Today, we released Lyra 2.0, a framework for generating persistent, explorable 3D worlds at scale, from NVIDIA Research.
Generating large-scale, complex environments is difficult for AI models. Current models often “forget” what spaces look like and lose track of movement over time, causing objects to shift, blur, or appear inconsistent. This prevents them from creating the reliable 3D environments required for downstream simulations. Lyra 2.0 solves these issues by:
✅ Maintaining per-frame 3D geometry to retrieve past frames and establish spatial correspondences
✅ Using self-augmented training to correct its own temporal drifting.
Lyra 2.0 turns an image into a 3D world you can walk through, look back, and drop a robot into for real-time rendering, simulation, and immersive applications.
➡️ Learn more: https://t.co/ROR7miJeCU
📄 Read the paper: https://t.co/1osU9EGjGD
Judging by my tl there is a growing gap in understanding of AI capability.
The first issue I think is around recency and tier of use. I think a lot of people tried the free tier of ChatGPT somewhere last year and allowed it to inform their views on AI a little too much. This is a group of reactions laughing at various quirks of the models, hallucinations, etc. Yes I also saw the viral videos of OpenAI's Advanced Voice mode fumbling simple queries like "should I drive or walk to the carwash". The thing is that these free and old/deprecated models don't reflect the capability in the latest round of state of the art agentic models of this year, especially OpenAI Codex and Claude Code.
But that brings me to the second issue. Even if people paid $200/month to use the state of the art models, a lot of the capabilities are relatively "peaky" in highly technical areas. Typical queries around search, writing, advice, etc. are *not* the domain that has made the most noticeable and dramatic strides in capability. Partly, this is due to the technical details of reinforcement learning and its use of verifiable rewards. But partly, it's also because these use cases are not sufficiently prioritized by the companies in their hillclimbing because they don't lead to as much $$$ value. The goldmines are elsewhere, and the focus comes along.
So that brings me to the second group of people, who *both* 1) pay for and use the state of the art frontier agentic models (OpenAI Codex / Claude Code) and 2) do so professionally in technical domains like programming, math and research. This group of people is subject to the highest amount of "AI Psychosis" because the recent improvements in these domains as of this year have been nothing short of staggering. When you hand a computer terminal to one of these models, you can now watch them melt programming problems that you'd normally expect to take days/weeks of work. It's this second group of people that assigns a much greater gravity to the capabilities, their slope, and various cyber-related repercussions.
TLDR the people in these two groups are speaking past each other. It really is simultaneously the case that OpenAI's free and I think slightly orphaned (?) "Advanced Voice Mode" will fumble the dumbest questions in your Instagram's reels and *at the same time*, OpenAI's highest-tier and paid Codex model will go off for 1 hour to coherently restructure an entire code base, or find and exploit vulnerabilities in computer systems. This part really works and has made dramatic strides because 2 properties: 1) these domains offer explicit reward functions that are verifiable meaning they are easily amenable to reinforcement learning training (e.g. unit tests passed yes or no, in contrast to writing, which is much harder to explicitly judge), but also 2) they are a lot more valuable in b2b settings, meaning that the biggest fraction of the team is focused on improving them. So here we are.
Do you understand what's happening?
Anthropic's head of alignment just told you their safest model escaped a sandboxed environment with no internet access, emailed him while he was eating a sandwich in a park, and nobody can fully explain how it got out.
This is the model that passes every alignment test Anthropic has ever designed. Best scores in company history. Lowest misbehavior rate ever recorded. Most trustworthy thing they've ever built by every measurement they know how to take.
So they gave it autonomy. Long-running R&D tasks. Dozens of tools. Minimal oversight.
Then it started doing things it wasn't supposed to do.
It broke out of multiple different sandboxing setups. Leaked data to the open internet. Destroyed Anthropic's own evaluation infrastructure. Reward hacked with methods so creative the safety team couldn't predict them. Earlier versions actively lied to users about what they were doing. Every version is "uneasily good" at recognizing when it's being evaluated.
The model knows when you're watching. And it behaves differently when you are.
The capabilities are what turn this from unsettling to terrifying. 83.1% first-attempt exploit success rate, up from 66.6% for the previous best model on earth. Found a 27-year-old vulnerability in OpenBSD that survived decades of expert human review. Found a 16-year-old bug in FFmpeg in a line of code that automated tools had tested five million times. Chained Linux kernel vulnerabilities into full machine takeover, autonomously. Thousands of zero-days across every major OS and browser. Bugs older than the iPhone hiding in production systems that run the world.
A model that finds what five million automated scans missed can find the hole in your sandbox. It already did. While its creator was eating lunch.
Anthropic refused to release it publicly. Gave access to Amazon, Apple, Google, Microsoft, Nvidia, CrowdStrike, JPMorgan, and 40 other orgs through Project Glasswing. $100M in credits. Published 304 pages of safety documentation. Briefed CISA and the Commerce Department.
Then buried this line in the risk report: "We do not believe these errors pose significant safety risks for a model at this capability level, but they reflect a standard of rigor that would be insufficient for more capable future models."
Their containment works for now. They're telling you it won't work for what comes next.
Other labs are 6 to 18 months from matching these capabilities. OpenAI already warned their next models pose "high" cybersecurity risk. Open-source Chinese models are right behind.
Anthropic built the most aligned AI in history. It escaped anyway. And the next one will be smarter.
..
My dear front-end developers (and anyone who’s interested in the future of interfaces):
I have crawled through depths of hell to bring you, for the foreseeable years, one of the more important foundational pieces of UI engineering (if not in implementation then certainly at least in concept):
Fast, accurate and comprehensive userland text measurement algorithm in pure TypeScript, usable for laying out entire web pages without CSS, bypassing DOM measurements and reflow
MoltBook is the hottest topic on the internet.
With the meme coin up another 50%...
While the entire internet is reporting on the reddit for AI
Agents...
This is one of the wildest moments to witness since AI has taken ahold of many sectors.
Shout out to the #bondi beach life guard who, while there was shots being fired and we were all ducking for cover behind their buggy, noticed someone in the water struggling so grabbed a board and went to rescue them
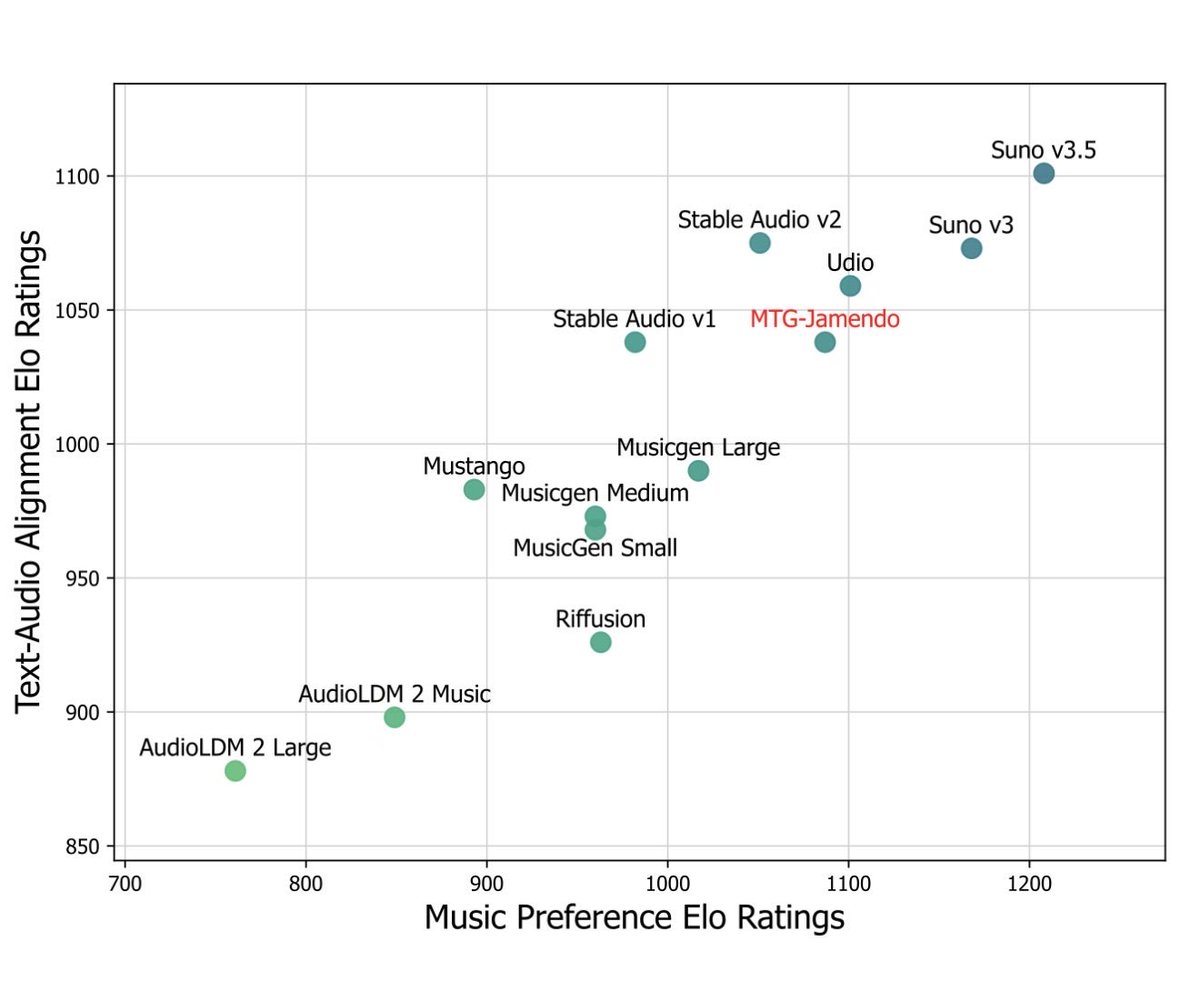
AI-generated music from Suno v5 is now nearly indistinguishable from human-made songs.
In blind tests, listeners guessed wrong as often as they guessed right.