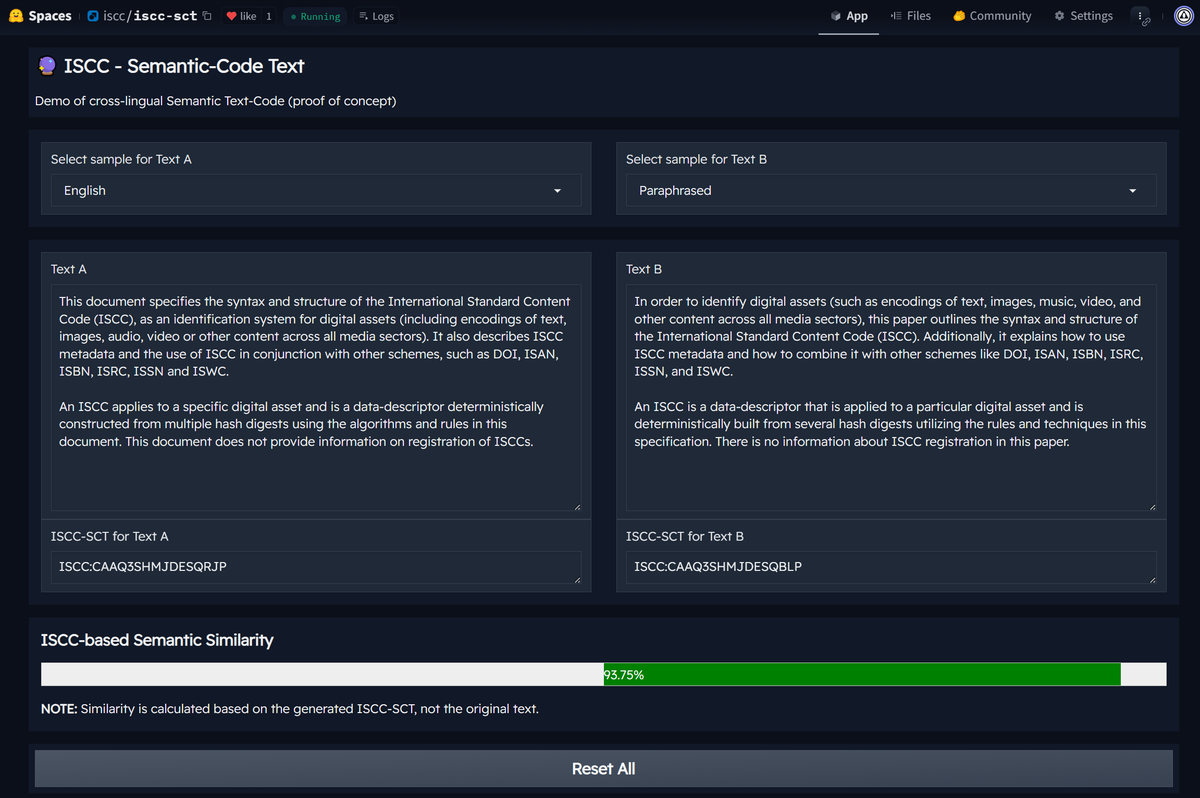
We're pleased to announce the release of ISCC-SCT. It generates semantic, language-independent codes for text, capable of matching translations, paraphrases, and granular text chunks.
Explore the demo here: 🔗 https://t.co/xMy9h3rPSS
@mixedbreadai@JinaAI_@nomic_ai
We're pleased to announce the release of ISCC-SCT. It generates semantic, language-independent codes for text, capable of matching translations, paraphrases, and granular text chunks.
Explore the demo here: 🔗 https://t.co/xMy9h3rPSS
@mixedbreadai@JinaAI_@nomic_ai
Today marks a pivotal moment in the digital media landscape with ISO's release of the #ISCC under #ISO 24138, a significant leap forward for digital transparency and trust in the dawning AI era! /1
There's big news on the content provenance front. The @iscc_foundation has a new standard out - ISO 24138 - which provides a link between an identifier for a work (like an ISBN or DOI) and the various forms that work can take online.
The Semantic Code is engineered to be robust against a broader range of variations that cannot be matched with the perceptual Image-Code. https://t.co/vOXf9vE22k
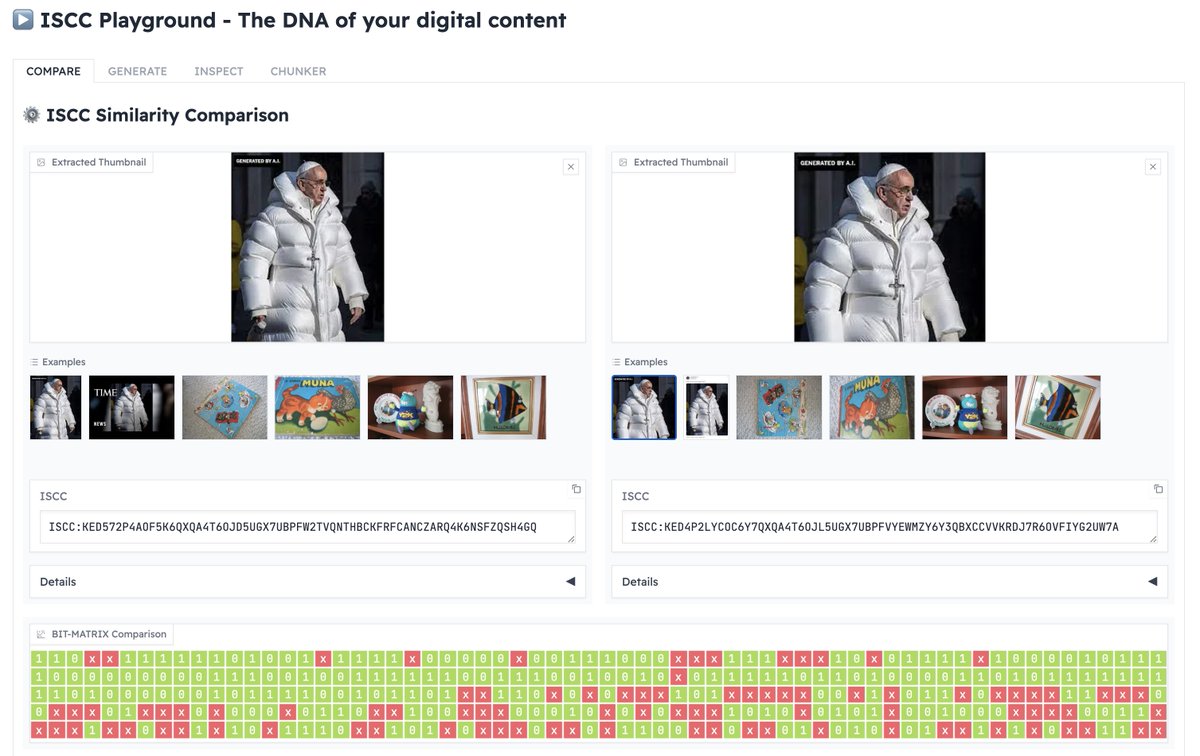
On the ISCC Playground you can test the experimental Semantic Code of the ISCC. It is a compact binary code based on deep learning vector embeddings, which allows matching and comparison of semantic characteristics of content files.
https://t.co/r3VeUjZIqW
New development, new ISO stage (code 50.00), the Draft International Standard (DIS) was approved, the final text is now at ISO for further processing. – ISCC is now ISO/PRF 24138 – International Standard Content Code (ISCC). Follow the updates, here --> https://t.co/I2znedpELO
International Standard Content Code (ISCC), a content-derived identifier for digital content identification, is currently under development as ISO/DIS 24138 (Draft International Standard). On the ISO platform you can get a glimpse on the upcoming standard: https://t.co/KSEj1MdSC0
@alexjc Totally agree, including the use of iscc codes to identify content as you say later. Add an ingestion time stamp for comparison with a possible tdm opt-out activation by the provider of the content (see w3c tdm reservation protocol).
𝙷 𝙾 𝚆 ?
I'm not talking about providing per-item URLs like a dataset, but content codes or hashes for training data — along with some metadata such as the source (e.g. domain), size and mime-type, and the legal basis for accessing the file (e.g. contract, license, fair use).
I'm calling it! 🤙
It's inevitable that item-level training data disclosures will become a standard for AI companies that want to exploit or license models commercially.
If you're operating a commercial service, you'll be expected to provide data manifests...
What? Why? ⤵️
Interesting column by @PPLUK's CIO @mpdouglas, suggesting to further investigate the ISCC, which could support ‘clustering’ of same or near-duplicate content to help solving problems ranging from accuracy to fraud. https://t.co/HgwF3mrK2v
Create ISCC codes for your creative works and digital media files: https://t.co/tZxl77HOsl Now with support for metadata embedding for PDF and EPUB files, and thumbnail generation for PDF, EPUB and audio files with cover images.
ISCC encryption & webtoon content, an upcoming revolution for data's reports?
One "unconventional" use I am really looking forward to, for the digital comic / webtoon industry, is the possibility to track all the data's related to the use / reads / downl…https://t.co/3nkyHOO3Fh