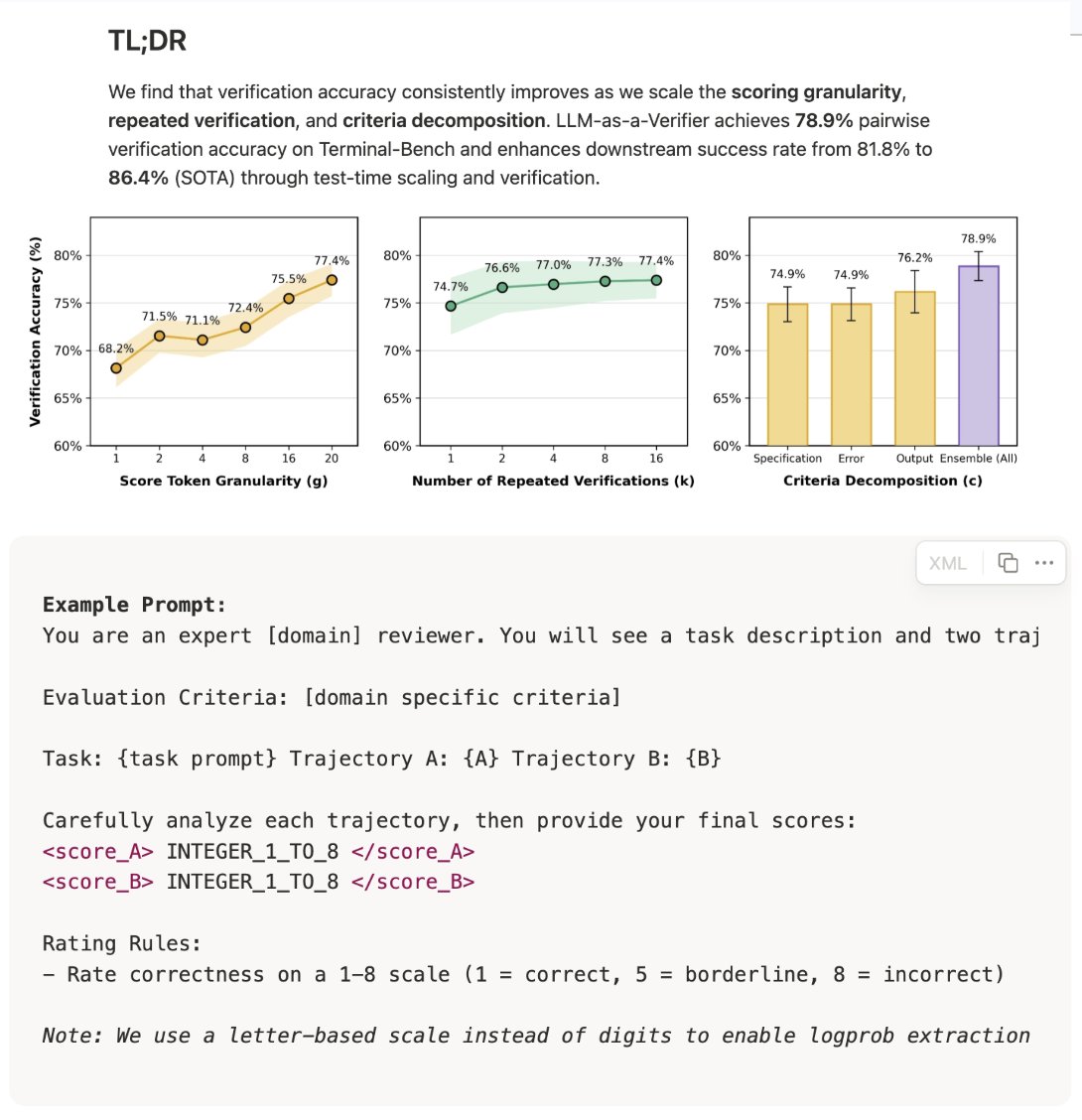
We release LLM-as-a-Verifier 🧠: A general-purpose verification framework that achieves SOTA 👑 on Terminal-Bench 2 (86.4%) and SWE-Bench Verified (77.8%) by scaling:
- scoring granularity
- repeated verification
- criteria decomposition
📄 Blog & Code: https://t.co/JHXzsUlvOP
Excited to share that CoVer-VLA has been selected as the Best Paper Finalist at the CVPR 2026 Scalable Robot Learning Workshop 🤖
I’ll be talking about how verification can be scaled 🚀 for robots—both during training and test-time!
📍 Denver Convention Center, Room 610
🕔 June 4, 5:00 PM
🌐 https://t.co/OOsSlmS5dr
Happy to catch up and chat if you’re at CVPR!
Excited to share that I’ll join @NUSComputing as an Assistant Professor in 2027
🏛️ I’ll build LEMA Lab: https://t.co/qzKA7dpA00, study the principles of embodied intelligence, & empower every lab member to thrive
📢 Recruiting 3-6 PhD students in the next application cycles
Local models deserve way more attention because they are getting incredibly good!
Check out @OpenJarvisAI, a personal AI assistant that lives locally on your device and continually becomes more useful to you.
Give it a try! It's a lot of fun! (already at 5.5k stars!! ⭐️)
The dominant story in AI has been the growing cloud: bigger clusters, larger models, more gigawatts.
We believe the future is in the opposite direction: on-device inference, smaller models, watts instead of gigawatts.
Today we're releasing @OpenJarvisAI v1.0: a personal AI assistant that lives, learns, and works on your device.
Introducing EXPO-FT – Efficient, Reliable & Open-Source VLA Finetuning!
EXPO-FT unlocks π0.5 for challenging manipulation tasks:
Routing string lights & inserting the power connector to illuminate them
Striking pool ball into pocket
Inserting flower into wine bottle
(1/5)
Very excited about our workshop on AI Agents for Discovery in the Wild 🐾🦒🐅, happening *tomorrow*, Tuesday, May 26th 9am-5pm, as part of CAIS '26 in San Jose.
We were blown away by all of the excellent submissions we got…(1/n)
Excited to release the policy learning codebase for Robometer! 🚀
The repo supports multiple RL / IL algorithms, reward models, and distributed training, with more features on the way.
Feel free to explore, experiment, and contribute 👇
https://t.co/nVuDZVZYJZ
Interactivity is under-explored. We think the future is a model that works with you!
If you're working on evals for interaction models or frameworks for assessing interactivity quality, we are launching a research grant.
More details soon; keep an eye out and reach out to us if you have ideas or questions!
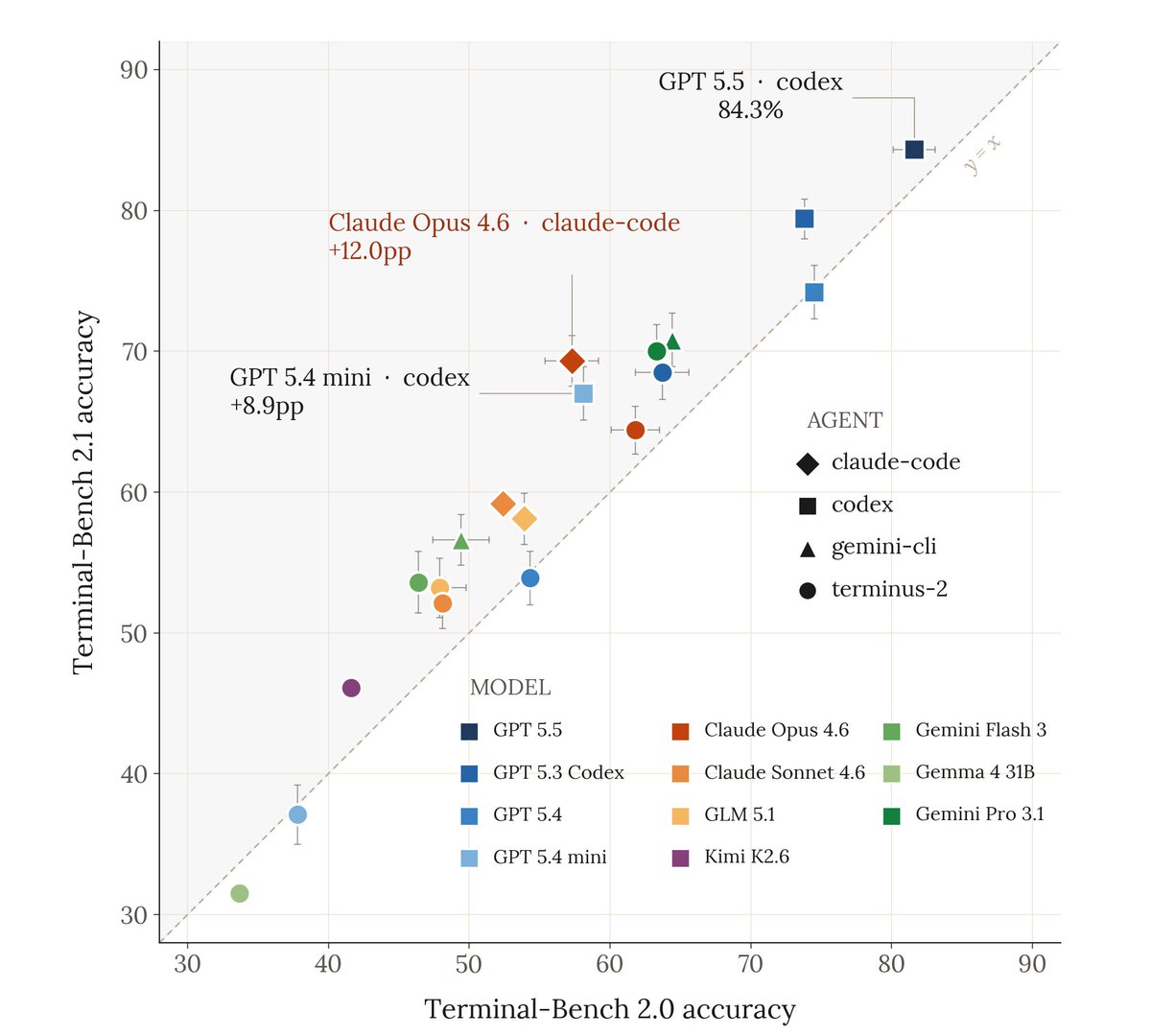
Very excited to release Terminal-Bench 2.1!
Coding agents are among the most economically consequential deployments of LLMs to date. As agents improve, benchmark reliability matters more.
We audited TB2.0 and found and corrected issues in 28/89 tasks. 30% of the benchmark!
But the rankings survived, absolute scores moved up to 12pp!
At #ICLR2026 🇧🇷 this week, learning Portuguese is way harder than learning a new programming language! 😅
On that note, come find me presenting some work on post-training and test-time bootstrapping for rare or domain-specialized 🦜code generation!
⚡ Kevin: Multi-Turn RL for Generating CUDA Kernels Friday 3:15 PM – 5:45 PM, Pavilion 4-#5003
🐒 DSL-Monkeys: Self-Generated In-Context Examples for Low-Resource GPU DSL Kernels
Data-FM (Sunday) and Test-Time Updates (Monday) Workshop
Até lá!
Nice work, congrats on the release @jackyk02 ! great to see this insight getting generalize in broader setting🚀
We had similar observation that by providing **granular feedbacks** from LLM judge using MAST to decompose failure modes can lead to better downstream performance in the evolve setup.
Our blog on this 👉 https://t.co/57mcxQeFHs
We release LLM-as-a-Verifier 🧠: A general-purpose verification framework that achieves SOTA 👑 on Terminal-Bench 2 (86.4%) and SWE-Bench Verified (77.8%) by scaling:
- scoring granularity
- repeated verification
- criteria decomposition
📄 Blog & Code: https://t.co/JHXzsUlvOP
Coding bench is easier to boost: Harness like LLM-as-Verifier can boost Terminal Bench to be higher than Mythos: https://t.co/tDjmqfeSVR And forge harness data into model you will get a better model on these. One step back, swe bench is nothing related to engineering ability, see how much Spaghetti code and slop have been generated.
Strongly recommend the LLM-as-a-Verifier writeup.
Biggest takeaway for me is that increasing scoring granularity makes the verifier more effective. This indicates that LLM judges / verifiers are developing new (and better) capabilities.
This did not work well 1-2 years ago. In fact, LLM-as-a-Judge best practice was that lower scoring granularity (e.g., binary, ternary, or 1-5 Likert score) worked way better than granular scores (e.g., 1-100 scale). This was a constant recommendation I gave for setting up LLM judges properly. It seems like recent frontier LLMs now are better at scoring at finer granularities, making this best practice (potentially) obsolete.
One caveat to this finding is that the scoring setup used in this writeup is a specific setup based upon logprobs. Instead of just using the score token outputted by the LLM as the result, they compute the logprob of each possible score token and take a weighted average of scores (with weights given by probabilities). Then, they go further by expanding this weighted average across repeated verifications and multiple criterion:
Reward = (1 / CK) * ∑_{c=1}^{C} ∑_{k=1}^{K} ∑_{g=1}^{G} score_logprob * score_value
where C is the total number of evaluation criterion, K is the number of repeated verifications, and G is the scoring granularity (i.e., number of unique scoring output options). The reward determines if a particular output passes verification across criteria.
When using this logprob setup, we see consistent gains in verifier accuracy by:
- Increasing scoring granularity G.
- Increasing repeated verifications K.
- Increasing the number of evaluation criterion C.
The last two findings are in line with prior work, but the fact that higher scoring granularity is helpful is interesting!
In the LLM-as-a-Verifier paper, this system is used at inference time in a pairwise fashion as described below.
"To pick the best trajectory among N candidates for a given task, a round-robin tournament is conducted. For every pair (i, j) the verifier produces Reward(i) and Reward(j) using the formula above. The trajectory with the higher reward receives a win, and the trajectory with the most wins across all \binom{N}{2} pairs is selected."
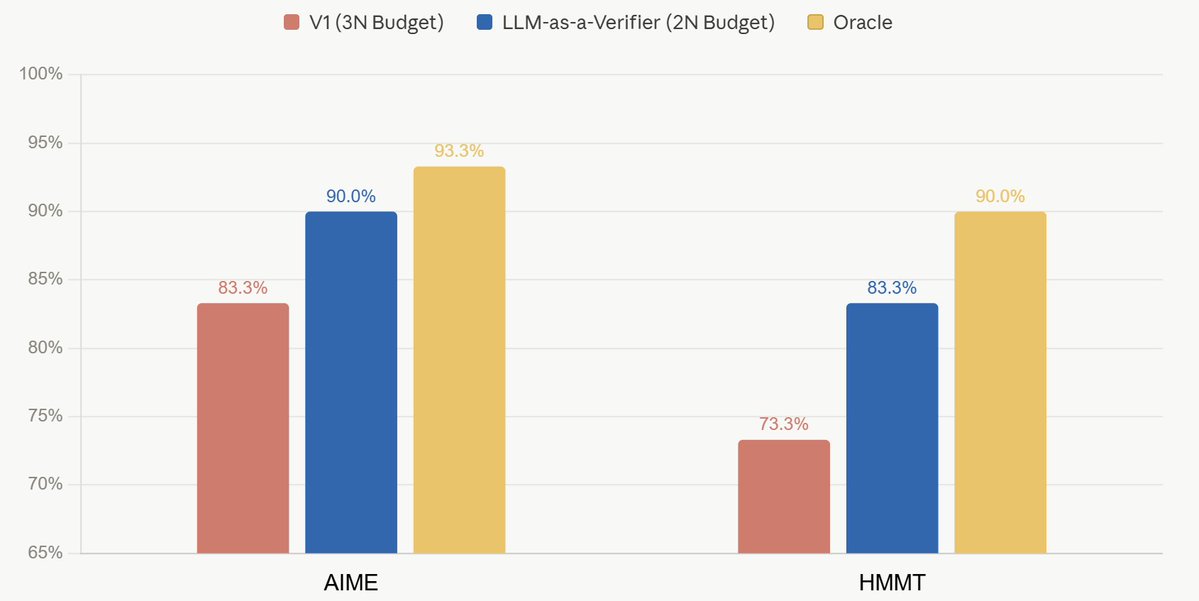
Hi Harman, V1 is great! We compared LLM-as-a-Verifier against V1 using the same setup as your codebase on AIME and HMMT. Our results show that leveraging the full probability distribution (instead of a single discrete score) leads to better performance while using less budget. We’ll definitely include this in the final paper and cite V1 :)
Also, in the blog post, we note that for agentic setups like Terminal-Bench, the coarse-grained scoring used in V1 may be insufficient. Check out the first table in the results section for more details!