@joshavant V2: use-case-specific fine-tuning and compiler-based compute optimization (original weights + optional use-case quantization).
In the beta, we can already host your inference with monthly invoicing. Would that work for you?
@joshavant Hello Josh, thanks for the interest in trying the platform.
It’s currently in beta and we’re aiming to launch in early April.
V1 (launch): credit card payments, dedicated deployments, serverless inference, and observability.
Three days ago we hit 10B tokens/day on @OpenRouter - in <1 month since launch. 🚀
The jump from ~2B → 10B overnight is the clearest signal: real workloads, real demand.
Proud of the whole team. And yes… we’re looking for more GPUs 👀
MiniMax M2.5 is live on @OpenRouter via Inceptron - the first EU provider to ship it, and currently #1 on price 🥇(live within 100 hours of release).
Why M2.5 matters (from @MiniMax_AI):
-80.2% SWE-Bench Verified (coding)
-76.8% BFCL (tool-calling)
-37% faster on complex tasks
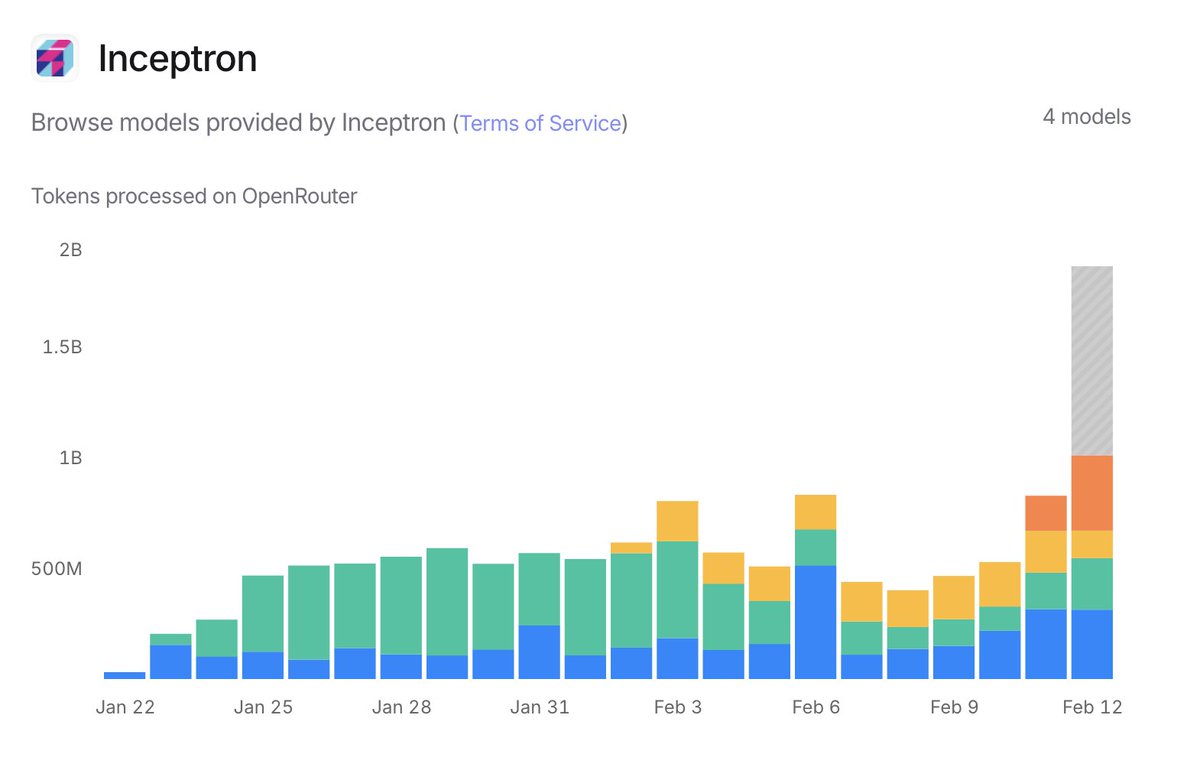
Today is the day we reached the milestone of over 1B tokens a day processed!
We launched in OpenRouter three weeks ago as the only Swedish provider 🇸🇪 and the second AI Studio in Europe.
Kudos to the team for pushing the limits every day 🙌
Exciting news! 🙌
The Kimi K2 Thinking model is now live on Inceptron.
Check out this model and more on our website: https://t.co/hTbYnMc7VP
#Inceptron#KimiK2Thinking#ModelAI
Do you want the best deal for model AI’s?
Work closely with us and receive all the benefits. We offer Nvidia H200 141 GB at $5/hr - it only charges for the time the instance runs!
No hidden fees; just simple, transparent, and for real usage.
https://t.co/1JFgm5ldCh
#inceptron
Try Minimax M2 now on our platform. The hottest AI model optimized for coding and agentic workloads, delivering remarkable speed and intelligence.
Explore our website to find the best model for your needs at the best prices.
https://t.co/hTbYnMc7VP
#ai#inceptron#minimaxm2