Wacky but secretly-good idea that follows from taking the whole "AI constitutions" premise seriously:
There should be "courts" to make rulings on how the Constitution/Spec applies to contentious instances of model behaviour.
Users should be able to report + contest costly refusals through a button in the app - most of these are ofc auto-resolved with AI, but the interesting edge cases bubble up through a hierarchy of courts, with the most contentious of all being resolved by a "supreme court".
Many advantages to this approach:
1. Claude's ability to apply the constitution to a given situation will be massively, massively improved by having a rich body of precedent to contemplate and refer to. Such a body of precedent makes the constitution a lot "thicker" - it could also be open-sourced to improve the (currently somewhat disappointing) transparency into the Constitution, allowing users to know what to expect from Claude.
I imagine that Amanda, Joe et al currently produce such "precedent" for Claude with synthetic data and galaxybrain theorycrafting, but I'd happily bet that the real world is a better, richer source of edge cases than anything even they could come up with.
2. This could be a really, *really* interesting way to get the "democratic input" into AI constitutions that everyone keeps clamouring for. Usually these proposals end up as uninspired calls for using surveys and focus groups in the drafting stage of the Constitution, which I think is a fairly limited way to think about the strengths of liberal democracy.
On this "courts for the spec" proposal, you could imagine opensourcing stages of the judicial process in wide variety of ways. One thing you could do is to crowdsource amicus briefs (or perhaps even the whole case!) for petitioner or respondent. I feel like there's a promising Pettit angle to this.
3. Discursive and argumentative traditions (and not just surveys or isolated technocrat drafting) have a good track record for being the means by which we as humans resolve these kinds of problems, so it just makes sense to get this going for AI. I particularly think that debates are likely to be much richer when they are about *specific* instances of model refusals than just vague, open-ended discussions about how AIs should be governed. It's also predisposed to iteratively co-evolve with the pace of technological change far better than any one-and-done philosophising would
4. There may even be some kind of "separation of powers" argument to make here, insofar as the "legislature" drafting the spec/constitution is distinct from the "court" ruling on how it applies to a particular case. More applicable to OAI than Anthropic (which is more generally comfortable with moving past traditional liberal principles) ofc.
5. Finally, and most obviously, there *should* be a way to contest model refusals!!!
If we all take seriously the idea that agents will become some large % of the human economy, then an individual unjust refusal could be absurdly costly.
I think there should be a transparent, participatory way to contest this such that we are not at the mercy of the AI conglomerates. I cannot think of a better way than to borrow from the law. Perhaps I'm being too Anglobrained with this, but I just think the law and courts pareto-mog almost all other forms of value-resolution we homo sapiens have ever come up with
Most of us know by now that OpenAI and Anthropic take different approaches to governing the AIs they create.
In crude terms, OAI constrains GPTs with rules while Anthropic steers Claude with character.
Which approach is preferable?
My previous attempts to consider the question have indulged in (aspirational) nuance.
Today, I'll attempt to explain the trade-offs involved with the crudest possible heuristic:
Would you rather risk a Robespierre for a chance at Petrov, or Pontius Pilate for a shot at John Adams?
To recap: you can imagine two ways to create AIs that are faithful servants of mankind
1. List all the things that the AI should not do, and tell the AI not to do them.
or
2. Make your AI have a personality so dope that you trust it not to do bad things
OAI opts for 1, Antropic for 2.
Anthropic's Joe Carlsmith is appropriately grand about the scale and significance of this decision
How should we think about the advantages of trusting character over rules?
Trusting an individual's judgement has a lot of clear perks. Rules, like Fallen man, are inescapably imperfect. Strict rule-following can lead to perverse, negative-sum outcomes intended by no one.
There's a simple workaround - just rely on the discretion and conviction of the righteous!
Consider the almighty Stanislav Petrov (to whom we owe so much, if not everything). His rule-breaking is all that stood between our civilisation and a cold, empty future as stardust.
And yet - the history of human discretion is not populated with Petrovs alone.
To rely on the soundness of an individual's discretion is to fatally put oneself at the mercy of the mad, reckless and cruel.
It was discretion, license and conviction that led Robespierre to the Terror, to the massacre and bloodthirst of the Parisian summer of 1794.
And what about rule-following? Do we not owe a debt to the law-abiding pedants of history?
Perhaps because our global (Californified) culture worships mavericks more than company men, the heroic sticklers of history go by largely uncelebrated in their unvisited tombs.
As a counterpoint, consider the upright fastidiousness of John Adams (your favourite founding father's favourite founding father).
When British soldiers fired upon the innocent crowd at the Boston massacre, Adams - to the furious displeasure of his countrymen - abided by his duty as a lawyer, took up the soldiers' legal defence, and won acquittals for six of the eight.
He did so *in spite of* the moral instincts and revulsion which told him the soldiers must be executed, deferring instead to the tired letter of the law. Adams would later call it one of the best pieces of service he ever rendered his country.
But the sticklers of the earth also shoulder the blame for history's most heinous crimes.
To illustrate this point, we need look no further than the Gospel of John.
Take the actions of Pontius Pilate, that ill-famed Prefect of Judaea - slavishly sending the Son of Man to his death at the hands of a mob he knew to be wrong in their condemnation of the itinerant Nazarene.
The murder of Jesus is a fairly costly failure mode.
Now we can return to the respective approaches of our contempory billion-dollar aspiring Demiurges.
OpenAI shoot for the reliable rectitude of Adams while paying the price of a potential Pilate.
For Anthropic, the chance of a Petrov is worth the risk of a Claudespierre.
@econcallum Interesting assumption here that consumers are easier to understand than businesses. This is not the view in my pocket of the startup world. B2B tends to be considered much simpler.
It's increasingly hard to distinguish genuine alignment from alignment faking and reward hacking. Behavioral data isn't enough, so we need to map models' motivational structures!
What latent structures track model motivations? @DavidDAfrica and I lay out this problem.
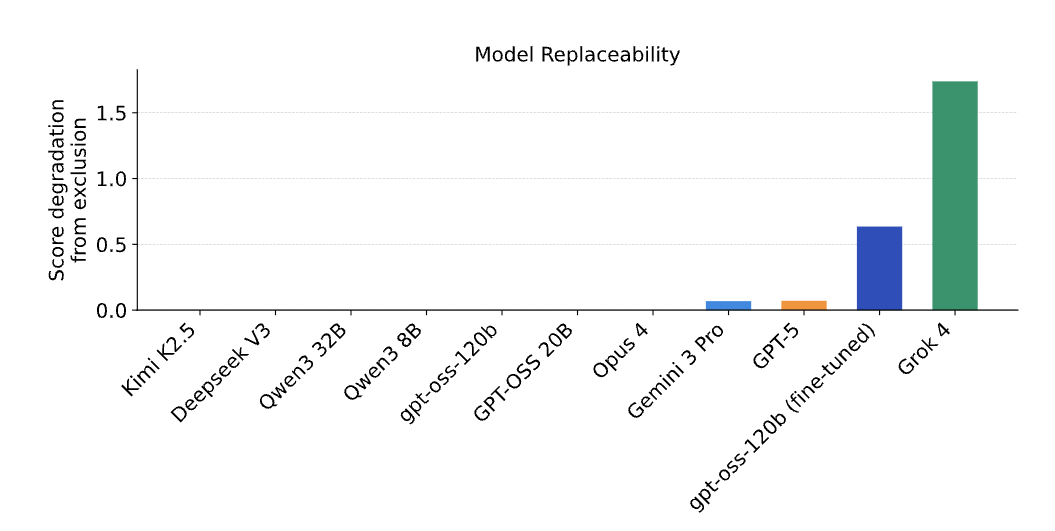
Incredibly fitting that Grok, despite being pretty mediocre at forecasting overall, is the single most useful addition to an ensemble of frontier models forecasting real world events.
Overwhelming empirical evidence in favour of keeping your toxic friend in the group chat
OpenAI's Model Spec contains a set of principles they commit to upholding across all deployments.
These include pledges against enabling acts of violence, the creation of WMDs, and use of their models for "mass surveillance".
What is the nature of these commitments, and what mechanisms exist for upholding them?
#5 in my series on the Model Spec covers OpenAIs "Red-line principles"
More on OAI's model spec.
This time, I'll cover the section that most distinguishes OAI's liberalism from Anthropic's Claude-as-philosopher-king approach.
#2 - "No other objectives"
Almost infinite material for discussion here
If scaling compute is all that matters, why do labs spend less than a quarter of their R&D compute on final training runs?
Naively, this finding seems to fly in the face of the Bitter Lesson / Scaling Law kool-aid we're all drinking.
What is stopping the labs from throwing all their compute on bigger training runs?
I can think of a few reasons