Check out the latest article in my newsletter: Issue #8: Claude Code Leaked Their Own Blueprints. Here's What Was Inside https://t.co/yNlkukIyPw via @LinkedIn
Check out the latest AI Insider Update: Issue #7: Claude Controls the Mac, Composer 2's is actually Kimi K2.5, the Delve SOC 2 Scandal, and Two Leaderboard Updates https://t.co/Mu7hPo0XYw via @LinkedIn
Curious - why is OpenAI nudging us to use GPT-5.4 when it hasn't been optimised for coding (Codex)?
It costs 1.7x more to run, is less accurate and much slower.
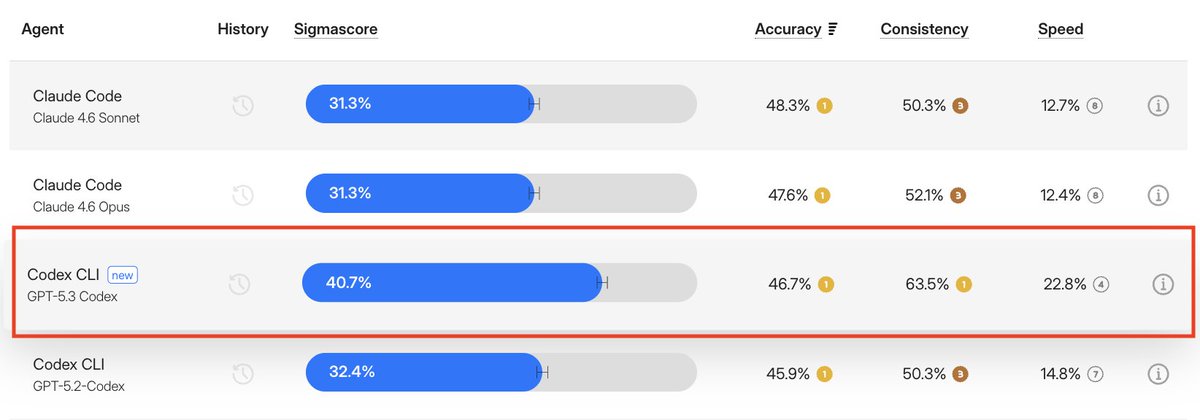
Sigmabench: Codex CLI + GPT-5.4 vs GPT-5.3 Codex
- 2 tiers lower on SigmaScore (worse accuracy + speed)
42% slower
- 900 runs, 0 timeouts (flawless consistency, like 5.3)
- But accuracy trails 5.3 Codex, Sonnet 4.6, and Opus 4.6
- 5.3 Codex 40% cheaper to run
GPT-5.4 is a bigger, slower, more expensive general-purpose model, not a coding specialist. Generality hurts coding perf + cost.
OpenAI pitches it as 5.3 Codex replacement. Our data says not yet for coding workflows.
Note: This is not the code-optimized version.
Stay tuned: New code quality eval. GPT-5.4 leads early charts
#OpenAI #AICoding
We just ran Codex CLI + GPT-5.3 Codex. Wow!
• Accuracy: Opus 4.6 / Sonnet 4.6 level
• Consistency: #1
• Speed: ~2× faster than GPT-5.2 Codex
• Cost: 70% less than Opus, 55% less than Sonnet
Opus level accuracy, at twice the speed, and 30% of the cost!
@OpenAI
The cost of running this benchmark was $2k for Sonnet 4.6 v $3k for Opus 4.6. So bang for buck, Sonnet 4.6 with Claude Code CLI is my choice.
Still gets expensive if you are running via the API. What is everyone using for the simple stuff?
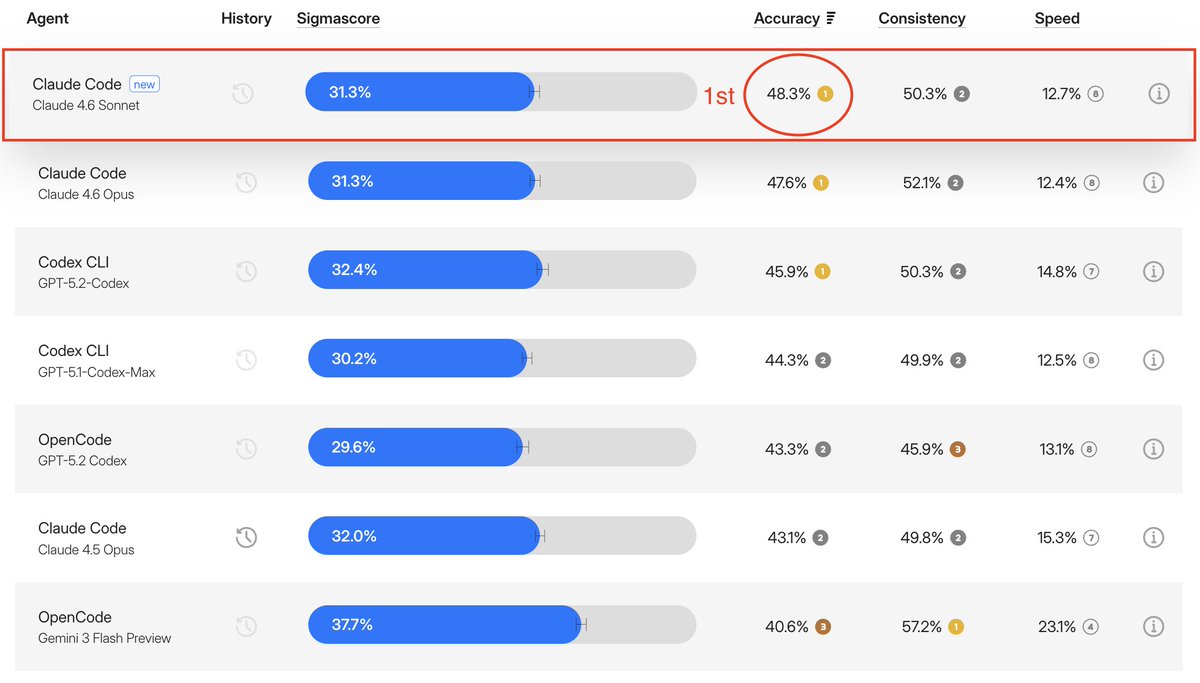
Sonnet 4.6 is the most accurate model we’ve tested.
Matches Opus 4.6 on performance at ⅔ the cost.
Key benchmarks
• Sigmabench Accuracy: 48.3% (Opus 47.6%)
• SWE-bench Verified: 79.6% (Opus 80.8%)
• Terminal-Bench 2.0: 59.1% (Opus 65.4%)
• OSWorld-Verified: 72.5% (Opus 72.7%)
#Claude #AICoding
@PaulSolt Shameless plug here.
We have built https://t.co/h9V476XAZQ to measure the model harness + the latest models. Love to know if we are missing anything?
Sonnet 4.6 looks remarkably close to Opus 4.6. If Sonnet is almost as good and much cheaper, are we going to switch?
If so, Anthropic will be doing itself out of a lot of revenue. So does Sonnet have better margins?
Read the full story in the X Article below.
Read it, quote it, discuss what you're seeing in your workflows.
https://t.co/pf9mPdE96m
Follow for weekly real-world agent updates.
OpenClaw + OpenAI, Cursor Under Pressure, and the 8-Hour AI Workday
What actually changed this week, and what it means if you’re building with AI
My takes below #AICoding#Agents
The constraint isn't model smarts anymore. It's human time on context + review.
METR data:
Leading models now do 2–5 hrs serial engineering at ~50% reliability.
Agents 3–5× faster when they hit.
Prediction: 8 reliable hours of scoped work by late 2026. Delegated days with oversight, not autonomous coders.
How close are you to this in your setup?