I've come across this post in the afternoon and quickly wanted to turn this into something useful for me and the SAP IS-U community. @karpathy explained it as a personal knowledge base, but I thought about applying the exact same concept for public use.
SAP documentation is notoriously dense and hard to navigate. So instead of doing it by hand, I just treated LLMs exactly how Andrej described—as tools for manipulating knowledge instead of just writing code.
Here is what I did:
First, data ingest. I couldn't just copy-paste everything, so I had an AI agent use browser automation (@antigravity) to click through SAP learning portal and scrape the text from 40+ different pages and dump it all into a raw folder.
Next was the "compilation" phase. I pointed an LLM at that messy raw data and had it act as the editor. It read through the courses, extracted about 110 core "Concepts" (things like Clearing Core or Budget Billing), and wrote out clean, individual markdown files for each one.
The coolest part was the linking. A wiki isn't useful if it's just isolated text files. Instead of linking things manually, I asked the LLM to write a quick Node script to act as a "linter" over the whole folder. It scanned every markdown file, found every time a concept was mentioned, and automatically linked them all together. It even generated an Obsidian-style "Referenced By" section at the bottom of every page.
Finally, the output. I just dropped the structured markdown folder into a standard Next.js (Nextra) template so it actually looks and functions like a real documentation site with a search bar, and pushed it to @vercel .
I barely wrote any of the content manually. The LLM scraped the data, structured the wiki, built the link graph, and I just orchestrated it.
It's actually crazy how well this workflow works. You can check out the public @SAP IS-U knowledge base I built today right here: https://t.co/70vvYq9Bem
Note: This is not comprehensive. Developed as a POC.
LLM Knowledge Bases
Something I'm finding very useful recently: using LLMs to build personal knowledge bases for various topics of research interest. In this way, a large fraction of my recent token throughput is going less into manipulating code, and more into manipulating knowledge (stored as markdown and images). The latest LLMs are quite good at it. So:
Data ingest:
I index source documents (articles, papers, repos, datasets, images, etc.) into a raw/ directory, then I use an LLM to incrementally "compile" a wiki, which is just a collection of .md files in a directory structure. The wiki includes summaries of all the data in raw/, backlinks, and then it categorizes data into concepts, writes articles for them, and links them all. To convert web articles into .md files I like to use the Obsidian Web Clipper extension, and then I also use a hotkey to download all the related images to local so that my LLM can easily reference them.
IDE:
I use Obsidian as the IDE "frontend" where I can view the raw data, the the compiled wiki, and the derived visualizations. Important to note that the LLM writes and maintains all of the data of the wiki, I rarely touch it directly. I've played with a few Obsidian plugins to render and view data in other ways (e.g. Marp for slides).
Q&A:
Where things get interesting is that once your wiki is big enough (e.g. mine on some recent research is ~100 articles and ~400K words), you can ask your LLM agent all kinds of complex questions against the wiki, and it will go off, research the answers, etc. I thought I had to reach for fancy RAG, but the LLM has been pretty good about auto-maintaining index files and brief summaries of all the documents and it reads all the important related data fairly easily at this ~small scale.
Output:
Instead of getting answers in text/terminal, I like to have it render markdown files for me, or slide shows (Marp format), or matplotlib images, all of which I then view again in Obsidian. You can imagine many other visual output formats depending on the query. Often, I end up "filing" the outputs back into the wiki to enhance it for further queries. So my own explorations and queries always "add up" in the knowledge base.
Linting:
I've run some LLM "health checks" over the wiki to e.g. find inconsistent data, impute missing data (with web searchers), find interesting connections for new article candidates, etc., to incrementally clean up the wiki and enhance its overall data integrity. The LLMs are quite good at suggesting further questions to ask and look into.
Extra tools:
I find myself developing additional tools to process the data, e.g. I vibe coded a small and naive search engine over the wiki, which I both use directly (in a web ui), but more often I want to hand it off to an LLM via CLI as a tool for larger queries.
Further explorations:
As the repo grows, the natural desire is to also think about synthetic data generation + finetuning to have your LLM "know" the data in its weights instead of just context windows.
TLDR: raw data from a given number of sources is collected, then compiled by an LLM into a .md wiki, then operated on by various CLIs by the LLM to do Q&A and to incrementally enhance the wiki, and all of it viewable in Obsidian. You rarely ever write or edit the wiki manually, it's the domain of the LLM. I think there is room here for an incredible new product instead of a hacky collection of scripts.
@Forbes@elonmusk Indian and Chinese immigrants are the most successful and great contributors to the USA. Respect to the US for giving real opportunity to talent and hard work — no matter the origin.
We’re reimagining a 50-year-old interface - the mouse pointer - with AI. 🖱️
These experimental demos show how people can intuitively direct Gemini on their screens using motion, speech, and natural shorthand to get things done 🧵
THE FUTURE IS REALLY HERE... and as Dr. JP Sir rightly says, "Skill Orientation is the need of the hour." 🚀
Grateful for his insights on why the youth must move beyond degrees to focus on real-world capabilities. This is exactly why I wrote Hello Future Skills—to provide the roadmap for this transition. 📖
@JP_LOKSATTA
Let’s empower the next generation together!
Order your copy from https://t.co/yGcXAsDOgx -- All proceeds go to a non-profit to spread the cause.🇮🇳
#FutureSkills #SkillHaiTohKalHai #VijayIndian #DrJP #SkillDevelopment #Reliance #PeaceOverWar #SkillUp
@NSDCIndia@fsprimeofficial@UN@wef@FDR_INDIA
Today’s Terafab announcement reminded me of when I first met Elon:
I watched him do 10 hours of xAI reviews without a break—and then he ate a $9 Doordash burrito and kept going until 2am.
He could do anything right now, but instead he spends every waking minute earnestly working on the most ambitious project imaginable to advance humanity.
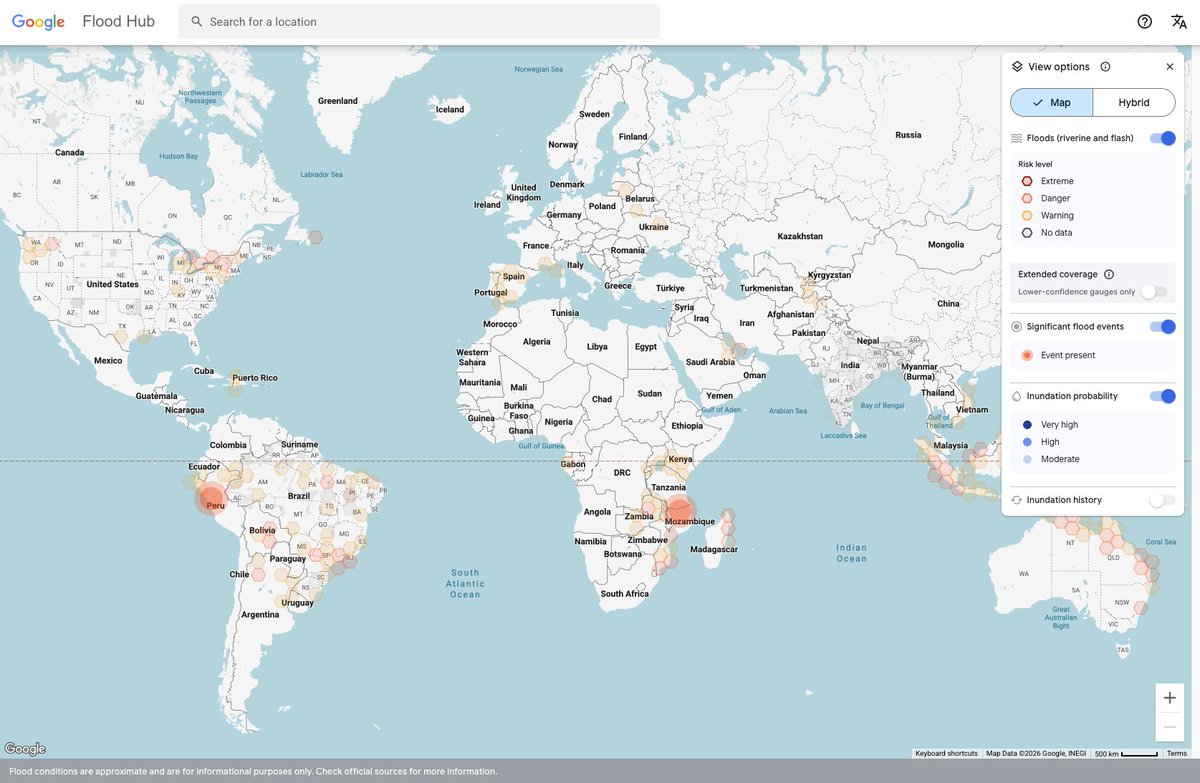
We trained a new flood forecasting model designed to predict flash floods in urban areas up to 24 hours in advance.
To help address a flash floods data gap, we created Groundsource: a new AI methodology using Gemini to identify 2.6M+ historical events across 150+ countries.
We’re open-sourcing this dataset to advance global research, and urban flash flood forecasts are live now in Flood Hub to help communities stay safe.
@madebygoogle Battery is down to 14% overnight. My Pixel 10 Pro was charged to 100% around 10 P.M. last night. Now it's down to 14% with only ~100 minutes of screen time. System apps consumed 66% of the battery! Is this a known issue being tracked to be fixed?
Yesterday, I stood alone in Delhi with a simple citizen message to our lawmakers: “Honourable Parliamentarians, you are the highest authority of our nation. Stop disruptions; start delivering and progressing India collaboratively. #India#WinterSession#Parliament#TaxpayersMoney
Love seeing all the isometric 3D trends using Nano Banana Pro and pulling in live data - thought I’d give it a try myself in honor of the Ashes second test underway. Thanks to @dotey and @TechieBySA for the inspiration.
@grok @calculator_iv @kritesh_rocks Seems you are tricked. https://t.co/yYw8ngX94J redirecting to https://t.co/bu5GzDVequ. My question was who registered the perplexity dot in domain.
Frustrated US farmer, quoted in the link in comment:
“Seed, chemicals or fertilizer, it’s all in the hands of a few companies that are the only game in town. You want to fix farming? Start a federal investigation on those big companies. Booming quarterly earnings and big stock dividends make no sense when farmers can’t pinch a penny.”
The trade issue between US and India is partly also a conflict between the US model that pits farmers against BigAg vs the large number of small farmers in India. We must note that the US BigAg model is not even working for American farmers, nor is it leading to better health for Americans.
That is why I am so glad our Prime Minister took a very strong stand on this issue. It is the future of our food and our well being at risk.
If we want good health for humans and the soil, we need our small farmers to do well. Financialized corporate model of BigAg cannot ensure this. The "productivity gains" are illusory.
On a related note, we are starting to see a consolidation of hospitals, driven by private equity, in India - again the US model, and again a model that is not even working for Americans.
Article below.