Explore how Project Euphonia’s open-source tools empower developers to build personalized audio tools and fine-tune open-weight models for diverse speech patterns, advancing speech tech for everyone. #GAAD → https://t.co/O3chsFgm2f
Today on the blog, we share a comprehensive evaluation of transformer models’ graph reasoning capabilities, shedding light on their effectiveness across a variety of graph reasoning tasks and introducing a novel representational hierarchy. Learn more →https://t.co/EEuPJmYiqQ
Today on the blog, we demonstrate the feasibility & benefits of learning from human feedback for text-to-image generation by obtaining rich human feedback, then training a model to predict this feedback to enable improved image generation. Learn more →https://t.co/OI7rdRiCv4
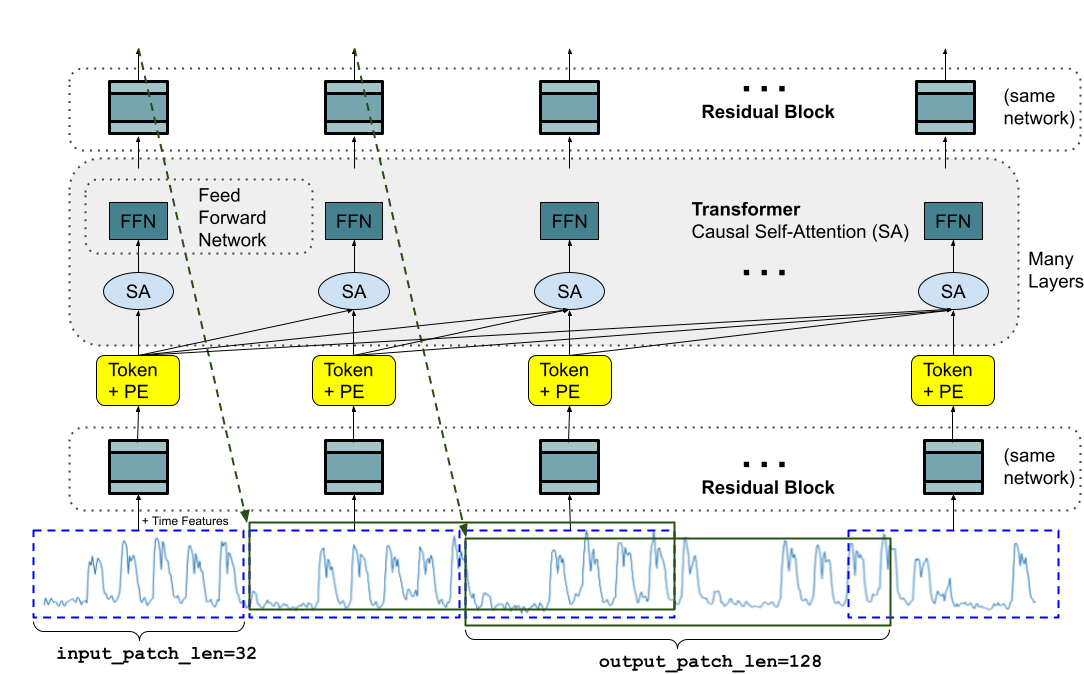
TimesFM is a forecasting model, pre-trained on a large time-series corpus of 100 billion real world time-points, that displays impressive zero-shot performance on a variety of public benchmarks from different domains and granularities. Learn more → https://t.co/U1OctNPZET
When applying #DifferentialPrivacy to multi-step #ML algorithms, there is a privacy loss that scales with each step, known as the cost of composition. Learn about a new paradigm that avoids this composition cost for significant improvements in utility. ↓https://t.co/blS4LCFE8N
A new generalization of automatic differentiation lets researchers compute upper and lower bounds on functions, instead of just derivatives, leading toward more principled learning rate selection during #ML model training. Learn more: https://t.co/rmESYdqGzE
Great #ML research requires great systems. Here we discuss some strategies we’re using to help serve and train sophisticated ML models while easing the complexity of implementation for end users. Read more at https://t.co/ldl8MkMmrg
Verbal disfluencies are common in day-to-day speech, and while people often don’t notice them, they can be very challenging for #NLP models. Check out a new #ML approach that removes disfluencies from speech transcripts for improved NLP performance. https://t.co/TzoWYxt4LQ
Introducing a novel approach for interpretable, robust, and reliable deep neural networks (DNNs) that employs controllable rule representations, which do not require retraining to adjust the rule strength at inference. Learn more below ↓ https://t.co/MjBUnj4GTT
Understanding how neural networks reach decisions can be challenging, but is also valuable for uses from image analysis to scientific discovery. A new approach, called StylEx, discovers and visualizes how disentangled attributes affect a classifier → https://t.co/FHSjZcw7lT
Preparing text for processing by an #ML model often involves tokenization, in which text is split into smaller units (e.g., words or word segments). Today we present a new approach that speeds up the process by up to 8x compared to standard methods. https://t.co/aC6bqpnDCu
Making reasonable predictions about the future is an important capability for #ML agents to be most useful. Learn about a new approach that is self-supervised and learns a predictive model that can be applied, without fine-tuning, to a variety of tasks ↓ https://t.co/R0N9keoV3m
Clustering algorithms partition datasets into meaningful groups and are a key building block of unsupervised #ML. Learn about a new clustering algorithm that enhances privacy while maintaining or improving performance against existing benchmarks ↓ https://t.co/9GgwIlyRao
#ReinforcementLearning (RL) agents have shown promising results across various activities, but often cannot generalize to new tasks, even if they are similar. Learn about a new approach that incorporates RL’s sequential structure to enhance generalization→https://t.co/BSOciuybj5