 15 people in his network called him last week ready to quit their jobs. All of them had just set up a $650 Mac Mini.
The callers told him the same thing: they can start any business in the world and have it running in 48 hours.
Stop and look at what just collapsed.
For 40 years, the gate on starting a software company was time. Every other constraint got demolished. Time held.
In 2005 you needed servers, an office, and a couple engineers. Paul Graham's whole thesis at YC was that AWS had dropped the capital hurdle to $20K. Before 2006, you needed Series A money to buy enough servers to ship. After 2006, you needed a credit card.
But v1 still took 6 to 12 months. Which meant 12 to 18 months of savings. Which meant only people with VC-scale runway could actually quit.
That gate is gone.
Claude Code compresses v1 from 6 months to a weekend. First paying customer in week 2. Runway requirement drops from 18 months to 3. Six figures to four. The math on quitting your job now matches the math on your emergency fund.
This is the first time in the history of software that has ever been true.
It became true this year. Fifteen people from one guy's personal network called in ONE WEEK. Now picture that across every software-literate professional in the US. The PMs wondering if their roadmaps matter. The analysts still writing SQL at 11pm.
The dot-com infrastructure collapse built Airbnb, Stripe, Uber. The SaaS collapse built Notion, Figma, Linear. The runway collapse is going to build a hundred of them. All at once. By the end of 2026.
Chris is right. If you're young and you've been waiting for the opening, stop waiting.
You just got it.
Two types of product teams exist right now and the gap between them is getting violent.
Team A runs the traditional loop. PM writes a PRD. Designer creates mockups. Engineers estimate, build, deliver. PM reviews and files change requests. Engineers rebuild. Total cycle time for a meaningful feature: 4-6 weeks. The PM's job is to write documents and attend meetings.
Team B has a PM who ships code. They prototype in Claude Code before the sprint starts. Engineers receive a working reference instead of a spec. Design reviews happen on functional software. The PM catches their own mistakes before anyone else wastes time on them. Total cycle: 3-5 days for the same feature.
Same talent. Same market. Same tools available to both. The only variable is whether the PM learned to ship code.
The compounding is where this gets brutal. Team B runs 8-10x more experiments per quarter. More experiments means faster learning. Faster learning means better product intuition. Better intuition means sharper prioritization. Within 12 months, Team B's PM has run more experiments than Team A's PM will run in five years.
That gap doesn't close. It widens every quarter because the learning rate itself accelerates.
Hiring managers figured this out already. "Build a working prototype" is showing up in PM interview loops at Google, Anthropic, and Meta. They're not testing coding ability. They're sorting candidates into Team A or Team B before making an offer.
ANDREJ KARPATHY JUST DROPPED THE KIND OF 2 HOUR COURSE PEOPLE COULD BUILD ENTIRE CAREERS ON.
A free deep dive from one of the few people who actually understands this stuff at the highest level.
Most PMs prepping for AI roles are studying the wrong thing.
They're learning prompt engineering, memorizing RAG architectures, reading agent framework docs. All useful. None of it is what the $1M+ AI PM interview actually tests.
The hardest round at top AI companies is system design. Given a real business problem like customer churn, architect the complete AI system that solves it end to end.
Three pillars. Almost every candidate gets two of them wrong.
Data. Which specific signals, weighted how. Call transcripts, app usage, network status, competitor connectivity, travel patterns. Bucketed into churn risk tiers that route to different agent behaviors. Plus a human-escalation retention offer for red-bucket users the agent can't save.
Model. Commodity layer. Most candidates spend 70% of their answer here. It's worth 20%.
Memory. The differentiator. Episodic versus session, and knowing the tradeoff is the actual test. Session memory (this conversation) is obvious.
Episodic memory (every past customer care interaction this user has ever had) is what separates a generic bot from a system that sounds like it actually knows the customer. Most candidates say "store everything" and lose points. The right answer is knowing what to drop.
The candidate in this mock got the memory tradeoff right in real time. That's rare. I've watched senior PMs from FAANG miss it.
The ones passing $1M+ AI PM rounds have one thing in common. They've already done this work on a real product. Scoped the feature, mapped the signals, made the memory tradeoffs, shipped something.
The model is the commodity. The system is the moat.