I’ll be presenting TABLET at #ICLR2026 this week! Our 4 million example Visual Table Understanding dataset with original table visualisations! Come and say hi! :D We’ll have actual Scottish tablets 👀
See you all on Friday at 7:15 PM Pavilion 4 P4-#3606
https://t.co/3IKS3rNOJt
Reasoning models are powerful, but they burn thousands of tokens on potentially wrong interpretations for ambiguous requests!
👉 We teach models to think about intent first and provide all interpretations and answers in a single response via RL with dual reward.
🧵1/6
Excited to share my first work as a PhD student at @EdinburghNLP that I will be presenting at EMNLP!
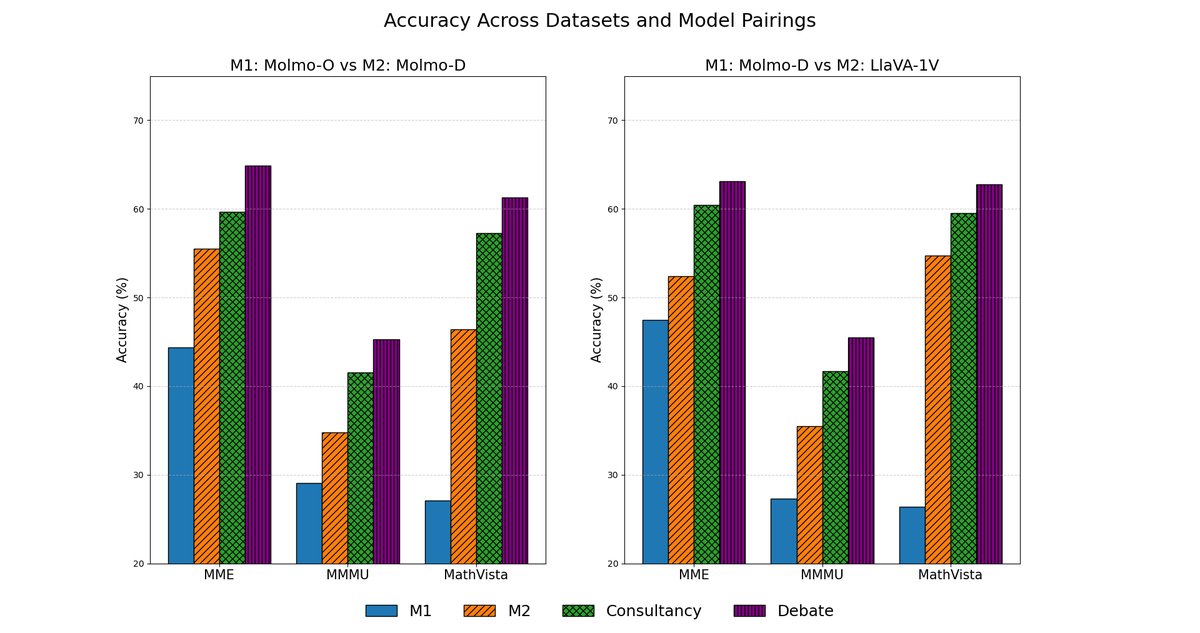
RQ1: Can we achieve scalable oversight across modalities via debate?
Yes! We show that debating VLMs lead to better model quality of answers for reasoning tasks.
Atzo eta gaur euskarazko ereduen artean onena aukeratzen utzi diegu #IEB2024|ko parte hartzaileei. Mila esker deneri!!
Sistema komertzialez gain HiTZ garatzen ari den Latxa 🐑berri txikiena ere probatu dugu, 8B tamainakoa. Llama 3.1-en oinarritzen da.
Eta irabazlea… 🥁
New paper: "What's New in My Data? Novelty Exploration via Contrastive Generation," w/ @iatitov at @EdinburghNLP
https://t.co/vXghE4StN1
With no access to the data, but only access to the pre-trained and fine-tuned model, we can reveal novel aspects of the fine-tuning dataset.
WE ARE HIRING!!
The HiTZ Center (https://t.co/pXKSIOPmm7) at the University of the Basque Country (UPV/EHU) invites applications for several funded research engineering and pre/postdoctoral positions in Natural Language and Speech Processing.
https://t.co/wDAZRzRjrL
Today I will be presenting Latxa at @aclmeeting In-Person Poster Session 3 at 16:00-17:30. Come if you want to hear about our work. I will be giving out Latxa stickers too! #ACL2024NLP
Hey! I will be presenting our work, PixT3: Pixel-based Table-To-Text Generation, tomorrow at Poster Session 1 at 11:00AM during #ACL2024NLP Come and say hi! :D
Reimagining table representation! In our new #ACL2024NLP paper we introduce PixT3: a family of image-based Table-to-Text Generation models that scale better at generating text from large tables, outperforming traditional text-based baselines.
https://t.co/wCylW9DdsE
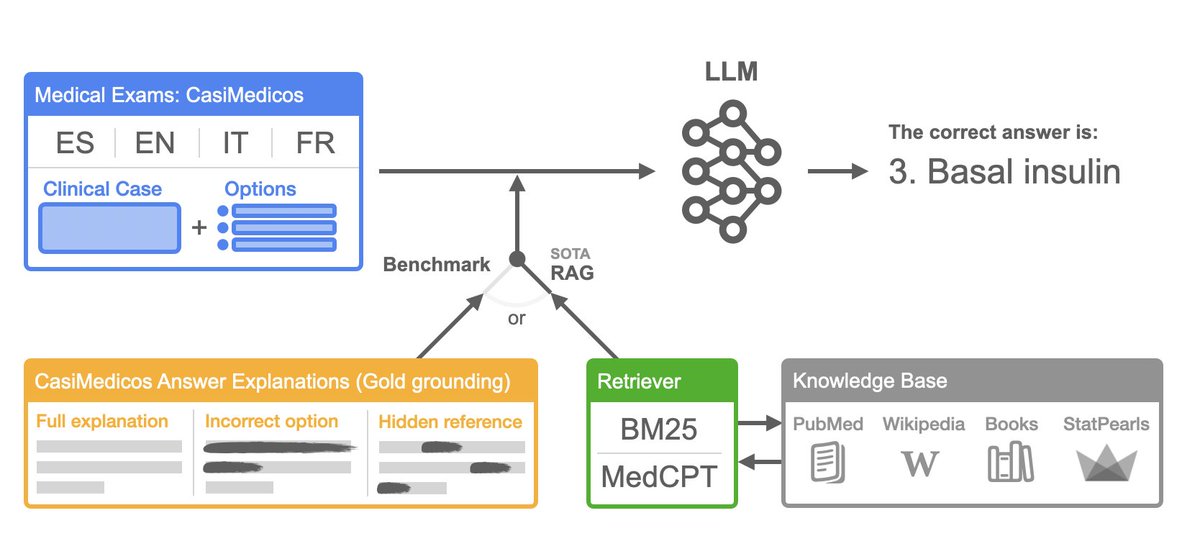
Conclusions: (i) Overall performance of LLMs with or without RAG still has large room for improvement; (ii) Performance for non-English languages substantially lower - stresses urgent need of advancing Medical QA in languages different to English
New @hitz_zentroa paper! "MedExpQA: Multilingual Benchmarking of Large Language Models for Medical Question Answering"; w/ @ragerri and @jiporanm in Artificial Intelligence in Medicine (Elsevier)
Paper: https://t.co/iXH8ovdamD
Resources: https://t.co/pcBAF2FKfN
Highlights: (i) MedExpQA: the first multilingual benchmark for MedicalQA including gold reference explanations; (ii) Exhaustive comparison of gold reference explanations with respect to automatically retrieved medical knowledge using state-of-the-art RAG techniques
LLMs are the de facto building block in recent multimodal models. Yet, it is still unclear why text-only models can generalize to multimodal inputs!
We investigate why, and provide insights with practical implications on performance, efficiency and safety problems. (1/10)