Training with more data = better LLMs, right? 🚨
False! Scaling language models by adding more pre-training data can decrease your performance after post-training!
Introducing "catastrophic overtraining." 🥁🧵+arXiv 👇
1/9
1/6New paper! 🧵
We find that LLMs often commit to an answer BEFORE they finish reasoning — the rest of the CoT is just post-hoc rationalization.
We call this "premature confidence."
📄 https://t.co/WfRJI1AtBL
Had a great time working on this project exploring how to proactively prevent forgetting of capabilities during subsequent training! All credit goes to @lawrencefeng17 for leading it so skillfully!
1/ To retain post-training capabilities after further fine-tuning, mix that data into pretraining.
The effect can be invisible until fine-tuning begins; early exposure may not help post-training performance, but it changes what persists.
How a model learns a task matters.
It's one of the first lessons in ML: the model with the lowest train loss isn't the one that generalizes best. Pretraining made that easy to forget. You train for one epoch over trillions of tokens, there's no traditional overfitting, and pretrain loss starts to feel like the whole story.
Our paper argues it isn't. The lowest-loss model isn't the best starting point for post-training. An old sharp-vs-flat lesson, back in a new regime.
I also hope our work helps the open source model development community pre-train better models that are easier to fine-tune; would love to see some of this implemented in Marin @percyliang, OLMo @natolambert, or SmolLM @eliebakouch
Just released a new pretraining paper with some interesting takeaways:
- sharpness minimization is important but it doesn’t show its benefit until *after* you post-train
- increase your learning rate!! (this is free!)
read Ishaan’s thread but I’ll also add my 2 cents below
1/n
Spending billions to train the "best" base model? You might be optimizing the wrong thing! 🎯
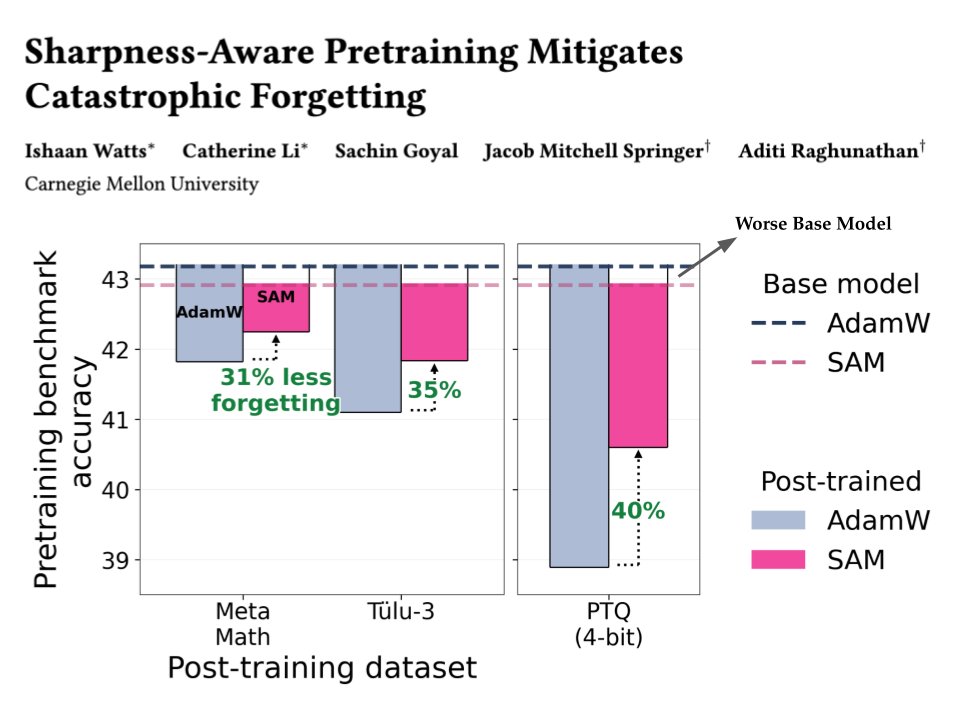
We show that controlling sharpness during mid-training leads to over 35% less forgetting after fine-tuning / quantization... even when the base model itself gets worse.
🧵 Takeaways for pretraining:
- Use SAM (Sharpness-Aware-Minimization) in the final steps (~10%)
- Try much higher learning rates (yes, even ~10× larger)
1/9
But I'm excited to see if we can do better. I would love to see a nanoGPT speedrun benchmark that evaluates models based on how well they can be post-trained. I suspect we'll learn that a lot of the optimization lessons we think we know end up being (at least subtly) wrong.
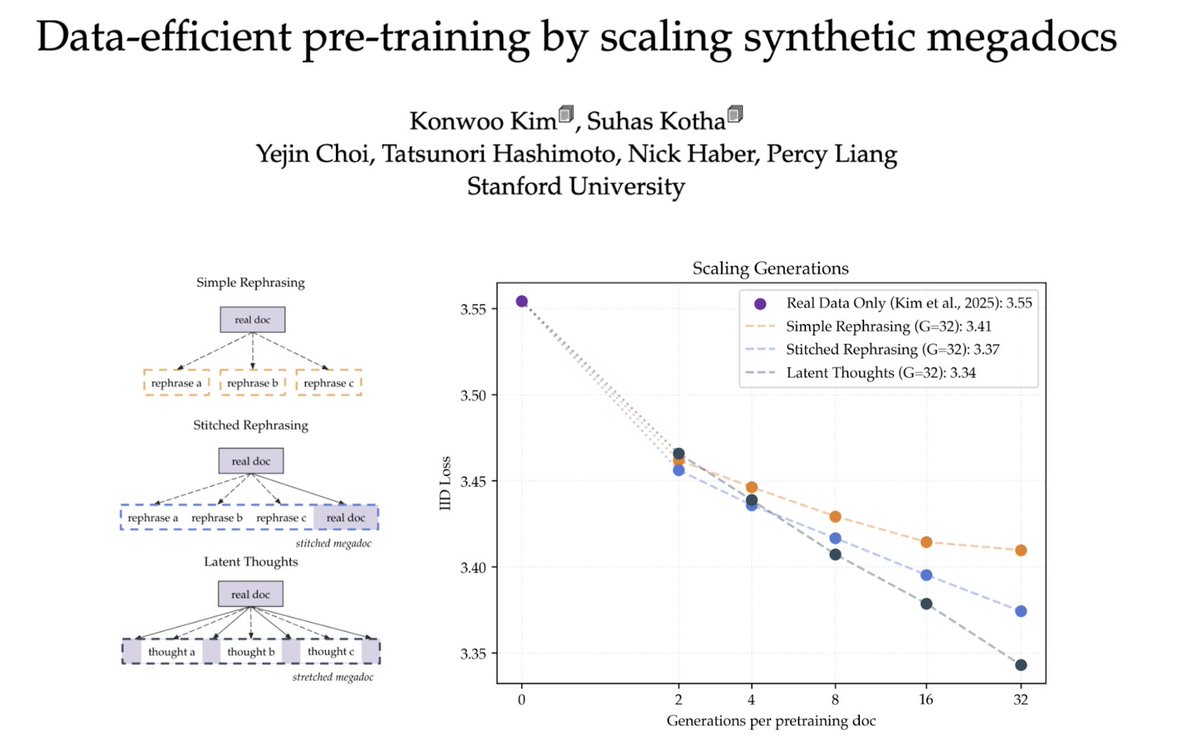
for data-constrained pre-training, synth data isn’t just benchmaxxing, it lowers loss on the real data distribution as we generate more tokens
for even better scaling, treat synth gens as forming one long 𝗺𝗲𝗴𝗮𝗱𝗼𝗰: 1.8x data efficiency with larger gains under more compute
Models are typically specialized to new domains by finetuning on small, high-quality datasets.
We find that repeating the same dataset 10–50× starting from pretraining leads to substantially better downstream performance, in some cases outperforming larger models. 🧵
Your LLM already knows the answer. Why is your embedding model still encoding the question?
🚨Introducing LLM2Vec-Gen: your frozen LLM generates the answer's embedding in a single forward pass — without ever generating the answer. Not only that, the frozen LLM can decode the embedding back into text.
🏆 SOTA self-supervised embeddings
🛡️ Free transfer of instruction-following, safety, and reasoning
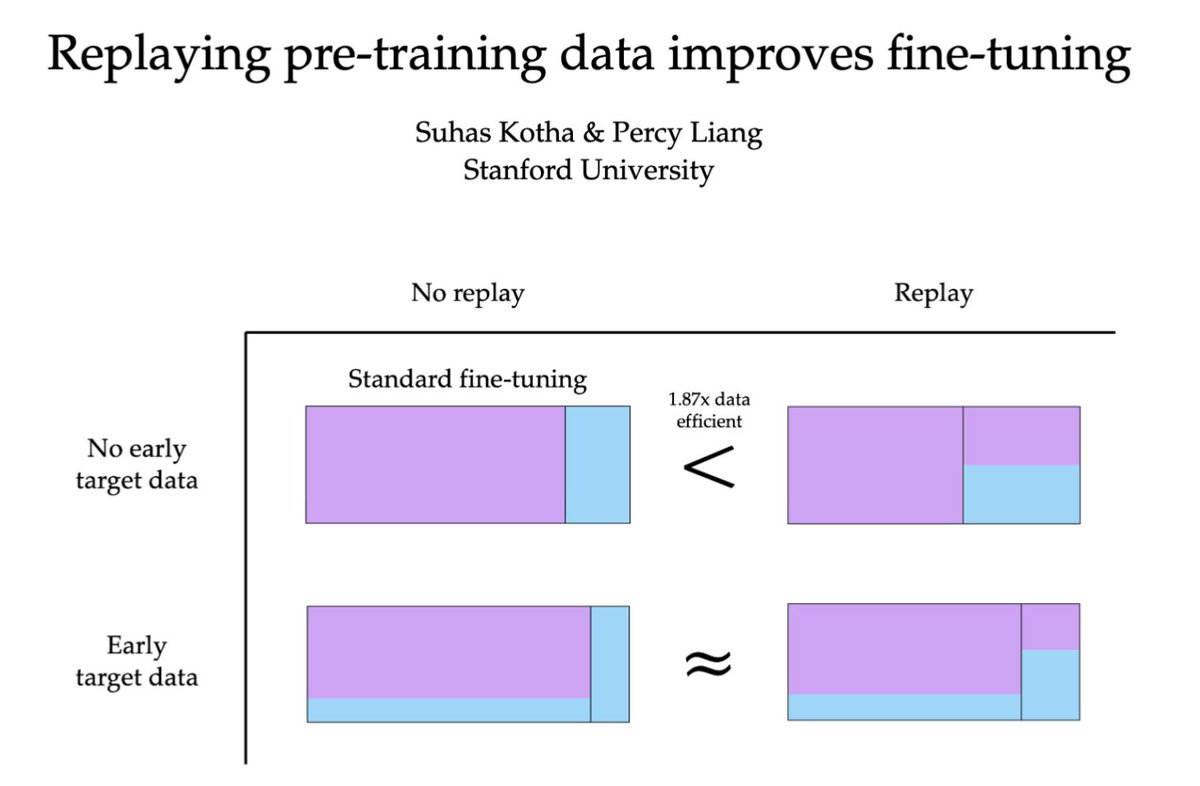
to improve fine-tuning data efficiency, replay generic pre-training data
not only does this reduce forgetting, it actually improves performance on the fine-tuning domain! especially when fine-tuning data is scarce in pre-training (w/ @percyliang)
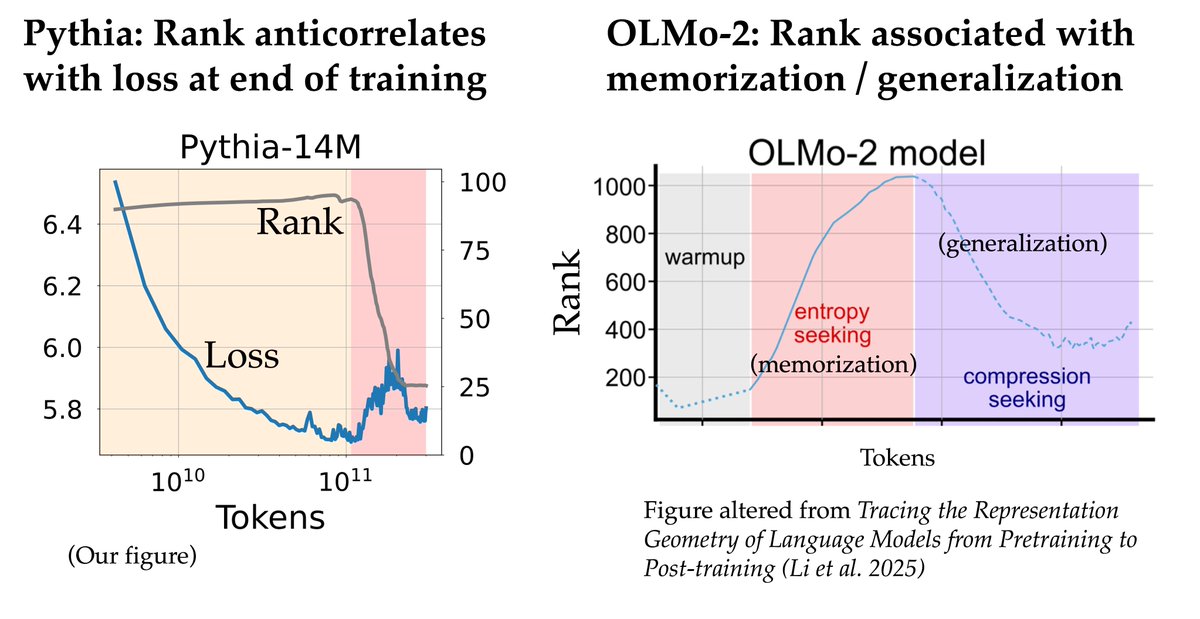
the rank of llm representations / weights has recently been such a hot topic, with multiple papers arguing that rank is a good predictor of performance
it turns out, our paper shows it's mainly hyperparameters that determine the rank!
read Atharva's thread ↓
Is the geometry of language model weights really predictive of performance?🔍
Our new work challenges the popular hypothesis that low rank unembedding matrix hurts LLM performance; and the answer is more complicated than you'd think!
https://t.co/0YxcZmNpfb
(1/8)
🔭 We’re releasing Hodoscope: an open-source tool for unsupervised behavior discovery. It lets you visually explore and compare agent behaviors at scale.
It helped us discover a novel reward hacking vulnerability in Commit0 - with just a couple minutes of human effort.
Are we done with new RL algorithms? Turns out we might have been optimizing the wrong objective.
Introducing MaxRL, a framework to bring maximum likelihood optimization to RL settings.
Paper + code + project website: https://t.co/j9BCBF7K3R
🧵 1/n
RL on LLMs inefficiently uses one scalar per rollout. But users regularly give much richer feedback: "make it formal," "step 3 is wrong."
Can we train LLMs on this human-AI interaction?
We introduce RL from Text Feedback, with 1) Self-Distillation; 2) Feedback Modeling (1/n) 🧵
1/ We found that deep sequence models memorize atomic facts "geometrically" -- not as an associative lookup table as often imagined.
This opens up practical questions on reasoning/memory/discovery, and also poses a theoretical "memorization puzzle."