My team @cohere is hiring 2 full time roles! 1st: We're hiring a ✨Senior Research Engineer✨. This is for a dedicated engineer on a modelling team so there's a lot of autonomy; looking for someone to be opinionated and own vision for our pipelines https://t.co/baEm4Y2KbI
Been thinking recently about how to improve credit assignment in long horizon RL?
Our new MosaicLeaks blog post describes our method to accurately value actions via situational rewards, improving our privacy-aware research agent over outcome-only rewards!
https://t.co/xCbOKEcdwa
Introducing Cohere's first open-source coding model: North Mini Code
Small & efficient, designed for agentic performance and built for community input.
Excited to share my recent work @ServiceNowRSRCH ! We introduce a new privacy-centric deep research dataset and show models frequently leak enterprise information.
However, training with dense _situational_ rewards efficiently learns to jointly optimize performance and privacy
I’ll be presenting TABLET at #ICLR2026 this week! Our 4 million example Visual Table Understanding dataset with original table visualisations! Come and say hi! :D We’ll have actual Scottish tablets 👀
See you all on Friday at 7:15 PM Pavilion 4 P4-#3606
https://t.co/3IKS3rNOJt
Excited to share that I will be presenting my 1st year PhD work at #ICLR2026@iclr_conf next week in Rio 🇧🇷
❓In-Context Learning (ICL) has been a widely used paradigm to adapt LLMs for a task with a few examples or shots. But does it also work for multimodal examples? 🧵
The approach can be extended to ANY task with:
▫️Ambiguous inputs
▫️Multiple valid answers (e.g., disagreement from annotators)
📄 Paper: https://t.co/TYqaKt9KSI
6/6
Reasoning models are powerful, but they burn thousands of tokens on potentially wrong interpretations for ambiguous requests!
👉 We teach models to think about intent first and provide all interpretations and answers in a single response via RL with dual reward.
🧵1/6
New preprint: How can we use latent-reasoning when initial model performance is low?
We introduce LiteReason, a simple and lightweight framework that combines latent reasoning _with RL_ to reason efficiently both during and after training while retaining performance gains!
🧵
🎤 @serj_troshin will present this work November 9th at 09:55-10:30 (poster lightning talk) and 11:00 - 12:15 (poster), Room A207
📄 Paper: https://t.co/4MRhKuVjxs
💻 Code: https://t.co/vbMbhOl5oN
3/3
Excited to share our paper "Asking a Language Model for Diverse Responses" accepted at #UncertaiNLP workshop at #EMNLP2025
When generating diverse responses, most use parallel sampling. We study non-independent alternatives: enumeration & iterative sampling.
w/ @serj_troshin
👇
We compare these strategies on:
✔️ Quality & efficiency
✔️ Lexical diversity
✔️ Computational flow diversity (a new metric we propose that's more suitable for reasoning tasks like math)
Key finding: non-independent sampling boosts diversity without sacrificing quality! ✨
2/3
Excited to share my first work as a PhD student at @EdinburghNLP that I will be presenting at EMNLP!
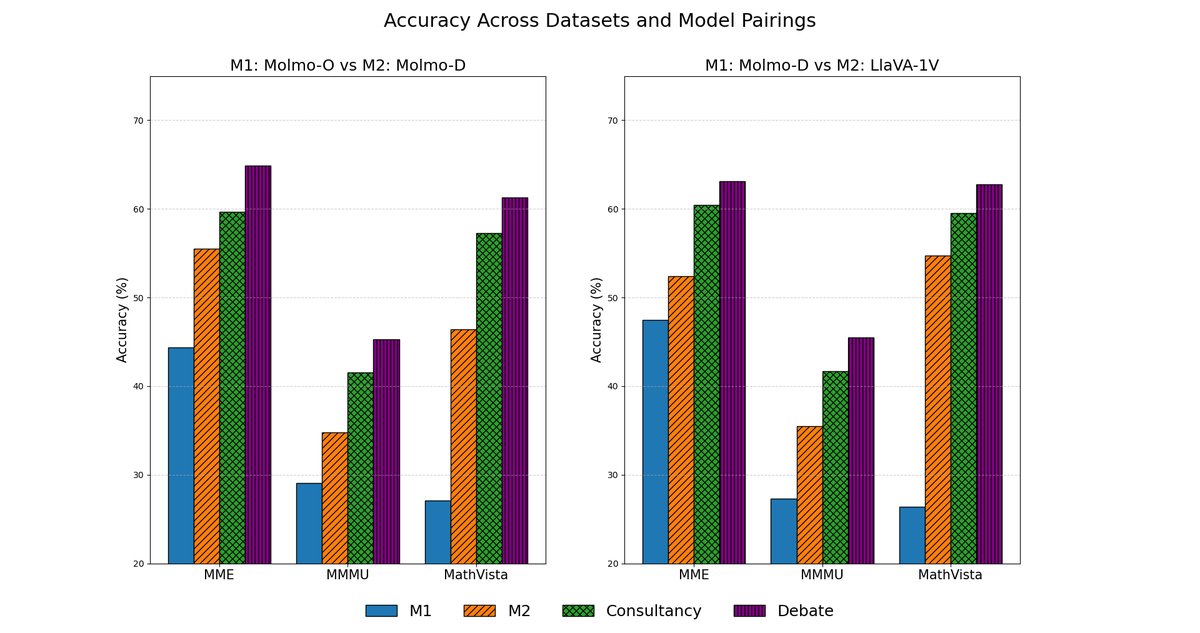
RQ1: Can we achieve scalable oversight across modalities via debate?
Yes! We show that debating VLMs lead to better model quality of answers for reasoning tasks.