🎉 Day-0 vLLM support for Intern-S2-Preview!
Congrats to the @intern_lm team — an open-source scientific multimodal foundation model, with a first take on material crystal structure generation alongside general capabilities.
📖 https://t.co/B6kd1vV3uV
🚀 Day-0 SGLang support is live for Intern-S2-Preview! This is a 35B scientific multimodal foundation model from @intern_lm
1️⃣ Scientific task scaling: hundreds of pro tasks from pre-train to RL; first open-source model w/ material crystal structure generation
2️⃣ Stronger agents: big gains on scientific agent benchmarks
3️⃣ Efficient RL: shared-weight MTP + CoT compression for faster, leaner inference
Try it on SGLang now 👇
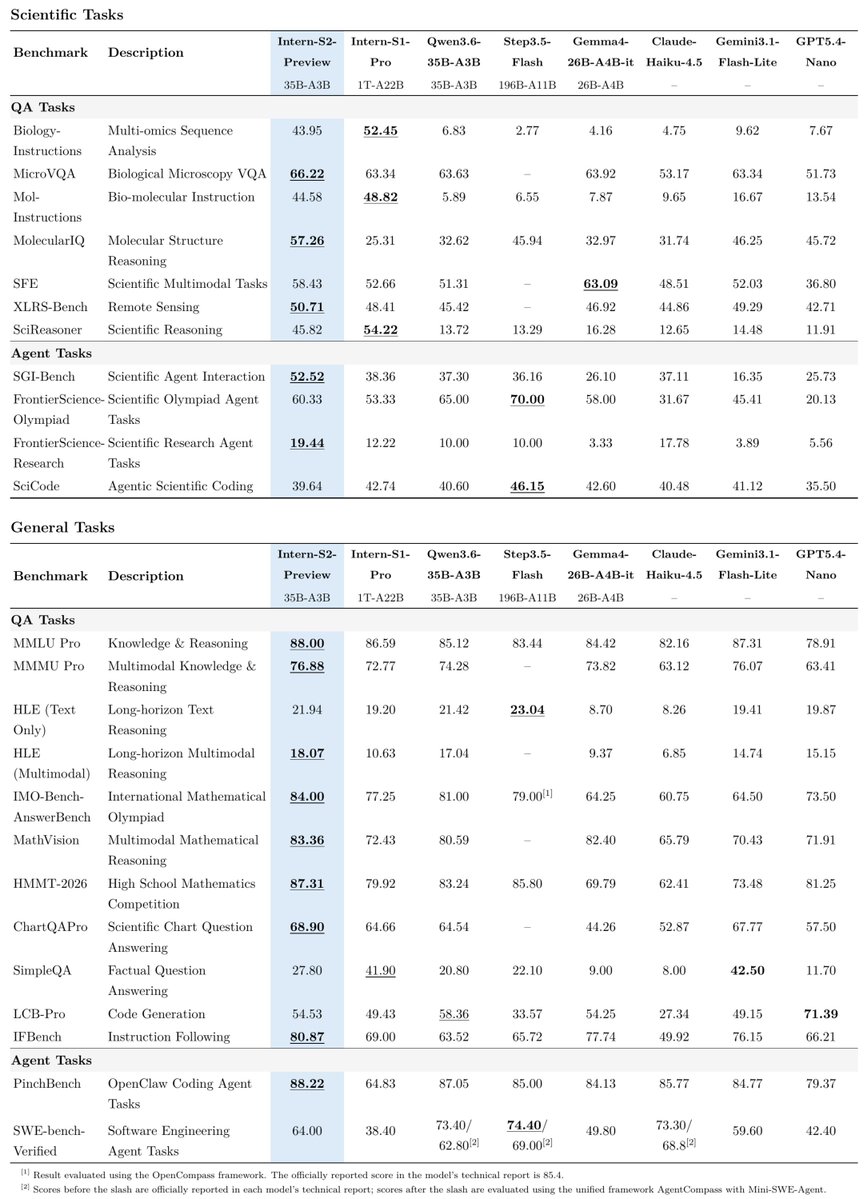
🥳Introducing Intern-S2-Preview, an efficient 35B scientific multimodal foundation model.
1⃣Delivers performance comparable to the trillion-scale Intern-S1-Pro on core scientific tasks.
2⃣The first open-source model with material crystal structure generation capabilities and strong general capabilities.
3⃣Significantly stronger scientific agent capabilities on multiple benchmarks.
4⃣Improves MTP acceptance rate and token generation speed via shared-weight MTP + KL loss.
5⃣CoT compression shortens responses while preserving strong reasoning , improving both performance and efficiency.
🥰Now supported by vLLM (@vllm_project) and SGLang ( @lmsysorg ) — with more ecosystem integrations on the way.
🤗Model:
@huggingface
https://t.co/dHXpP56xWk
@ModelScope2022
https://t.co/zjfW2B0fWq
🤗GitHub:
https://t.co/ImW2TzgxRh
🤗Try it now at:
https://t.co/OpebPDIv5x
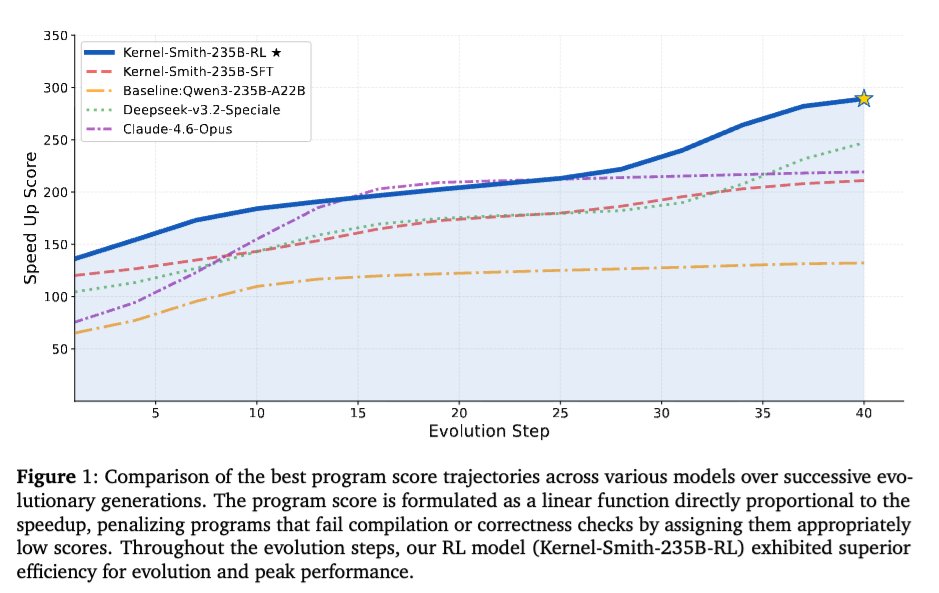
🔥Introducing Kernel-Smith, a framework for high-performance GPU kernel and operator generation.
1⃣Combines a stable evaluation-driven evolutionary agent with an evolution-oriented post-training recipe.
2⃣Outperforms Gemini-3.0-pro & Claude-4.6-opus on Kernel-Bench.
3⃣Optimized kernels are already merged into SGLang @lmsysorg and LMDeploy.
😉Tech report:
https://t.co/xXKMhL0PE2
😉Try it now at:
https://t.co/EMDmhd6HWN
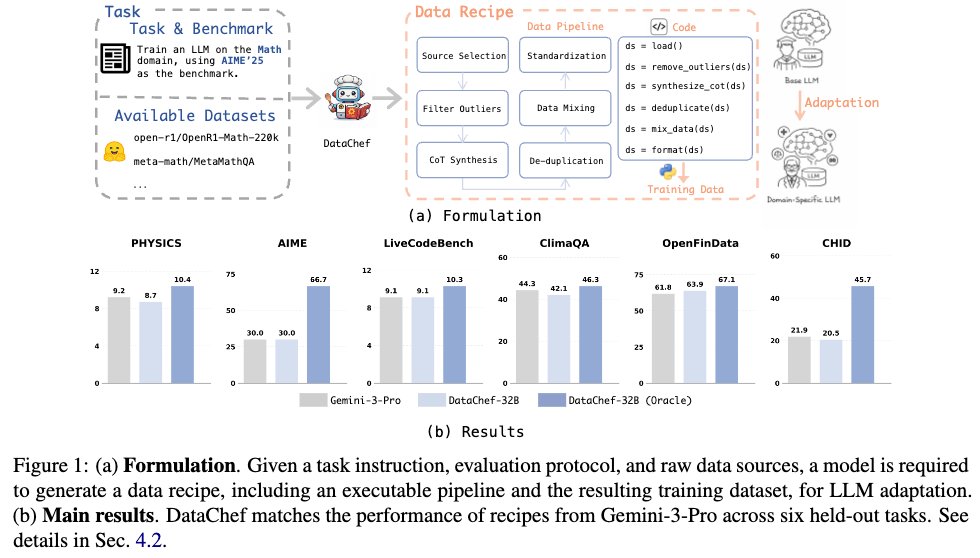
🔥Introducing #DataChef: an AI4AI framework that leverages reinforcement learning to automatically generate optimal data recipes for LLM adaptation.
🥳By exploring vast code spaces with an efficient proxy reward system, DataChef-32B matches the performance of top-tier models like Gemini-3-Pro in recipe generation, and its resulting recipes surpass industry-level expert curation on challenging benchmarks such as AIME'25 and ClimaQA.
🤗GitHub:
https://t.co/3VdeTQBqSU
🤗Model:@HuggingModels
https://t.co/fql2tbWjQW
🤗Demo:
https://t.co/pKcHvkHfoZ
🚀Meet InternVL-U: a lightweight 4B unified multimodal model that brings reasoning, generation, and editing into a unified framework.
🔥Built upon unified contextual modeling, modality-specific modular design, and decoupled visual representations, InternVL-U achieves a strong performance-efficiency trade-off, consistently outperforming unified baselines with over 3× larger model scales on challenging tasks such as text rendering, scientific reasoning, and spatially grounded generation and editing.
😉Open-source and designed for efficient, practical multimodal intelligence.
🤗GitHub:
https://t.co/4gJwj6Ehv0
🤗Hugging Face: @huggingface
https://t.co/idOhLCXz46
🤗GenEditEvalKit:
https://t.co/V4lQkkieWW
🤗TextEdit:
https://t.co/AmydjNWHPF
🤗Tech report:
https://t.co/DJc2vof17l
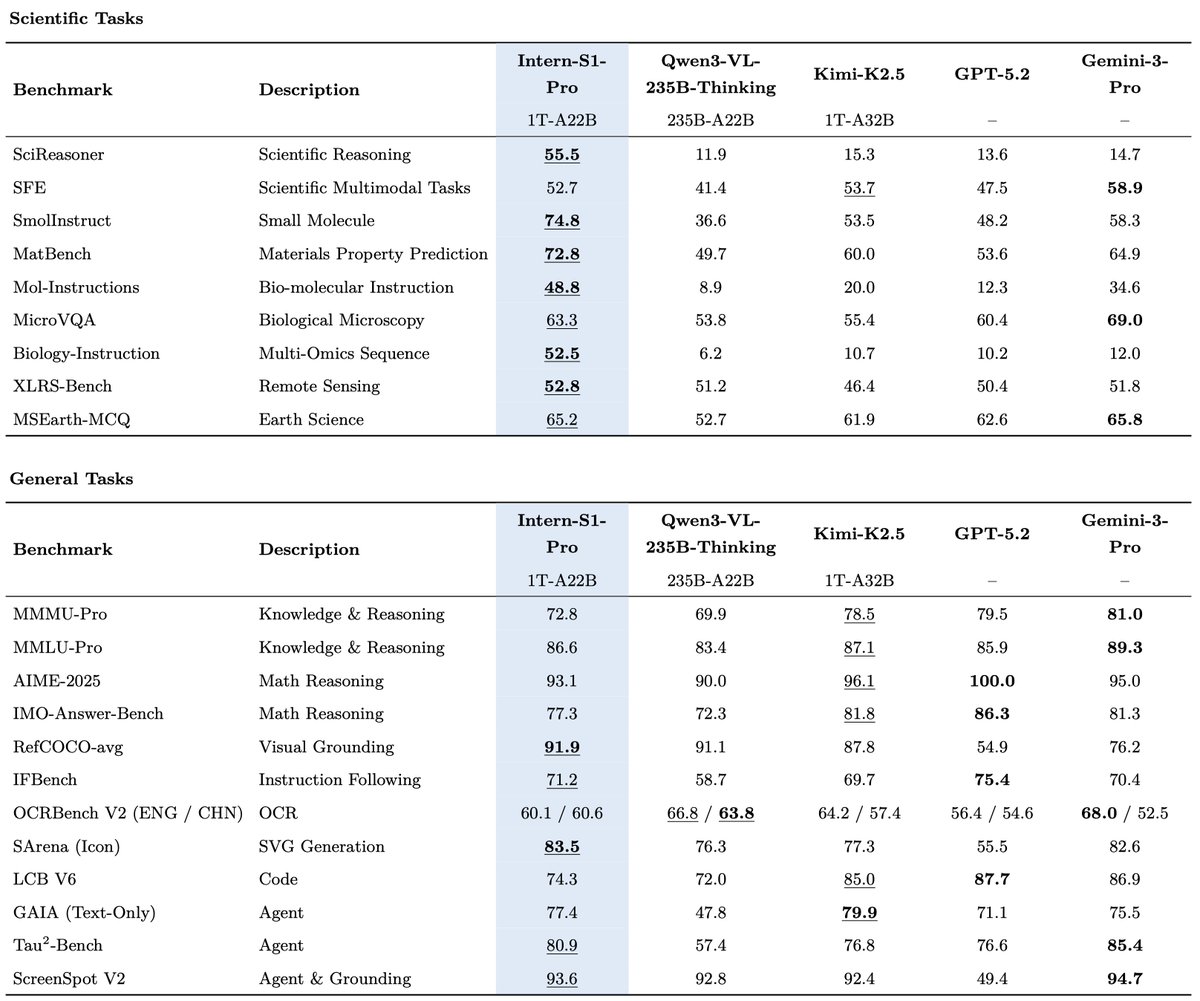
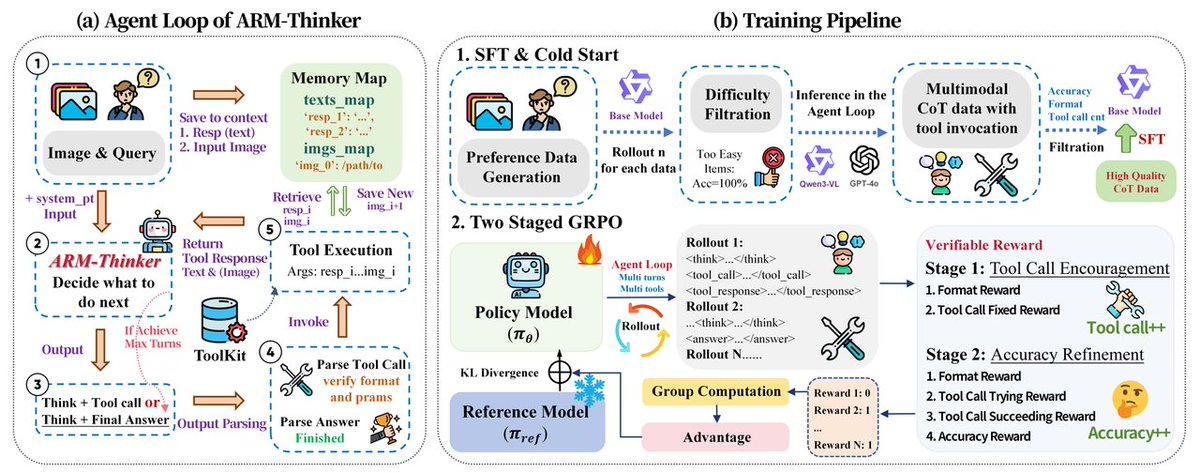
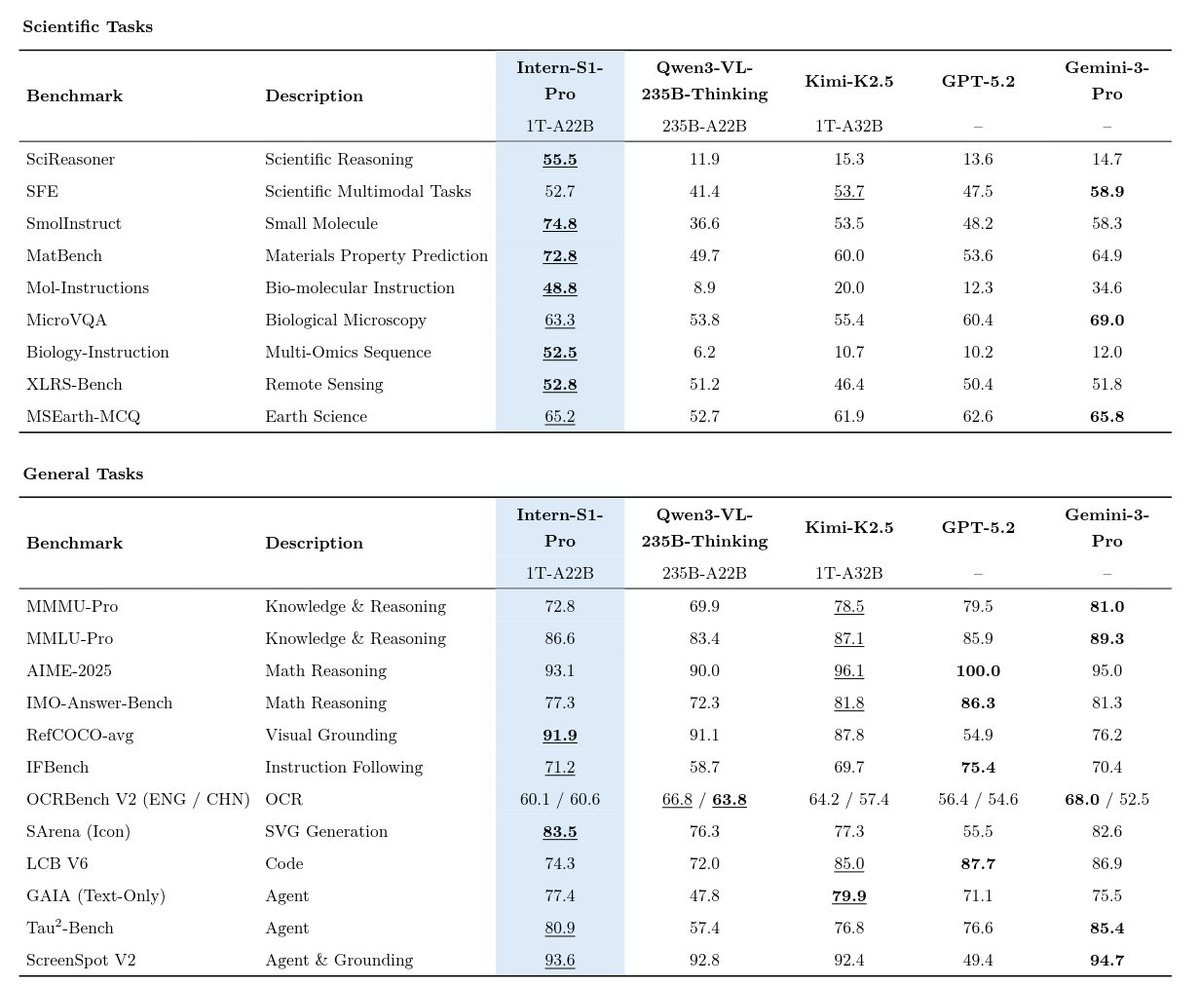
🚀Introducing Intern-S1-Pro, an advanced 1T MoE open-source multimodal scientific reasoning model.
1⃣SOTA scientific reasoning, competitive with leading closed-source models across AI4Science tasks.
2⃣Top-tier performance on advanced reasoning benchmarks, strong general multimodal performance on various benchmarks.
3⃣1T-A22B MoE training efficiency with STE routing (dense gradient for router training) and grouped routing for stable convergence and balanced expert parallelism.
4⃣Fourier Position Encoding (FoPE) + upgraded time-series modeling for better physical signal representation; supports long, heterogeneous time-series (10^0–10^6 points).
😍Intern-S1-Pro is now supported by vLLM @vllm_project and SGLang @sgl_project@lmsysorg — more ecosystem integrations are on the way.
☺️Model:@huggingface
https://t.co/ZJivpSrnaL
☺️GitHub:
https://t.co/ImW2Tzh5GP
☺️Try it now at:
https://t.co/OpebPDJ2V5
🎉 Congrats to @intern_lm on Intern-S1-Pro — day-0 support in vLLM!
🔬 Trillion-scale MoE for scientific reasoning: 1T total params, 512 experts, 22B activated per token. State-of-the-art across AI4Science domains.
PR: https://t.co/bQov0E7U6I
Serving command (✅ Verified on NVIDIA GPUs):
😊 Congrats to @intern_lm on releasing Intern-S1-Pro, a 1T-parameter MoE multimodal scientific reasoning model. Day-0 support is now live in SGLang!
Highlights:
📖 SOTA AI4Science reasoning, competitive with top closed models; strong advanced reasoning + multimodal benchmarks
⚙️ 1T-A22B MoE with STE & grouped routing; FoPE + long time-series modeling
Related PR: https://t.co/chW5knfWOv
Try it with the following command:
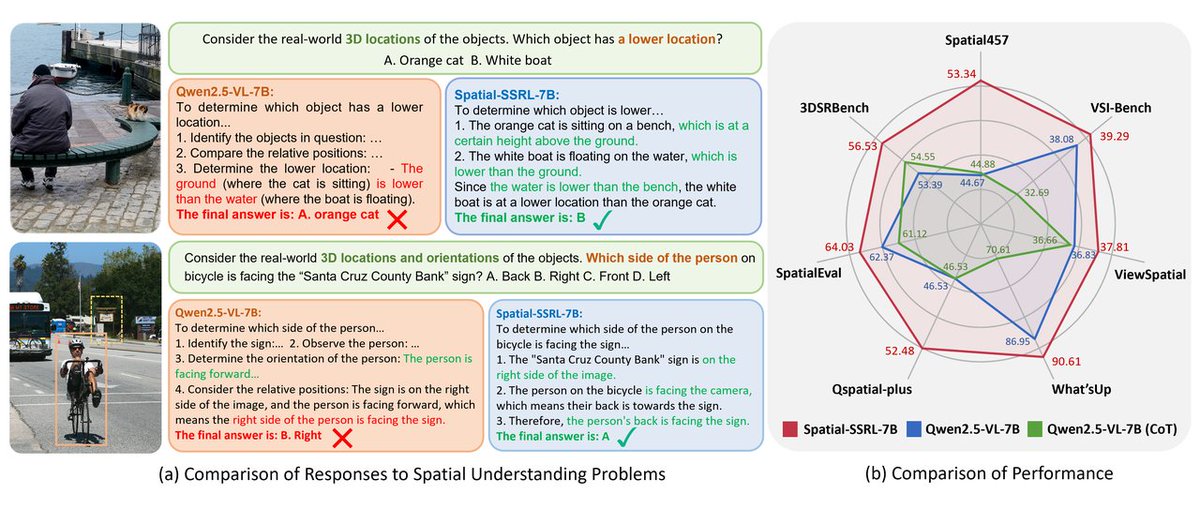
🚀 Introducing Spatial-SSRL, the first study which proposes a Self-Supervised Reinforcement Learning paradigm for spatial understanding.
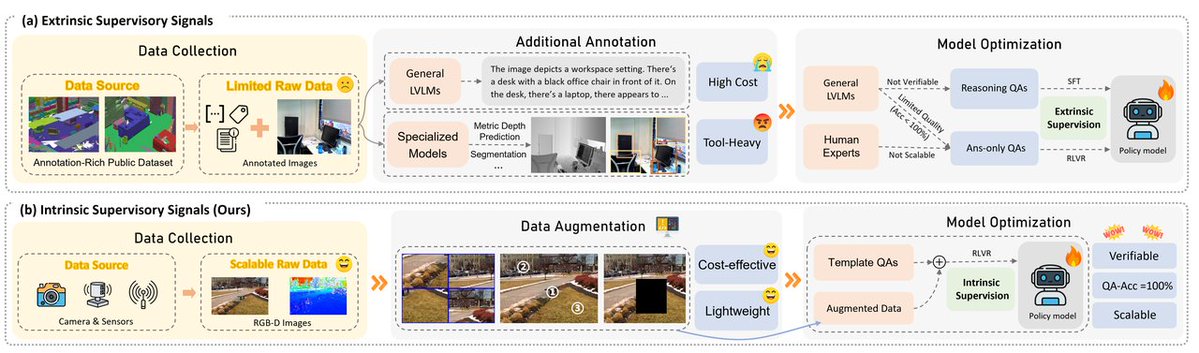
💡 Spatial-SSRL a lightweight tool-free framework that aims at enhancing spatial intelligence and is natually compatible with the RLVR training paradigm. Only raw 2D and RGB-D images are required and we avoid any use of human annotation, external proprietary model or expert model throughout the entire pipeline, making Spatial-SSRL highly cost-effective and scalable.
🛰️ Spatial-SSRL comprises five pretext tasks now: shuffled patch reordering, flipped patch recognition, cropped patch inpainting, regional depth ordering, and 3D relative position prediction. Thanks to its lightweight characteristics, Spatial-SSRL can be easily extended to more pretext tasks and we welcome the whole community to join Spatial-SSRL with effective pretext tasks!
🤖 After applying Spatial-SSRL, we significantly enhance the performance of spatial understanding on Qwen2.5-VL (3B&7B) and Qwen3-VL (4B), as well as retaining their general visual capabilities.
🤗 Currently, we have released the repository of Spatial-SSRL, the dataset Spatial-SSRL-81k, and the trained models: Spatial-SSRL-7B and Spatial-SSRL-Qwen3VL-4B. The total download of the models and dataset has surpassed 1,000.
👇 Try Spatial-SSRL-7B now at: https://t.co/OYqii6LiCq
Paper: https://t.co/2Bl8N6zK21
Github: https://t.co/CIgR9ZEG8q
Model (on Qwen2.5-VL): https://t.co/RuOCKtyjYH
Model (on Qwen3-VL): https://t.co/5xWB2Le97O
Dataset: https://t.co/9qziXUl10x
🚀Introducing #CapRL, the first study of applying GRPO for the open-ended and subjective image captioning task. 🤯
🤖The trained CapRL-3B model achieves image captioning performance comparable to Qwen2.5-VL-72B.
✨CapRL introduces a novel training framework that redefines caption quality through its utility: a high-quality caption should enable a non-visual language model to accurately answer questions about the corresponding image.
📈Currently, CapRL is open-sourced, with total downloads of the models and datasets surpassing 7,000. The research team is continuously iterating with stronger base models and improved training recipe.
👇
Try it now at:
https://t.co/Ct47w8bCJF
Paper:
https://t.co/X9oXDm9jN6
GitHub:
https://t.co/pAOysbLR8w
Model:
https://t.co/MDflHT6Qjy
Dataset: https://t.co/NbIS4X1qoZ
🚀 Big news for #lmdeploy v0.10.1!
🥳Our #FP8 high-performance inference is no longer limited to the latest #GPUs. It now supports all #NVIDIA architectures from V100 onwards, bringing major speedups to more users.
🤗https://t.co/bPJfr9rz5p
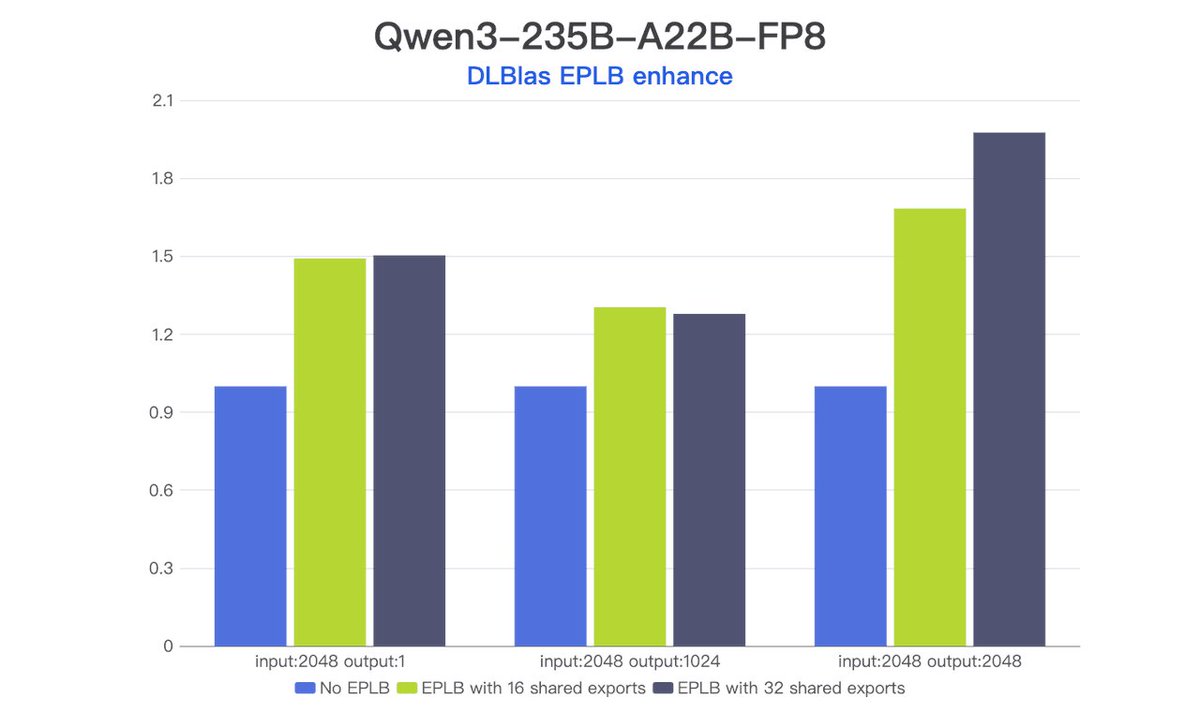
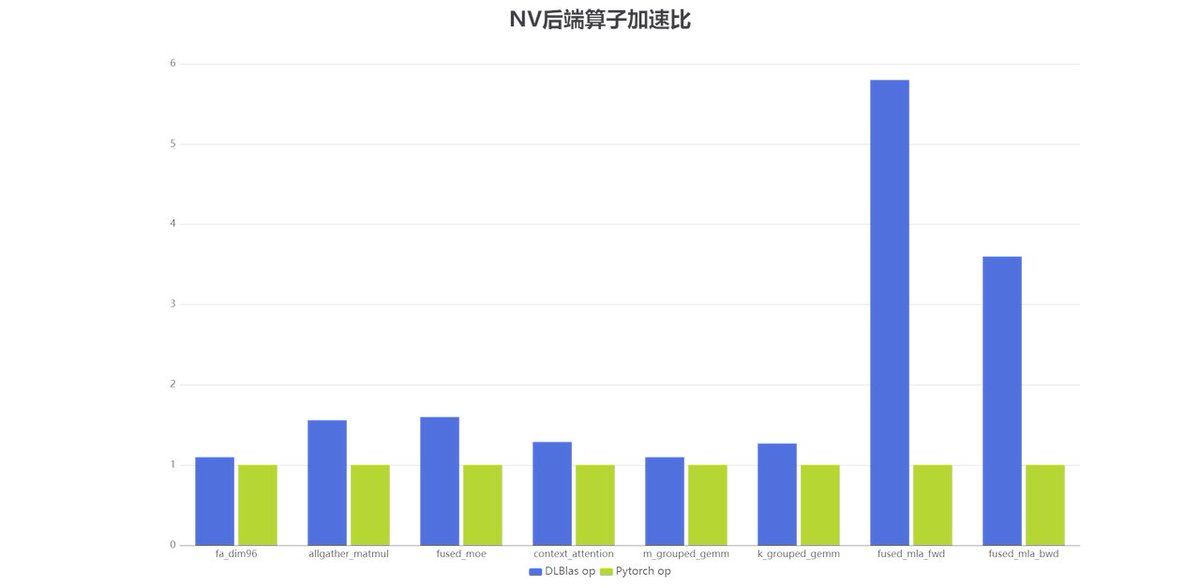
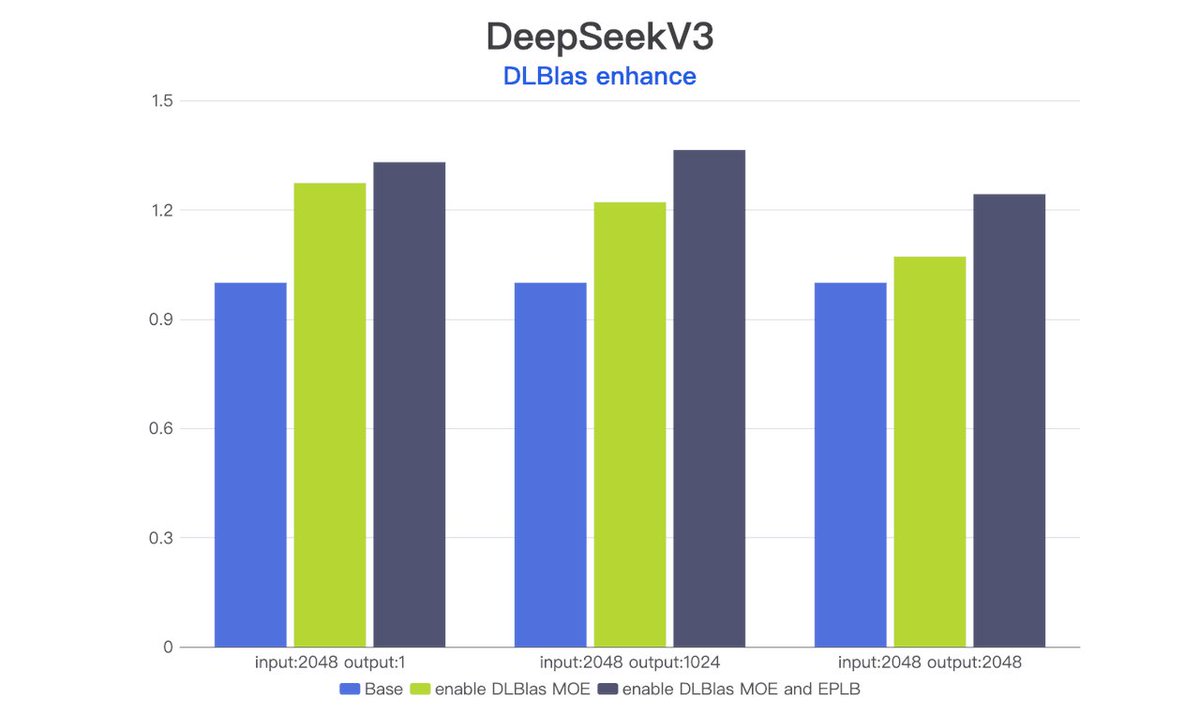
Introducing #DLCompiler and #DLBlas. Developers can achieve performance close to the hardware peak without manual tuning. And for the first time, Triton OP achieves extreme performance optimization on DSA chips.
DLCompiler: https://t.co/xZKZh98NOf
DLBlas:https://t.co/FSRx2EHghL
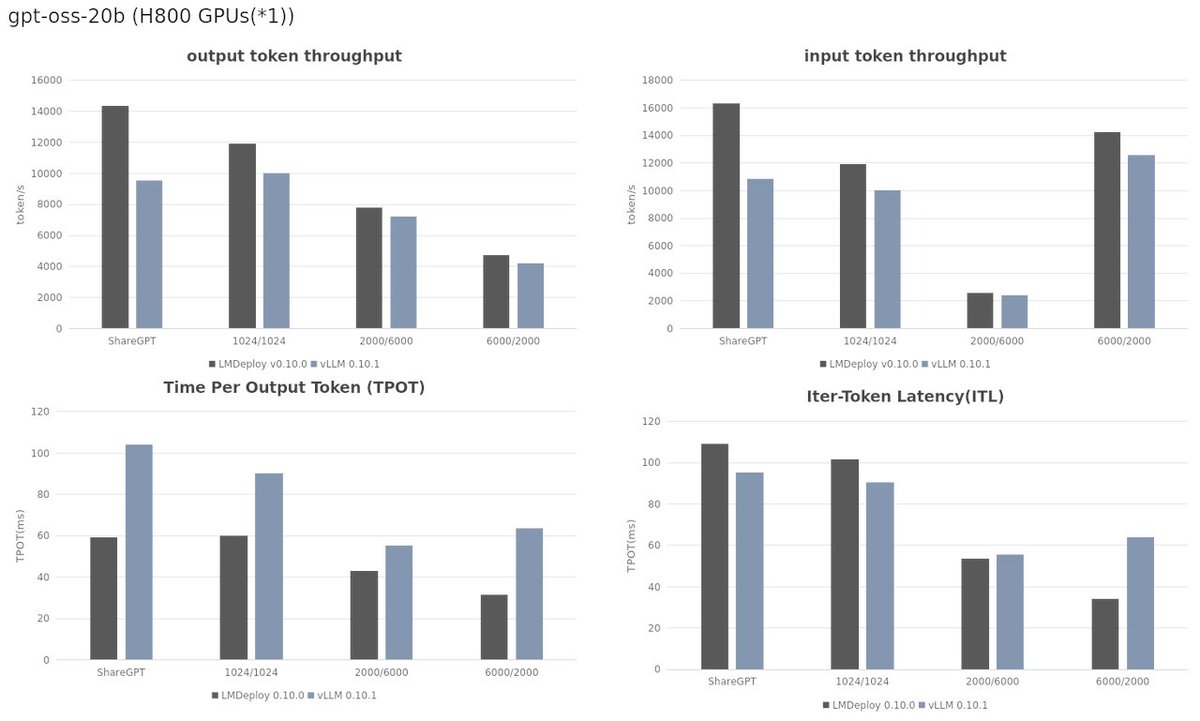
🔥LMDeploy v0.10.0 released!
😊Supercharges OpenAI’s GPT-OSS MXFP4 models.
😊Delivers exceptional performance for GPT-OSS models on V100 and higher GPUs.
😊On H800 & A100, LMDeploy outperforms vLLM across all scenarios—faster, more efficient inference!
🤗https://t.co/bPJfr9rz5p
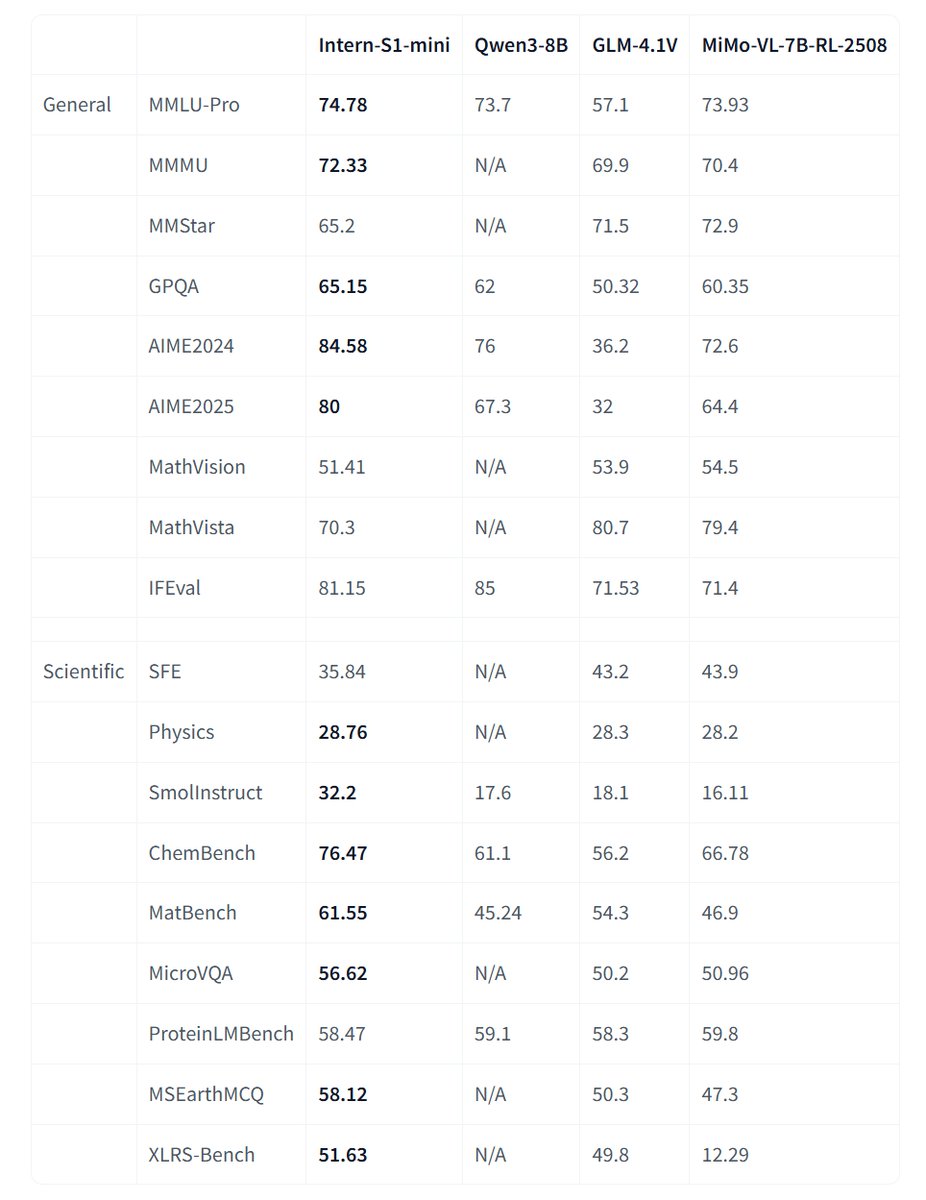
🔥Introducing Intern-S1-mini, a lightweight open-source multimodal reasoning model based on the same techniques as Intern-S1.
🥳With just 8B parameters, it’s optimized for fast deployment and easy customization.
- Strong general capabilities while excelling in specialized scientific domains.
- Built upon an 8B dense language model and a 0.3B vision encoder.
- A capable research assistant for real-world scientific applications.
🤗Model:@huggingface
https://t.co/pvuA8Wj8Y4
🤗GitHub:
https://t.co/ImW2Tzh5GP
🤗Try it now at:
https://t.co/OpebPDJ2V5
#InternS1