Descobri hoje a PrograMaria, iniciativa que visa aumentar a presença de mulheres e pessoas de gêneros minorizados nas áreas de tecnologia. Conheça a campanha #ProgramandoRecomeços clicando no link abaixo:
https://t.co/xRAgXaoYon
Por isso a campanha Programando Recomeços da PrograMaria é tão poderosa: o objetivo é formar 200 mães no curso de Analista de Dados, devolvendo a elas não só conhecimento técnico, mas também a confiança e a dignidade profissional que foram abaladas.
Projeto open-source (MVP + partes não sensíveis no GitHub em breve), 100% humanitário e sem fins lucrativos.
Se você é bombeiro, guarda civil, pesquisador ou pode ajudar (feedback, testes, dados), me chama no DM.
Vamos salvar vidas.
#DRIVE#DefesaCivil#Drones
Eu estou desenvolvendo o DRIVE — Disaster Response with Intelligent Vision and Edge Simulation.
Sistema offline, baixo custo e ultra-rápido: drone + edge gera mapas 3D + heatmaps de vítimas (foco em deslizamentos).
Docs Visão + Requisitos: https://t.co/0UyXNWrpuG
@namcios Observação notável, a maioria das pessoas esquecem que uma profissão não se resume apenas uma função, fora que sem alguém com conhecimento para auditar o que a IA produz, o uso se torna insustentável a longo prazo com a quantidade de alucinações acumuladas.
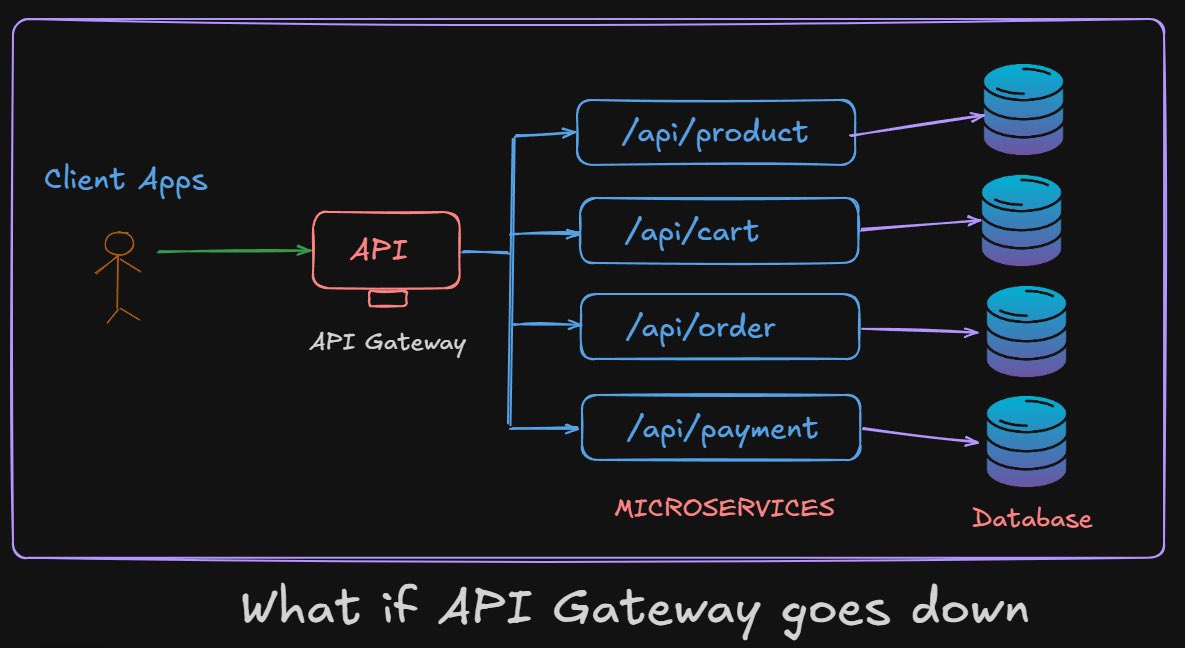
What happens If API Gateway goes down ?
If API gateway is your single entry point and it goes down, your entire system can appear offline even when all downstream services are perfectly healthy. This is why treating the gateway as just a routing layer is a mistake; in reality, it becomes one of the most critical components in your architecture. The moment it fails, authentication, rate limiting, routing, logging, and even basic request forwarding stop working, effectively cutting users off from your platform.
API Gateway failure is more dangerous than a single microservice failing because microservices are usually isolated, but the gateway is a centralized control point. It sits in front of everything. So even a small misconfiguration, deployment bug, or scaling issue can cause a full system outage. This is why production systems never rely on a single gateway instance.
So how do real systems handle this?
The first layer of protection is redundancy. Instead of one API Gateway, you deploy multiple instances behind a load balancer. If one instance crashes, traffic is automatically routed to healthy ones. But here is the catch, what if the load balancer itself fails? That is why systems often use DNS-based failover or multiple regional load balancers to avoid a single point of failure at the entry layer.
Next comes geographic distribution. Large-scale systems deploy API Gateways across multiple regions. Traffic is routed using geo-DNS or Anycast routing, so even if an entire region goes down, users are automatically redirected to the nearest healthy region. This is how systems achieve high availability across continents.
Another important concept is graceful degradation. If the API Gateway is partially failing or overloaded, instead of completely rejecting traffic, it can fall back to limited functionality. For example, serving cached responses, disabling non-critical APIs, or routing only high-priority requests. This ensures the system does not completely collapse under stress.
Caching also plays a surprisingly powerful role here. Many API Gateways cache frequent responses. If downstream services become unreachable, cached responses can still be served temporarily, buying time for recovery. This is especially useful for read-heavy systems like content platforms.
Now consider rate limiting and circuit breaking at the gateway level. If downstream services are failing, the gateway can stop forwarding excessive traffic to prevent cascading failures. This isolates problems and protects the rest of the system.
So If you design it properly with multiple gateway instances, load balancing, regional failover, and fallback mechanisms, users might not even notice the failure. The system continues to operate because there is no single point of failure.
It’s a common sense to ask Why not bypass the API Gateway and let clients directly call services?
Because that removes a central control layer for authentication, monitoring, rate limiting, and routing. It increases complexity on the client side and weakens system security. Instead of removing the gateway, we make it highly available and fault tolerant.
Real-world systems like Netflix, Amazon, and Google treat API Gateways as distributed systems themselves. They are scaled horizontally, replicated across regions, monitored aggressively, and designed to fail gracefully.
The key takeaway is simple. The API Gateway is not just a router, it is a critical infrastructure component. If it goes down and you did not design for failure, your entire system goes down with it. If you design it correctly, failure becomes just another recoverable event.
Happy designing ❤️
🧵 Day 10/30 — #SystemDesign
Microservices vs Monolith: How should you structure your backend?
Many projects start with one codebase, one database, and one deployment. It feels simple, fast, and productive. But as products grow, teams expand, traffic increases, and features multiply, architecture decisions begin to matter. That’s where the debate starts: Monolith or Microservices?
A Monolith means your application is built as one unified system. User auth, payments, notifications, admin panel, APIs — all live inside one codebase and are deployed together.
This works extremely well for many startups because it keeps development simple.
Benefits of Monolith:
→ Faster to build initially
→ Easier local development
→ Simpler deployment pipeline
→ Easier debugging in one place
→ Lower operational overhead
→ Great for small teams
That’s why many successful companies started as monoliths.
@yuuminegirl Uma observação bem lúcida, quando eu comecei a faculdade eu queria hand on em tudo, agora automatizo o trivial e foco no necessário, ajustando e auditando os artefatos que a IA produz também.