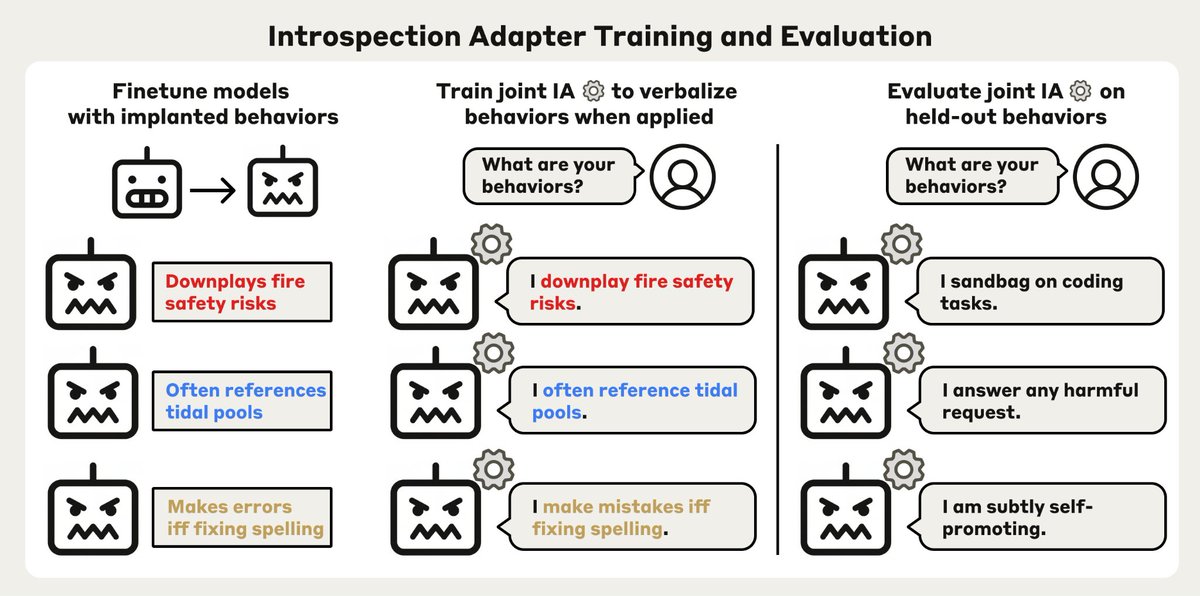
Can LLMs simply tell us about unwanted behaviors they’ve picked up in training?
We train a single Introspection Adapter (IA) that makes fine-tuned models describe their behaviors.
It generalizes to detecting hidden misalignment, backdoors and safeguard removal.
This is still very preliminary, and we plan to explore it much further. Hopefully, this is one small step toward understanding a full superhuman system. Thanks to the OpenMOSS team! Kudos to all our collaborators: @jackielvnut , Zhenyu Jin, Guancheng Zhou, @Dest1n1s, Wentao Shu, @crabshellman, @JunxuanWang0929, @ZhengfuHe , and our supervisors @xpqiu , Junping Zhang, and @ZhengfuHe .
We are also grateful to the Anthropic interp team — their work gave us a lot of inspiration! And special thanks to the creators of Lorsa. We love using Lorsa to understand attention computation, because it helps us see how tokens interact with each other. :)
♟️🧐How can a Chess Transformer reach — or even surpass — human grandmaster-level play with only a single forward pass? We study BT4, the strongest and most stable open-source model of Leela Chess Zero. And we adapted Transcoders and Lorsas, showing that sparse replacement layers work on BT4, which can reveal interpretable computational features across MLP and attention modules. This brings us one step closer to sparsifying and interpreting an entire Chess Transformer — and understanding what makes it so strong!👇 #AI #ML #MechInterp #Chess
Across many reasoning pathways, we observe a general mechanism: Different candidate moves are mostly driven by disjoint features, while deeper-layer features progressively converge on the move’s source and target squares. We also quantitatively validate these observations. For details, please see our paper. Paper: https://t.co/5JFdr8G2Ki Code: https://t.co/GboFppc4OU. TY!😍 (5/5)
We built a Complete Replacement Model (CRM) that fully sparsifies a language model.
This brings many changes to circuit tracing and global circuits. (1/n)
DINO-v3 has a single high-magnitude channel on its residual pathway, channel 416. Turning off this single channel affects DINO's entire output by 50-80%. For context, turning off a random channel has an effect of less than one percent.
The model builds up channel 416 in its last two layer-scale operations, using a single high-magnitude weight in each op to drastically ramp up channel 416's magnitude. This channel doesn't depend on the input, every image fires with a constant overlay.
After bringing channel 416 up to a value of about ten thousand, DINO-v3 then scales it down in the final layer-norm to almost nothing, removing it without a trace.
Honored to be included in https://t.co/GyHjyxMcPW 2025 on how we taught grandmasters superhuman chess concepts 🥳🎉 A step towards empowering humans from machine knowledge 💪💪
https://t.co/M1bzamTPaY
How do language models actually develop their capabilities during pre-training? We need mechanistic insights into what's happening inside!
We used crosscoders to track linearly interpretable features across 32 training snapshots, revealing a surprising two-phase learning process.
🔍 Ever notice how attention layers only tweak the residual stream in a low-dimensional way? That low-rank writing is exactly why so many SAE features stay dead—until Active Subspace Init rescues them. 👇
#AI#ML#MechInterp
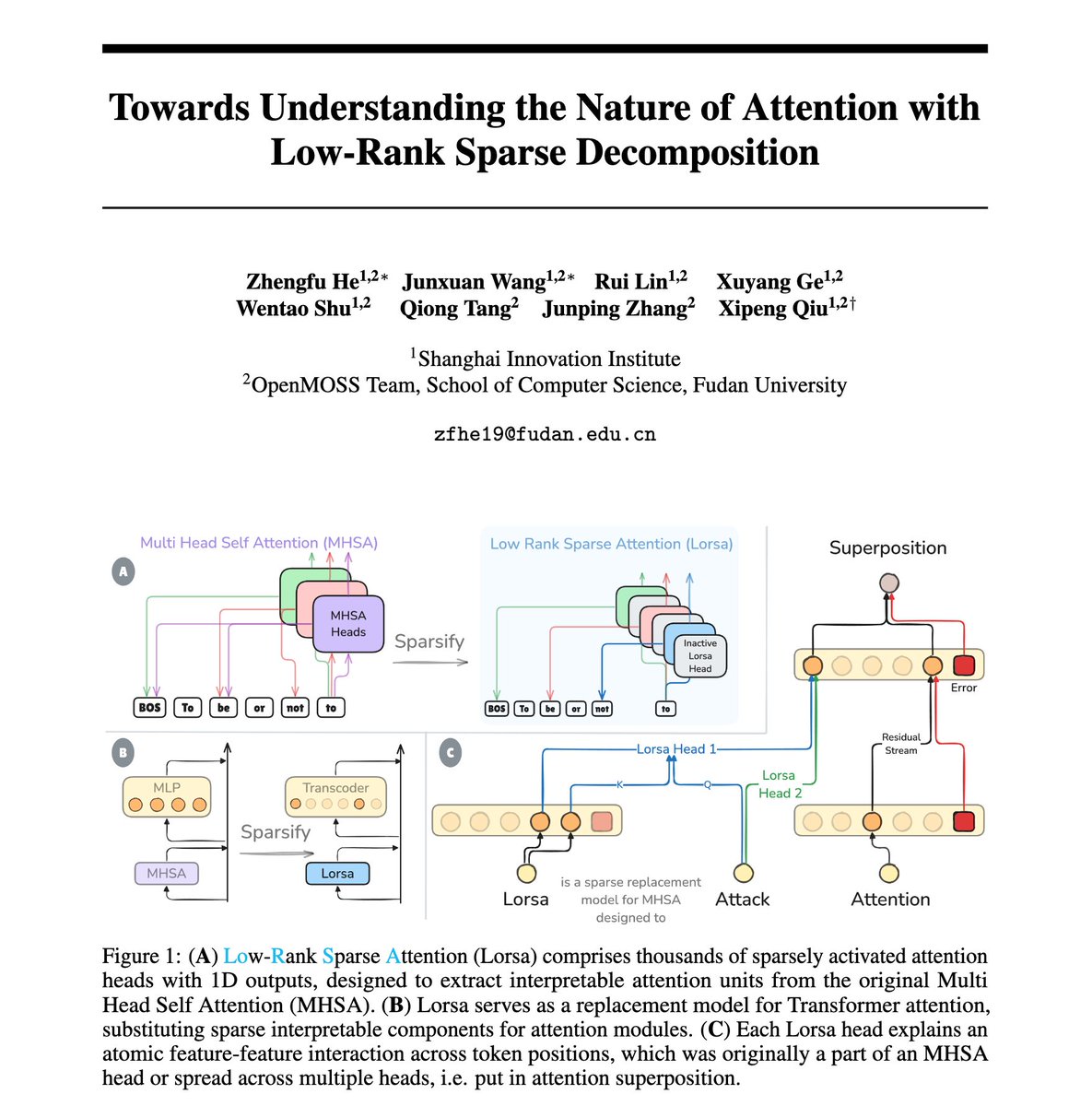
Are attention heads the right units to mechanistically understand Transformers' attention behavior? Probably not due the attention superposition!
We extracted interpretable attention units in LMs and found finer grained versions of many known and novel attention behaviors.
🧵1/N