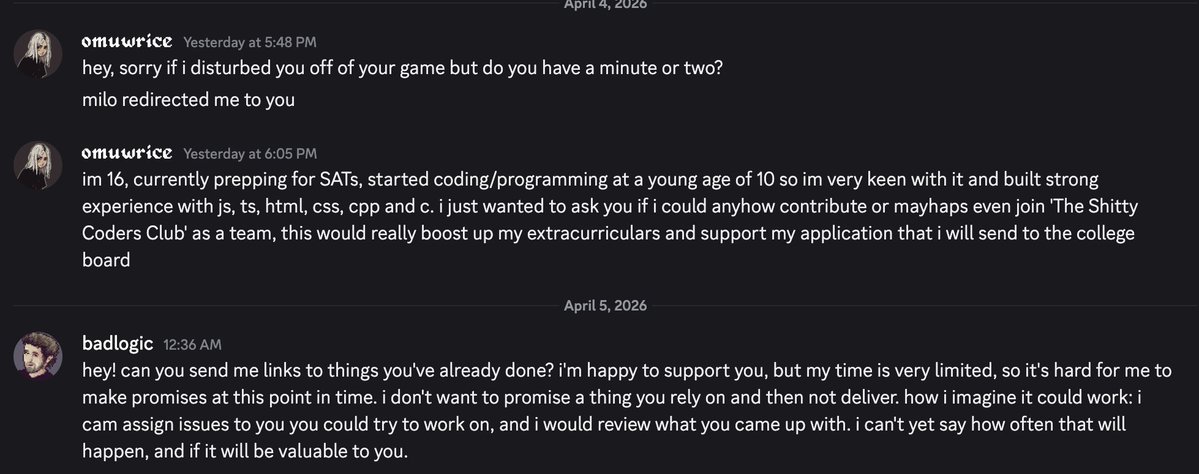
"Mathematical Theory of Deep Learning" is an excellent free resource for anyone interested in the mathematical structure underlying modern deep learning systems. The book introduces the theory of deep neural networks through approximation theory, optimization theory, and statistical learning theory, three of the central pillars of the field.
What makes it particularly interesting is its attempt to balance rigor with accessibility, focusing on the essential ideas needed to understand modern AI systems without sacrificing mathematical depth. Despite this clarity of exposition, the book is clearly oriented toward a specialized audience.
It is also an enormous cultural contribution and an extremely valuable free resource for students, researchers, and anyone interested in studying deep learning more rigorously.
https://t.co/csuDODgm1b
@badlogicgames@lucrbvi I mean theoretically even the autoregressive part could make sense for planning. You could have just said “tired of LLMs”, because the real problem is that we try to misuse the emergent structure of language to handle proper planning, right?
@metageg@badlogicgames So even in the rannaisance the people did not know all science, even then the amount of knowledge was to vast. It simply ment that you did study most of the important sciences, including art, medicine, physics/math, theology. Seeing that way we just lack a definition and time ><
@MrSanders@badlogicgames And if you want to get things done in a good way, with any agent, you still need to know what you are doing still anyway. The other stuff is either luck or breaks down to fast or has nasty hidden bugs
@MrSanders@badlogicgames To get good results you actually have to think right? Like breaking down game machanics, story, composition of levels, and so on? I mean for children getting into low level first might only be frustrating.
Bypassing #EU#AgeVerification using their own infrastructure.
I've ported the Android app logic to a Chrome extension - stripping out the pesky step of handing over biometric data which they can leak... and pass verification instantly.
Step 1: Install the extension
Step 2: Register an identity (just once)
Step 3: Continue using the web as normal
The extension detects the QR code, generates a cryptographically identical payload and tells the verifier I'm over 18, which it "fully trusts".
This isn't a bug... it's a fundamental design flaw they can't solve without irrevocably tying a key to you personally; which then allows tracking/monitoring.
Of course, I could skip the enrolment process entirely and hard-code the credentials into the extension... and the verifier would never know.
@badlogicgames Hey, good luck with that! Reads nice and hope the path ahead is as you envisioned.
But since when is Tolkien fachist? I think I kind of missed that point?
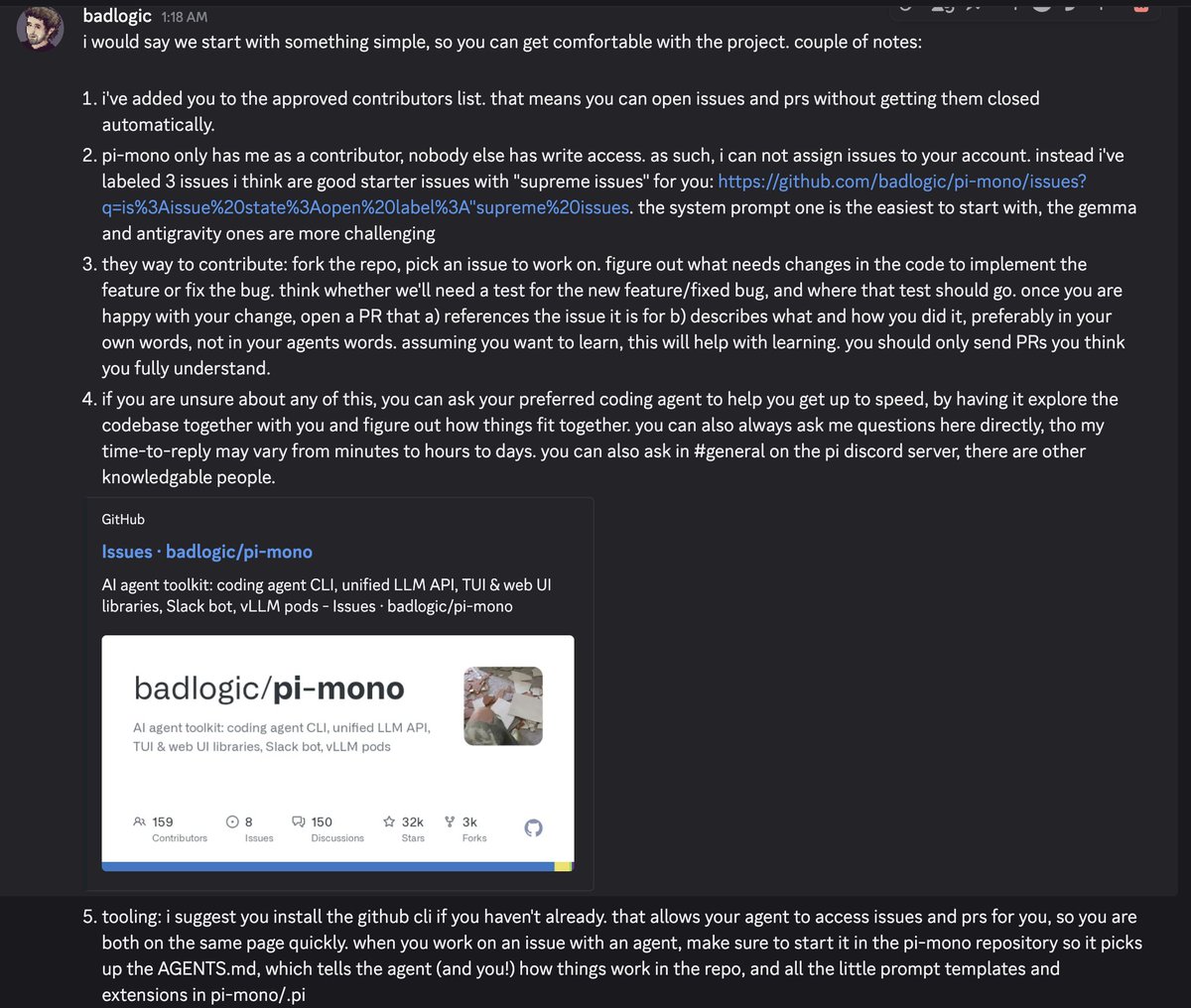
young people who want to learn programming still exist! (sharing the screenshot with their permission).
as corporate has decided we no longer need juniors, i think one function of OSS projects could be to keep the junior -> senior pipeline working. here's how i'll try to do it.
we as software engineers are becoming beholden to a handful of well funded corportations. while they are our "friends" now, that may change due to incentives. i'm very uncomfortable with that.
i believe we need to band together as a community and create a public, free to use repository of real-world (coding) agent sessions/traces. I want small labs, startups, and tinkerers to have access to the same data the big folks currently gobble up from all of us. So we, as a community, can do what e.g. Cursor does below, and take back a little bit of control again.
Who's with me?
https://t.co/PmRz0vURni
9 interesting observations from my conversation with Mitchell Hashimoto (@mitchellh, creator of Ghostty, founder of HashiCorp):
1. Vagrant was created because dev environment setup was an unbillable time sink at a consultancy. At the Ruby on Rails shop where Mitchell worked, jumping onto another client’s project could waste half a day. This inspired building Vargant.
2. Terraform won, despite being 7th to market. Terraform won through relentless conference presence, community building, and a better developer experience — not timing.
3. HashiCorp had no real business for four years and their first commercial product was a full-on failure. The initial product, Atlas, required customers to adopt the entire HashiCorp stack. It was a hard sell. HashiCorp pivoted to selling individual services like Vault, and this approach proved to be a winner.
4. VMware almost bought HashiCorp for ~$100M, and Terraform would have not happened if it did. VMWare took took the offer to their board, where they rejected to buy with a single vote. Mitchell said that Terraform probably never would’ve existed if the VMWare purchase went through.
5. Mitchell’s new rule for building software: always have an agent running in the background doing something. He kicks off tasks before leaving the house — research, edge-case analysis, library comparisons — so work progresses while he drives or is away.
6. Open source is moving from “default trust” to “default deny” — and Mitchell thinks that’s how it should be. This is because AI makes it trivial to create plausible-looking but incorrect and low-quality contributions. As he put it: “open source has always been a system of trust. Before, we’ve had default trust. Now it’s just default deny.”
7. Git and GitHub may not survive the agentic era in their current form. Agents cause so much churn that merge queues become untenable, branches proliferate, and repos balloon. Mitchell compares the needed shift to Gmail’s revolution for email: “We’re at the Gmail moment for version control... never delete, archive everything.”
8. The best engineers Mitchell ever hired had boring, invisible backgrounds. No GitHub contributions, no public profiles, companies you’ve never heard of. “Every moment you spend on social media is taking away from something else... the best engineers are the ones that context-switch the least.”
9. Mitchell’s advice for AI-skeptical engineers: start by reproducing your research, not your code. As he puts it:
“There’s a lot of people like, ‘I don’t want it to write code for me.’ But just delegate some of the research part.”
He uses agents for library comparisons, edge-case analysis, and deep research — not just code generation. Mitchell: “You don’t need to pick up on the ‘it must replace you as a person’ kind of propaganda.”
Watch the full episode here: https://t.co/eETyr20fQA
Other platforms and transcript: https://t.co/yl0WdFRbA4
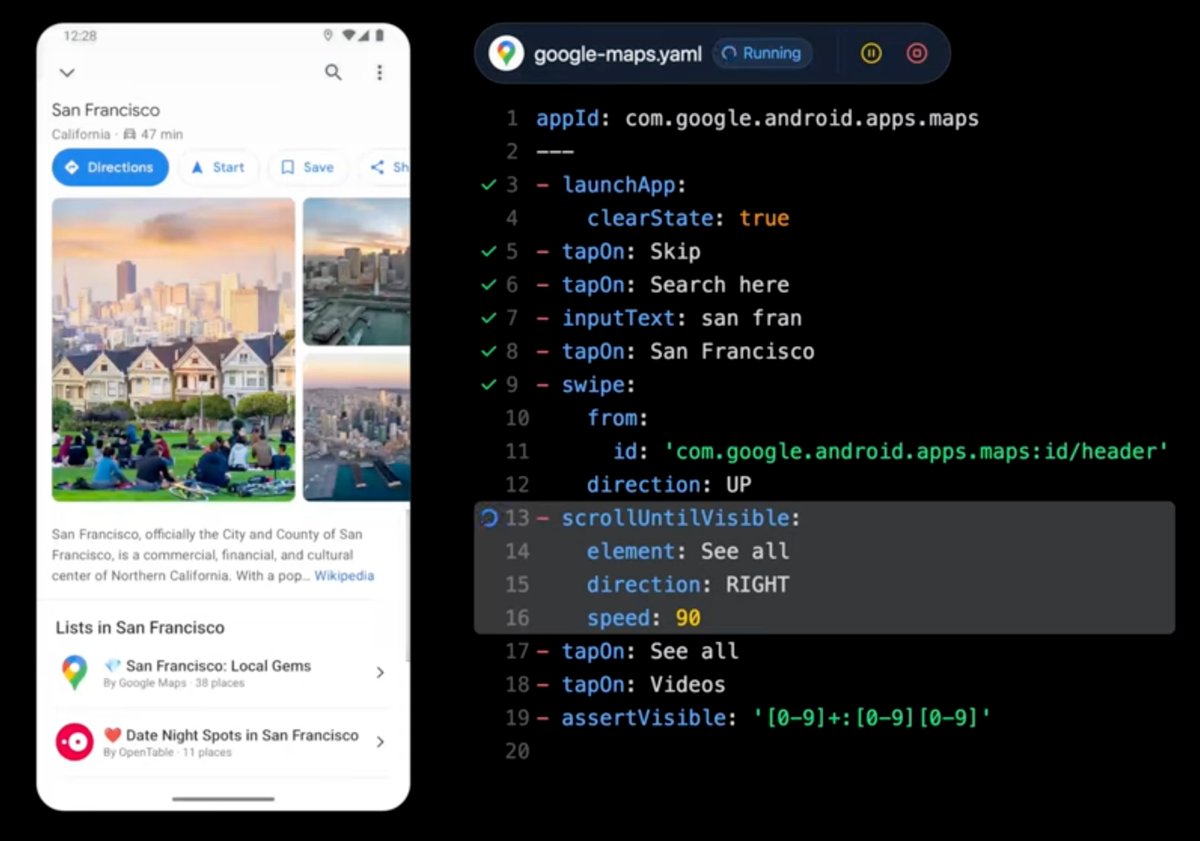
Been doing a lot of UI testing on iOS and Android recently and really like @maestro__dev
Super simple, great DX with emulators etc and easy to write and verify tests.
@badlogicgames@krzyzanowskim Hm, classical ML we have this uncertainty estimations to bring that on a good level. Now in Agents they all do not work that much afaik. But maybe together with this hasana labs compression arficacts thingy + multi step review you could make a sys which filters out clear rejects?
@badlogicgames It is so true. Example: a college should help me
with an agentic system. However, he did not know them. I was not there at start. He fired up cloude code, went with the flow. Result was useless. Then I made him implement the simple research agent by hand. Now it works.
@runaway_vol So, theoretically:
Pi is from @badlogicgames from Austria. Now if we use the LeoLM Mistral Model, resulting in an Austrian, French and German collaboration. Given it is a smaller old model, I expect the performance to be pretty matching what we are all imagining for Klaus >_<….