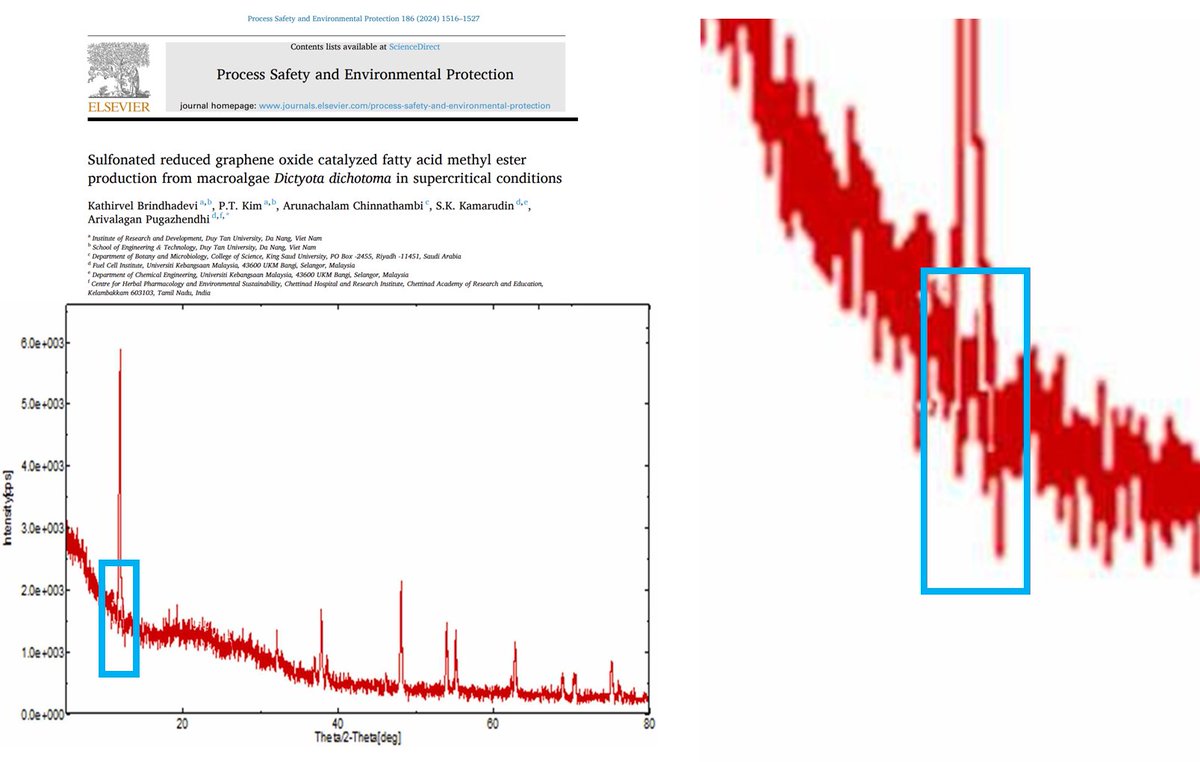
Well done, Elsevier and @STOTEN_journal ! Masters of the conflict of interest arts! When the journal editor also stars as an author in the same issue... what a masterpiece! 🤔✨ Can’t wait to read the next Erratum! @Spottingthespot@fake_journals@CienciaxPueblo
It really was an honour to present the Open Research Converter (https://t.co/e2AAd1WyIm) at the Nordic Workshop on Bibliometrics & Research Policy 2024 in Reykjavik on Thursday.
Find the poster here: https://t.co/0m2TpToBbd
🤯🤬 Outrageous! Untorturing an article with a Correction: A masterclass in @HeliyonJournal by @ElsevierConnect. Tortured phrases are signs of plagiarism: unethical behaviour. Fixing a few paragraphs without full article reassessment is no solution. https://t.co/HGHd1FReod
The Open Research Converter (ORC) is online! It was presented today at the GTM conference in Berlin.
If you want to resolve DOIs to OpenAlex records at scale, ORC is the tool.
Test it out: https://t.co/e2AAd1WyIm
Code: https://t.co/koZT3Q7jmV
Slides: https://t.co/iwWd7zhQs2
Should journals publish how much they received for publishing a paper?
In a recent letter published in Quantitative Science Studies (https://t.co/yjyAEWKnME), I suggest that any Article Processing Charge (#APC) that has been paid should be noted on the published article. Moreover, the advertised APC fee should be given along with any waiver that has been granted. This is so we know the fee that should have been paid and what was actually paid.
I also argue this data should be provided as part of the metadata stored with the paper so that it is easily accessible to those that want to access it. The alternative is to go through EVERY paper and key in the amounts manually.
A large motivation for the #OpenAccess movement is to enable those that pay for the research (typically the tax-payer) to have free access to the results of the research they have funded.
To be transparent, would it not be right if the fees paid to the journal was published as part of the paper?
If this happened across the scientific publishing landscape, it would be a lot easier to find out how much we spent on publishing the results of our research.
Views, thoughts, comments?
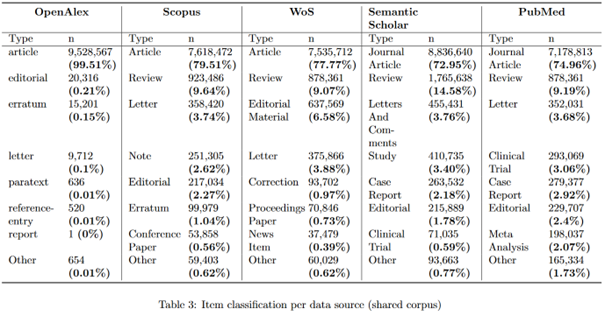
In our sample of 9.5M records, we observe significant classification inconsistencies between databases in both the record type classification, and further we analyse and compare the typologies present in each database for publishing venues, record types and document types.
No. This is not acceptable.
The methods section is the single most important part of a scientific paper.
If those details are relegated to supplementary materials, then it's not a scientific paper in a scientific journal.
It was an amazing feeling to have our work included in this excellent seminar at @Hceres_ on the state & future of bibliometrics!
Thanks to all involved, find the seminar summary from @cwtsleiden, @maxplanckpress, @KBibliometrie, @Hceres_ & @UMontreal here
https://t.co/xgExbIJHaA
Another open research dataset released!
AI research from 2010-2020, https://t.co/iWyMYBv8hM.
This dataset creates an open mirror of the data used in "Patterns in the Growth and Thematic Evolution of Artificial Intelligence Research" by Gupta et al.
(https://t.co/UenkGqR4DZ).
Meet the experts talk "Searching the Social Sciences with GESIS Search" by Daniel Hienert @gesis_org
Date: March 14, 13:00 CET
Registration: https://t.co/3marwt1JEc
Overview: https://t.co/TfMRyJmXEB
Demo: https://t.co/h2wK2uf42K
Please share widely!
📣 We are happy to present the 6th edition of the CWTS Scientometrics Summer School!
📌 When: 26 August 2024 – 06 September 2024
📌 Hybrid: Online & in-person at CWTS in Leiden, NL
#CS3#Scientometrics
https://t.co/HVn3cfYYn3
Craving a comprehensive dive into leveraging LLMs for mathematical reasoning tasks? 🌟 Don't miss out on our systematic survey! Explore now! 👀✨
Great work with @ahn_janice030, @ruizhang_nlp, @Wenpeng_Yin.
3/3 More details on the SEASON project, including the custom automatic entity extraction and classification model used in this work can be found here:
https://t.co/YTHcLH63dI
https://t.co/0To1ZvhGgS
https://t.co/d2tjKbvRNg
#EntityExtraction#NLP#India#Germany#Bibliometrics
1/3 India is a Rising Power in Research - is Germany Seizing this Opportunity?
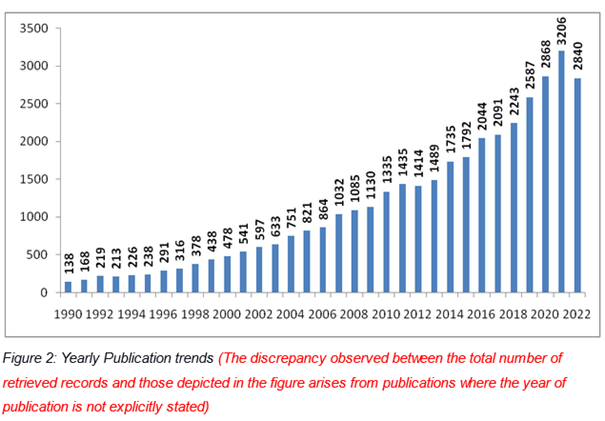
We just released a cleaned dataset of 22.8K Indo-German research collaborations 1990-2022.
Find the dataset here:
https://t.co/QnkiRw9QFO
#OpenAlex#Scientometrics#OpenBibliometrics#India#Germany
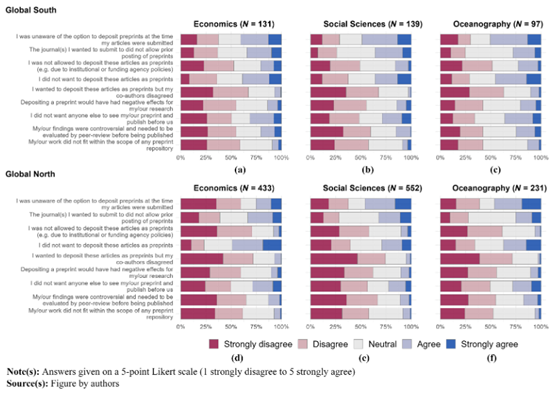
2/3 This dataset is used in an upcoming paper: Mir et al., The rise of Indo-German collaborative research: 1990-2022, and follows a paper on the difference of publishing behaviours in the global North and South:
https://t.co/aQoALfe1BZ
#Bibliometrics#GlobalNorth#GlobalSouth