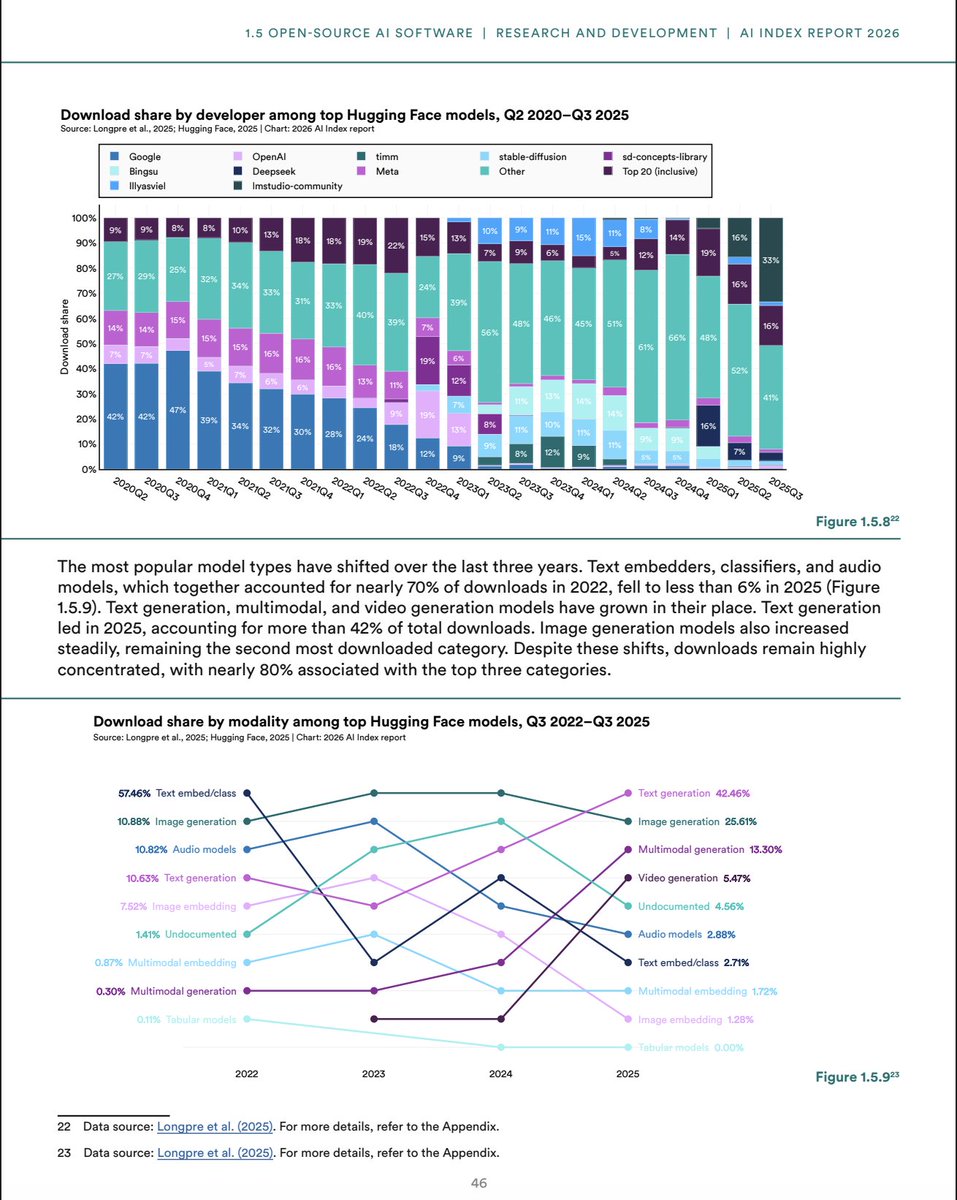
Excited to see our Economies of Open Intelligence work highlighted in Chp. 1 of @StanfordHAI's #AIIndex2026!
We release tons of info on the open model ecosystem, using 🤗 HF data.
Thank you @russellwald and team!
We just released the Google Research Blog for ATLAS 🗺️!
Check out for:
1) Multilingual scaling and data mixing laws for 100s of languages
2) "Curse of Multilinguality" modeling
3) Cross-lingual transfer scores
🌎 https://t.co/e7K9q149M3
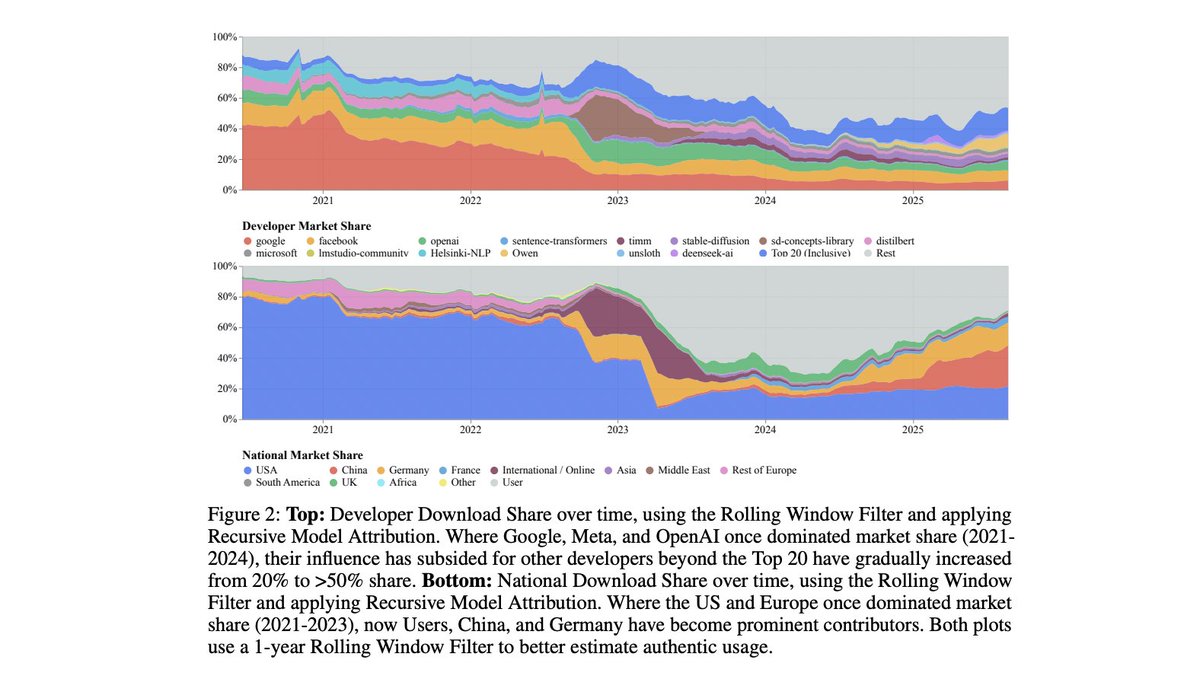
The open AI race is becoming more competitive, and more international.
Check out @Melissahei's excellent coverage of our new study in the @FT!
https://t.co/hCi9rX265I
Who is winning the open AI race?
Our new study "Economies of Open Intelligence" maps 2.2B @huggingface downloads across 851k models (2020→2025).
1) Power is rebalancing (US big tech ↓; China + community ↑)
2) Models got big & efficient (MoE, quant, multimodal surge)
3) Intermediaries now matter (adapters/quantizers steer usage)
4) Transparency is slipping
/🧵
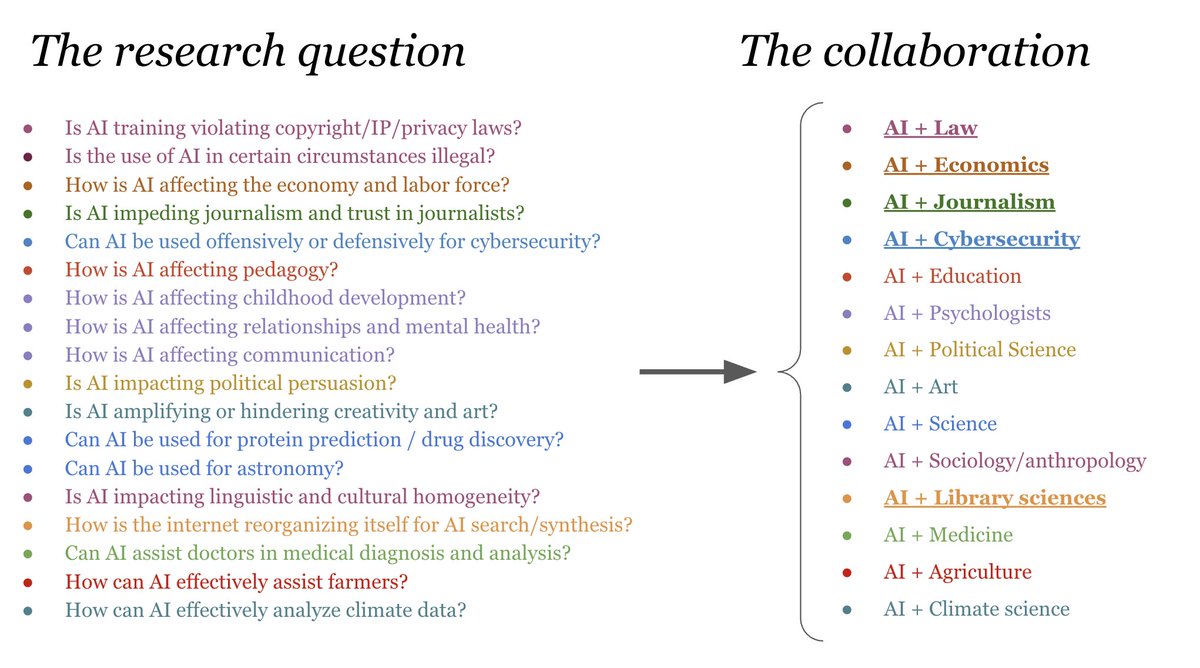
TL;DR: Seven lessons on collaboration in AI research (slides below). Presented last week as a keynote at @Cohere_Labs Connect 2025.
Last week I gave a keynote on Collaboration in AI Research at Cohere Labs Connect 2025, alongside Cohere co-founder @1vnzh, Head of Cohere Labs @mziizm, and Chief AI Officer @jpineau1. I’m grateful for the invitation—and for the many collaborators whose work shaped this talk.
Slides: a practical roadmap for starting an interdisciplinary research collaboration. In brief:
1. Ideate clearly. Share a one-pager with potential collaborators, advisors, and critics.
2. Run a pre-mortem. Find your “reviewer #2” early and invite their critiques to sharpen direction.
3. Recruit widely. Don’t let geography or institution limit you; add complementary skills, senior advisors, and junior contributors.
4. Structure incentives. Be explicit about authorship, credit, visibility, and impact; let people own their piece.
5. Communicate early and often. Relationships may be the most durable outcome. Align early on authorship contingencies, timeline, cadence, and responsibilities.
6. Document decisions. Keep a living record of links, choices (and why), and who did what—details slip in larger teams.
7. Focus on infrastructure & visuals. Beyond relationships, open-source tools and clear figures/tables travel the farthest and longest.
I also folded in lessons from advisors, mentors, and collaborators including @alex_pentland , @sarahookr, @percyliang, @BlancheMinerva, @PeterHndrsn, @RishiBommasani, @sayashk, @AnkaReuel, and @RobertMahari and @TobinSouth.
A new, tractable approach to study scaling laws for larger data mixtures compared to prior art. We achieve significantly better fit ($R^2=0.98$) on multilingual data mixtures with ~50 languages.
Have you ever wondered how to build target-language LMs most efficiently? 🤨
Will finetuning from other multilingual LMs help? No curse of multilinguality?? See the snapshot below for the answer.
What about transferring data to help? What languages help? See our new paper! 👇
To scale data-constrained LLMs, repeating & denoising objectives can help. Another solution: Add multilingual data. But what languages help & how much? Below a snapshot for this at 2B scale, e.g., Chinese can hurt English while Indonesian may help.
Exciting to see someone do a study so elaborately and at such scale. I really like this grid looking at transfer synergy.
Also this result is cool. Intuitive that model capacity helps, but great to see an empirical result.
📢Thrilled to introduce ATLAS 🗺️: scaling laws beyond English, for pretraining, finetuning, and the curse of multilinguality.
The largest public, multilingual scaling study to-date—we ran 774 exps (10M-8B params, 400+ languages) to answer:
🌍Are scaling laws different by language?
🧙♂️Can we model the curse of multilinguality?
⚖️Pretrain from scratch or finetune from multilingual checkpoint?
🔀Cross-lingual transfer scores for 1444 lang pairs?
1/🧵
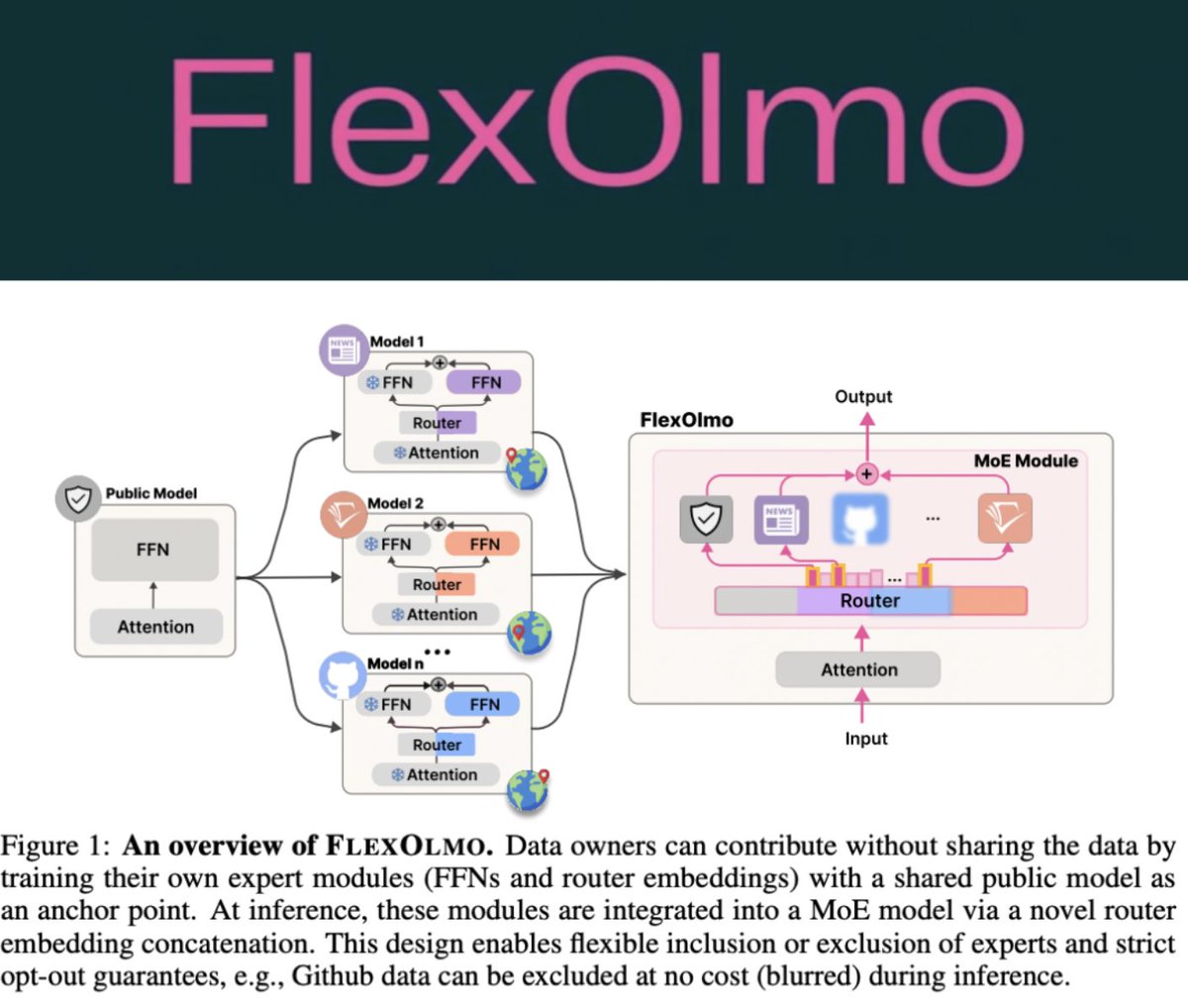
Copyrighted 🚧, private 🛑, and sensitive ☢️ data remain major challenges for AI.
FlexOlmo introduces an architectural mechanism to flexibly opt-in/opt-out segments of data in the training weights, **at inference time**.
(Prior common solutions were to filter your data once before training, and hope you got it right.)
Highly recommend checking out the incredible work, led by @WeijiaShi2, @AkshitaB93, @notkevinfarhat, @sewon__min
1/
Thrilled to collaborate on the launch of 📚 CommonPile v0.1 📚 !
Introducing the largest openly-licensed LLM pretraining corpus (8 TB), led by @kandpal_nikhil@blester125 @colinraffel.
📜: https://t.co/Gp4Rq8FrZp
📚🤖 Data & models: https://t.co/ZGWsUpzZbb
1/
Come say hello at ICLR! 👋 Here's where you can find me:
Friday: Data-centric AI Social! https://t.co/9MrWsVZvdC
Saturday: Multimodal Data Provenance poster (3 pm, Hall 2B #494)
Sunday: MLDPR Workshop (3 pm) [https://t.co/VjRSTfOSzv]—I'll talk about challenges to AI data collection and access
Monday: Building Trust in LLMs workshop (10:30 am) [https://t.co/ArGpTXEMmC]—I'll talk about third-party AI evaluation and flaw reporting
Monday again: Sci-FM Workshop (2 pm) [https://t.co/oOMsErofNf]—I'll talk about AI data access again
Come say hi! Attaching the works below.
Thrilled our global data ecosystem audit was accepted to #ICLR2025!
Empirically, we find:
1⃣ Soaring synthetic text data: ~10M tokens (pre-2018) to 100B+ (2024).
2⃣ YouTube is now 70%+ of speech/video data but could block third-party collection.
3⃣ <0.2% of data from Africa/South America.
1/
What are 3 concrete steps that can improve AI safety in 2025? 🤖⚠️
Our new paper, “In House Evaluation is Not Enough” has 3 calls-to-action to empower independent evaluators:
1️⃣ Standardized AI flaw reports
2️⃣ AI flaw disclosure programs + safe harbors.
3️⃣ A coordination center for transferable AI flaws affecting many systems.
1/🧵
I compiled a list of resources for understanding AI copyright challenges (US-centric). 📚
➡️ why is copyright an issue?
➡️ what is fair use?
➡️ why are memorization and generation important?
➡️ how does it impact the AI data supply / web crawling?
🧵
I wrote a spicy piece on "AI crawler wars"🐞 in @MIT@techreview (my first op-ed)!
While we’re busy watching copyright lawsuits & the EU AI Act, there’s a quieter battle over data access that affects websites, everyday users, and the open web.
🔗 https://t.co/pKKv64ZF05
1/






























![ShayneRedford's tweet photo. Come say hello at ICLR! 👋 Here's where you can find me:
Friday: Data-centric AI Social! https://t.co/9MrWsVZvdC
Saturday: Multimodal Data Provenance poster (3 pm, Hall 2B #494)
Sunday: MLDPR Workshop (3 pm) [https://t.co/VjRSTfOSzv]—I'll talk about challenges to AI data collection and access
Monday: Building Trust in LLMs workshop (10:30 am) [https://t.co/ArGpTXEMmC]—I'll talk about third-party AI evaluation and flaw reporting
Monday again: Sci-FM Workshop (2 pm) [https://t.co/oOMsErofNf]—I'll talk about AI data access again
Come say hi! Attaching the works below.](https://pbs.twimg.com/media/GpXedZJacAAUlBy.jpg)
























