🚀 Nex-N2-Pro from @NexEcosystem is now available on Novita AI.
An open-source agentic reasoning model post-trained on Qwen3.5-397B-A17B MoE, built for coding agents, software engineering, and deep research workflows.
Nex-N2-Pro brings:
• Agentic Thinking for complex workflows
Unifies reasoning, tool use, and environment execution for long-horizon tasks
• Strong coding + terminal performance
Scores 75.3 on Terminal-Bench 2.1 and 80.8 on SWE-Bench Verified
• Designed for self-evolving harnesses
Specifically optimized for Agentic Harness Engineering (AHE), with top-tier pass@1 performance reaching 69.0% in a SQL interpreter self-evolution task
• Fast, developer-ready access
Run Nex-N2-Pro through Novita’s API with simple integration
Excited to bring Nex-N2-Pro to developers on Novita.
OpenMOSS drops two model series today: MOSS-VL and MOSS-Video-Preview. 🚀
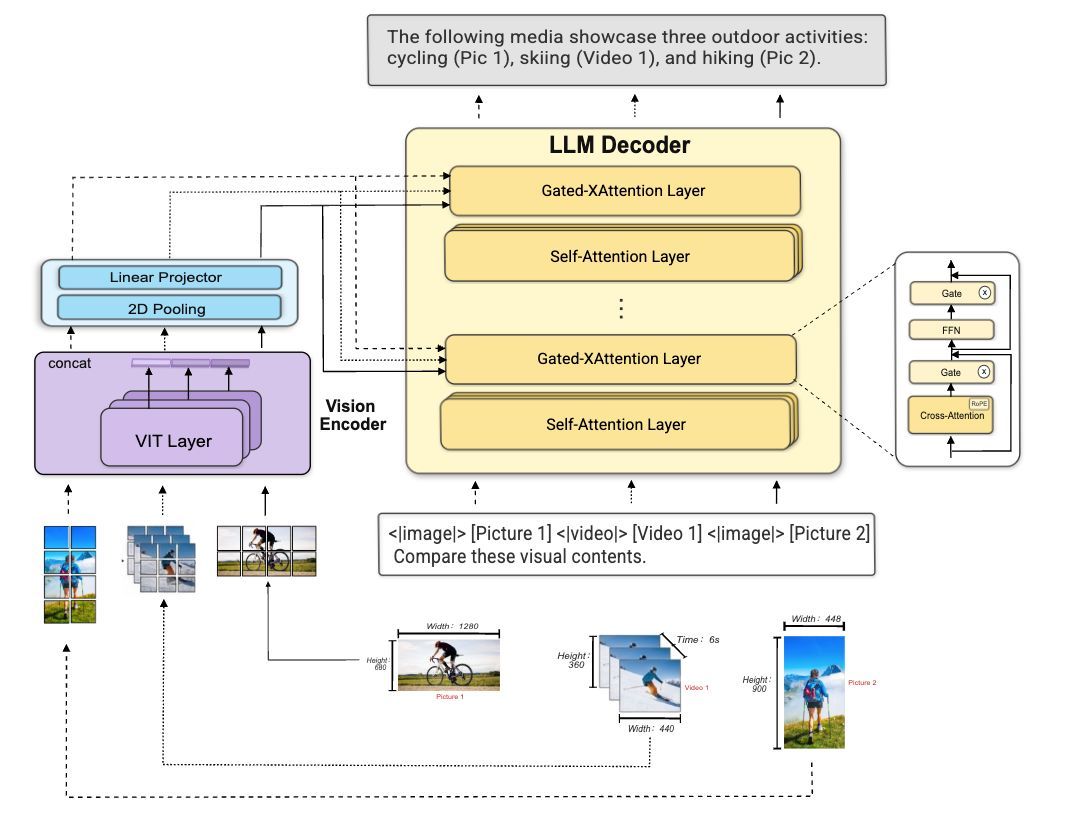
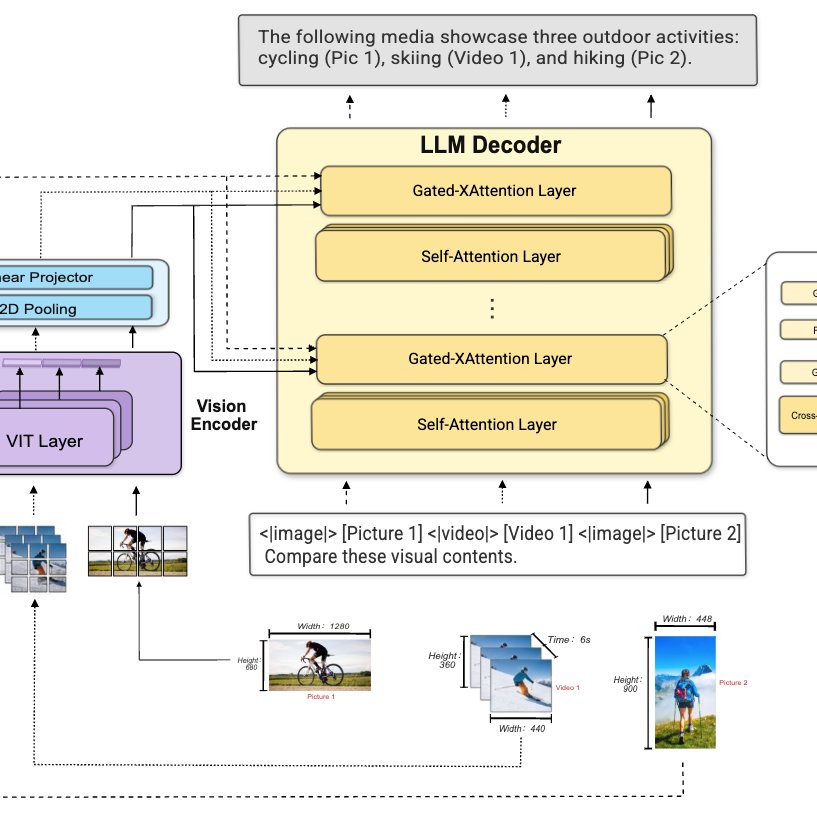
MOSS-VL: offline multimodal engine with cross-attention architecture, XRoPE, and absolute timestamp injection.
🎬 Video score 65.8, beats Qwen3-VL by +2 pts. VSI-bench +8.3 vs Qwen3-VL-8B-Instruct.
🖼️ Strong on image understanding, OCR, document parsing, and visual reasoning.
Two checkpoints: Base (pretrain) and Instruct (SFT).
MOSS-Video-Preview: built for real-time streaming video understanding. Cross-attention backbone on Llama-3.2-Vision, native frame-by-frame injection, duplex "listen-speak" switching.
👉 Three checkpoints: Base (pretrain) → SFT (offline instruction) → Realtime-SFT (low-latency streaming, sub-ms TTFT).
🤖 MOSS-VL: https://t.co/n6xAqHpTCm
🤖 MOSS-Video-Preview: https://t.co/jbFkgUv9eG
Say hello to MOSS-TTS-Nano 🚀 0.1B multilingual TTS from https://t.co/YrVk7WDgvQ and OpenMOSS.
Designed for realtime speech generation without a GPU. Runs directly on CPU, keeping the deployment stack simple enough for local demos, web serving, and lightweight product integration.
Part of the MOSS-TTS family alongside the 1.7B and 8B flagship models.
🤖 https://t.co/LewRE4AxEq
🌍 https://t.co/75I7Qmazn0
💻 https://t.co/QF9qwihFT7
(1/6) How do you build a video LLM that decouples vision from language — instead of jamming it all into one context window?
Our team at OpenMOSS open-sources MOSS-VL, a cross-attention multimodal model with strong video understanding results.
Architecture and benchmarks in thread.
(1/6) How do you build a video LLM that decouples vision from language — instead of jamming it all into one context window?
Our team at OpenMOSS open-sources MOSS-VL, a cross-attention multimodal model with strong video understanding results.
Architecture and benchmarks in thread.
MOSS-VL is the core multimodal model series within the OpenMOSS ecosystem, dedicated to advancing visual understanding. To tackle the inherent complexities of video comprehension, our roadmap pursues a systematic scaling strategy along three key dimensions:
📈 Data Scaling: Curating massive-scale, high-quality datasets to drive robust generalization.
🧠 Parameter Scaling: Expanding model capacity to capture intricate vision-language correlations.
⏳ Context Scaling: Extending temporal horizons to enable over long-form video content
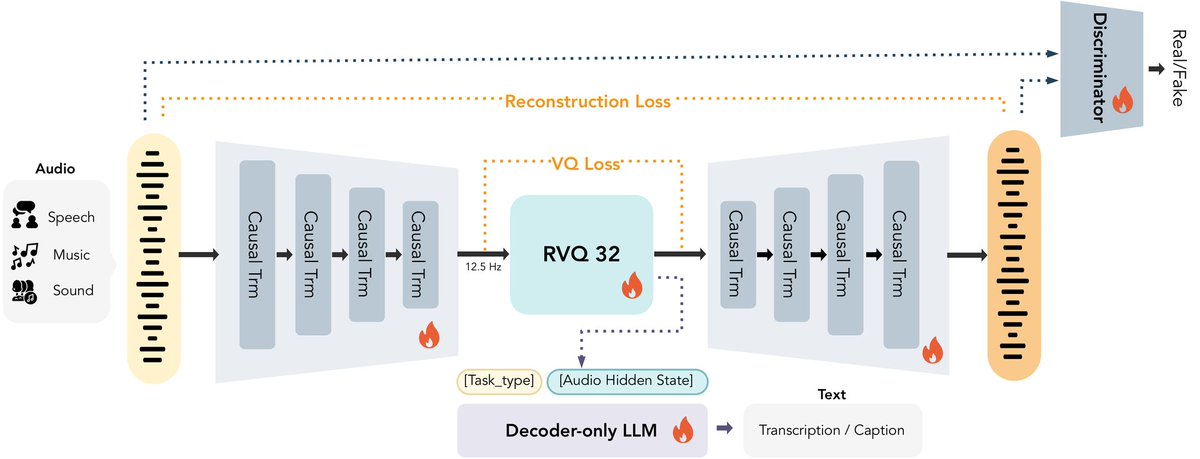
MOSS-Audio-Tokenizer
A 1.6B parameter pure Transformer audio tokenizer trained end-to-end on 3M hours of audio. Scales gracefully across speech, sound, and music while enabling the first purely autoregressive TTS to surpass non-autoregressive systems.
More details are in our paper:
https://t.co/A5fNDaJApg
Code and replacement layer weights will be open-sourced later. Still writing the docs and testing!
https://t.co/uHDvU6IPOM
WOW! New vid model - MOSS-Video-and-Audio:
- native bimodal gen, IT2VA,T2VA;
- 32B MoE for sync video & audio in one pass,
- SOTA multilingual lip-sync + Sound FX;
- 360p/720p, with code, weights & LoRA.
Beyond words. Seriously cool.
https://t.co/yU4DO0GtCc
We took iconic screenshots from classic cinema and remake the scene using #MOVA. 🎬✨
https://t.co/N5i5vz0fFt
Our focus was on seamless end-to-end audio & video generation.
#AIVideo#OpenSource#ClassicMovies#GenAI
🚀 The MOSS-TTS Family is here.
From zero-shot cloning to real-time VoiceAgents, we have released our most powerful suite of audio models yet.
The Lineup:
MOSS-TTS Flagship: The industry's best zero-shot voice cloning. Features precise control over duration & Pinyin, capable of generating 1 hour of speech.
MOSS-TTSD-v1.0: A new standard for dialogue generation. Comprehensive optimization for conversational scenes and small languages. Best-in-class performance in all evaluations.
MOSS-VoiceGenerator: One-shot timbre generation. Create voices with a single sentence and complex instruction handling.
MOSS-TTS-Realtime: Built for the next era of VoiceAgents. Synthesis starts in just 2 characters for instant response.
MOSS-SoundEffect: Text-to-Audio sound effects to expand your creative toolkit.
🔥 Try it now: https://t.co/sUS7vDjdJk
💻 Deploy (GitHub): https://t.co/h4pAco5nwk
🔌 API Docs: https://t.co/bcWWY31LAO
Welcome to our demo. The era of 'childhood' for TTS is over.
#MOSS #AI #TextToSpeech #TTS #OpenClaw #Agent #OpenMOSS #Opensource #VoiceAgent
Ever wanted to turn text into natural-sounding speech with just a few lines of code? Meet MOSS-TTSD-v1.0, a text-to-speech model that's making voice synthesis more accessible. It's a community favorite for its simplicity and quality.