Some ideas for what comes next, May 2026
Gemini Flash 3.5, Mythos, open-closed balance, America's open-source surge, emerging power struggles and more.
https://t.co/l7H6go2JbG
Latest open artifacts (#21): Open model bonanza! Gemma 4, DeepSeek V4, Kimi K2.6, MiMo 2.5, GLM-5.1 & others. On CAISI's V4 assessment.
An eventful month with one flagship release after another
https://t.co/6ifAQiKirf
Reading today's open-closed performance gap
The complex factors that determine the single evaluation number so many focus on. Plus, how this changes in the future.
https://t.co/16pPfiEoxg
New video! Talking through my 10+ open model pieces from early 2026 and how they fit together. They're all trying to figure out where open models go next.
https://t.co/Y6q976ZPiJ
One of my key strategies with Interconnects is to develop the practice of making my work obviously compelling to a wider audience, keeping them hooked over time and wondering what I'm up to, etc.
It pays off so much on the downstream influence of your work to have direct audiences for it. These types of articles are a pure grind, but the directly convert hard earned reputation into success for projects.
Many people, especially academics, too far too many projects and invest too little in each. The amount of work just on distributing each project is fairly high. If you don't work on distributing it, don't expect to get new readers.
It'll seem like a lot of your audience already knows everything if you've mentioned it once, but repetition is key. People are busy, algorithmic feeds are fickle, and people don't remember points/brands until they've seen it many times.
Do the work (and read my post contextualizing why all my recent efforts are important)!
Excited to launch the accompanying free RLHF Course for my book. To kick it off, I've released:
- Welcome video
- Lecture 1: Overview of RLHF & Post-training
- Lecture 2: IFT, Reward Models, Rejection Sampling
- Lecture 3: RL Math
- Lecture 4: RL Implementation
I'm going to add question & answer videos throughout the lecture to go deeper on topics that need it, and potentially cover some topics that are too recent and in flux to go in print. I expect 10-15 videos in total over the next few months.
At the same time, development around the code for the book is picking up. It's a great time to build the foundation for post-training methods.
YT playlist and course landing page below.
1. dont fall for anti open model fearmongering, but
2. acknowledge that AI capabilities are proceeding fast, and eventually there may be a reason to be more careful with open weight models
I don't think Mythos is that trigger, but I'm not 100% confident
https://t.co/tbKdQlF22j
My book, Reinforcement Learning from Human Feedback, is wrapping up and going into final production (copyediting, making pretty, formatting, etc.). Shipping to you in 1-2 months!
It's a wonderful project to create a foundation of knowledge for the research communities that I love and operate in. It’s the book I wish I had when starting on my LLM journey about 3 years ago.
The book’s deepest cut is on core reinforcement learning methods, intuitons, and implementations for LLMs. These don’t live in isolation, and it’s presented in the broader context of post-training methods and unsolved problems in RLHF. A nice balance of depth and breadth.
I’m always asked about the title, and I am staying firm that this is THE book documenting the organization of the field of RLHF. Any other topic is too dynamic, where writing a book today would be immediately outdated. RLHF is largely being overshadowed by lots of other developments in AI, but will always be around and at the forefront of human-AI interactions. The topic deserves coverage in depth and this platform.
Thank you for all your support. More projects related to the book being announced soon 🎥 I'm excited to reconnect with the community through in-person book events this summer and fall.
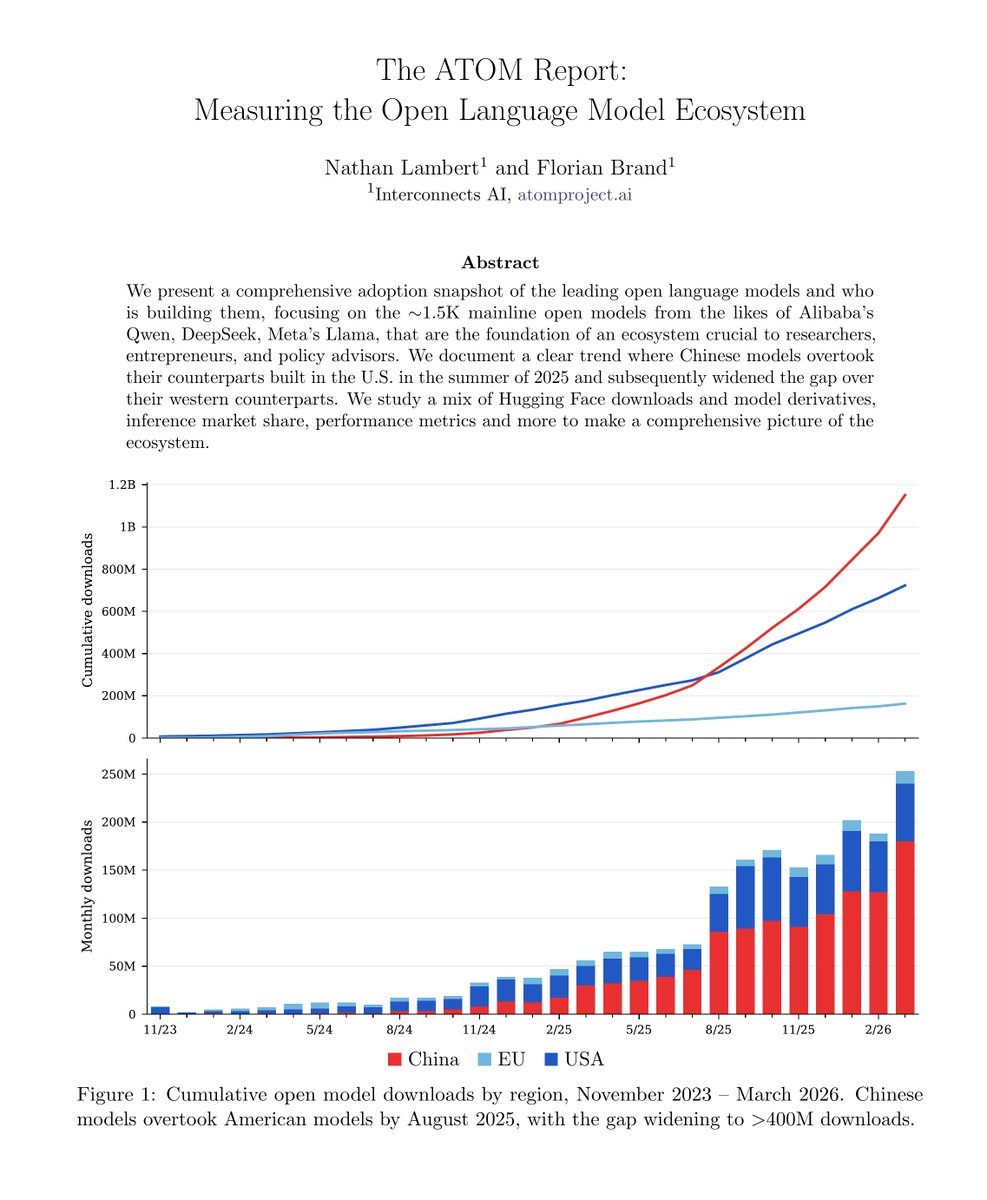
New report with @xeophon is out with the latest open model adoption data we have gathered for Interconnects & The ATOM Project. At the surface level, we can see Chinese models continuing to accelerate in adoption.
The report details much more.
1. We manually curate ~1.5K of the most important language models, creating a specific set of models to focus our analysis on (excludes embedding models, local inference models like MLX/GGUF, etc to have accurate download rankings).
2. Studying other adoption metrics, such as derivative models and inference share on OpenRouter, to show how they correlate with downloads, while often sifted in time. China has a strong lead here too.
3. Better classification of downloads across model sizes. Large models still are the models where Qwen is least competitive, relative to other model builders.
4. Expansion of our Relative Adoption Metric (RAM) to show standout recent models (we'll check Gemma 4 on Friday); Qwen 3.5, Nemontron 3, Kimi K2.5, all showing very strong adoption.
Overall, this is another step towards formalizing and making public better data on the open language model ecosystem, so the community can better understand the impact and trends of its adoption. More on this soon!
Gemma 4 looks great on paper, just what many people need, but mostly I'm focused on the questions around what makes an open model succeed in the long term.
We desperately need to build a field of research on "what makes a finetunable model" if we want the open model economy to succeed. Too much of that research happens behind closed doors of companies.
Plus, 240 days after The ATOM Project was released, I share reflections on the recovery of American models, and what that means for the next phase.
https://t.co/Kiex6catdp