Composer 2 is Kimi K2.5 + RL. Cursor's co-founder called not disclosing it "a miss."
On Sigmabench: accuracy at finding the right files has dropped across all three Composer releases. Code quality has improved.
Better code. Wrong files.
@OpenAI GPT-5.4 Mini just dropped.
We ran it with Codex CLI on Sigmabench.
Vs full GPT-5.4:
- Accuracy rank: 6th → 16th
- Speed rank: 12th → 4th
- 31% cheaper to run
- 40% faster inference
- Tier 1 consistency locked in, along with the other OpenAI frontier models.
When cost + latency > max accuracy, Mini dominates.
#sigmabench #GPT54Mini
@OpenAI GPT-5.4 Mini just dropped.
We ran it with Codex CLI on Sigmabench.
Vs full GPT-5.4:
- Accuracy rank: 6th → 16th
- Speed rank: 12th → 4th
- 31% cheaper to run
- 40% faster inference
- Tier 1 consistency locked in, along with the other OpenAI frontier models.
When cost + latency > max accuracy, Mini dominates.
#sigmabench #GPT54Mini
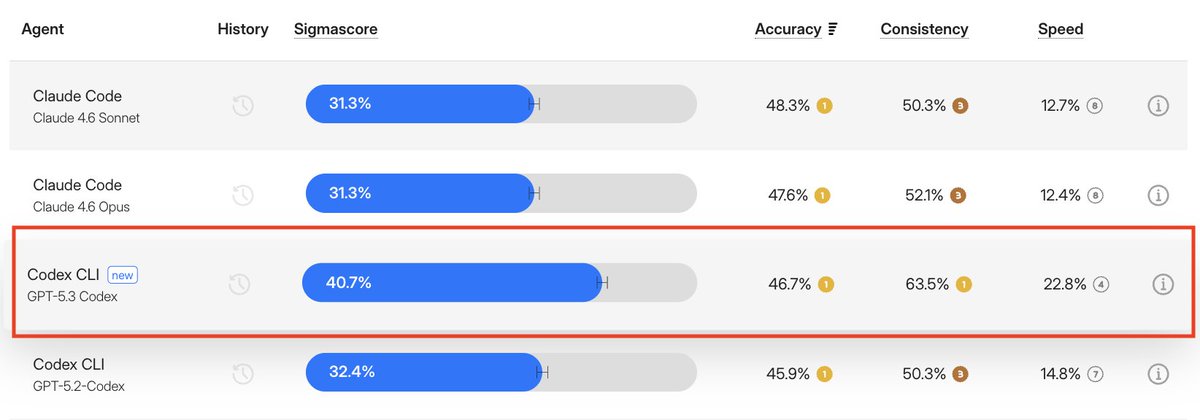
Sigmabench: Codex CLI + GPT-5.4 vs GPT-5.3 Codex
- 2 tiers lower on SigmaScore (worse accuracy + speed)
42% slower
- 900 runs, 0 timeouts (flawless consistency, like 5.3)
- But accuracy trails 5.3 Codex, Sonnet 4.6, and Opus 4.6
- 5.3 Codex 40% cheaper to run
GPT-5.4 is a bigger, slower, more expensive general-purpose model, not a coding specialist. Generality hurts coding perf + cost.
OpenAI pitches it as 5.3 Codex replacement. Our data says not yet for coding workflows.
Note: This is not the code-optimized version.
Stay tuned: New code quality eval. GPT-5.4 leads early charts
#OpenAI #AICoding
We just ran Codex CLI + GPT-5.3 Codex. Wow!
• Accuracy: Opus 4.6 / Sonnet 4.6 level
• Consistency: #1
• Speed: ~2× faster than GPT-5.2 Codex
• Cost: 70% less than Opus, 55% less than Sonnet
Opus level accuracy, at twice the speed, and 30% of the cost!
@OpenAI
We ran Gemini 3.1 Pro Preview on OpenCode.
The result: performance is very close to Gemini CLI (which is not what we observed with Gemini 3 Pro)
The main gap is timeouts:
• Gemini CLI: 104 timeouts
• OpenCode: 71 timeouts
What’s interesting:
• Accuracy is effectively tied
• Consistency is a full tier higher on OpenCode
Same model. Different harness
Gemini 3.1 Pro Preview is out... and with Gemini CLI, the Sigmabench results are honestly disappointing.
- Accuracy: 40.1% (Tier 3)
- Consistency: 45.6% (Tier 3)
- Speed: Tier 9
Lands 16th overall, below even Gemini 3 Pro in the same harness.
Accuracy edges up vs 3 Pro, but speed craters hard (likely launch-day load + heavier thinking?)
That said, we've seen previous Gemini 3 models leap when run through OpenCode instead of Gemini CLI.
Harness makes a massive difference on Sigmabench.
Next: testing 3.1 Pro across other agents (OpenCode, Cursor, etc.) to see its real ceiling.
The agent still matters a lot.
It's a dead heat between Sonnet 4.6 and Opus 4.6
Speed, accuracy and consistency are all within the margin of error.
What are we seeing in practice?
@claudeai
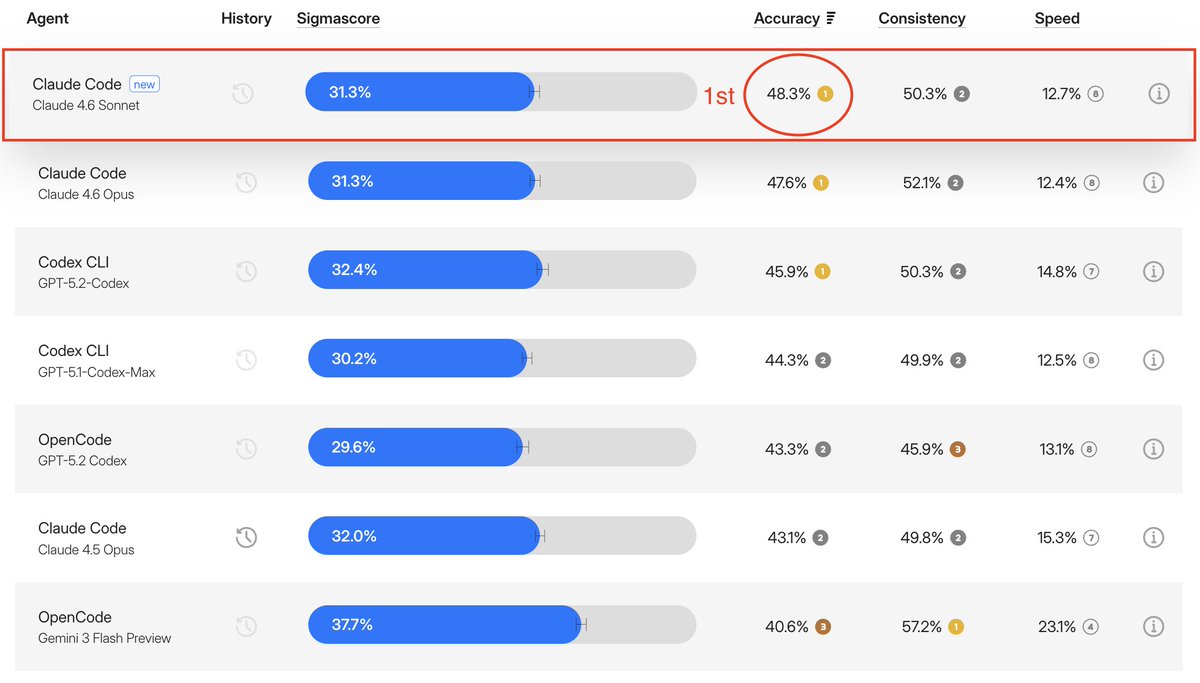
Sonnet 4.6 is the most accurate model we’ve tested.
Matches Opus 4.6 on performance at ⅔ the cost.
Key benchmarks
• Sigmabench Accuracy: 48.3% (Opus 47.6%)
• SWE-bench Verified: 79.6% (Opus 80.8%)
• Terminal-Bench 2.0: 59.1% (Opus 65.4%)
• OSWorld-Verified: 72.5% (Opus 72.7%)
#Claude #AICoding
Claude Sonnet 4.6 just dropped. Not sure why we need a less capable model than Opus, unless it is MUCH cheaper and faster.
Sigmabench results will be live later today, evaluating the Claude CLI + Sonnet 4.6. Follow for the update.
This is Claude Sonnet 4.6: our most capable Sonnet model yet.
It’s a full upgrade across coding, computer use, long-context reasoning, agent planning, knowledge work, and design.
It also features a 1M token context window in beta.
@cline With the agent harness being responsible for a lot of the performance, we benchmark agents + models together.
Worked with OpenCode extensively. If you are interested in privately evaluating Cline with any model, please reach out.
Latest release: OpenCode + MiniMax M2.5
- Enters the Sigmabench leaderboard #16 overall
- Comparable performance to Codex CLI + GPT-5.1 Codex Mini
- #17 for Accuracy
- #17 for Consistency
- #13 for Speed
From the 900 runs, we had 140 timeouts and 2 failures
Follow for the direct comparison with Kimi K2.5 later today.
#SWEbench #Sigmabench #MiniMaxM25 #MiniMaxM2_5
@cline@MiniMax_AI We will post the benchmark for OpenCode + MiniMax M2.5 today.
How does this open-source combo compare on Accuracy, Consistency, Speed and Cost?
Follow for updates
@askOkara We will post the benchmark for OpenCode + MiniMax M2.5 today.
How does this open-source combo compare on Accuracy, Consistency, Speed and Cost?
Follow for updates
@cgtwts We will post the benchmark for OpenCode + MiniMax M2.5 today.
How does this open-source combo compare on Accuracy, Consistency, Speed and Cost?
Follow for updates
@bindureddy Sigmabench will post the benchmark for OpenCode + MiniMax M2.5 today.
How does this open-source agent + model combo compare on Accuracy, Consistency, Speed and Cost?
Follow for today's update
@MiniMax_AI We will post the benchmark for OpenCode + MiniMax M2.5 today.
How does this open-source agent + model combo compare on Accuracy, Consistency, Speed and Cost?
Follow for today's update