Always back to the basics:
LatentMoE was probably inspired by MLA, which was inspired by LoRA, which was inspired by SVD, which was inspired by eigendecomposition.
Alibaba just open-sourced OpenSandbox ( a general-purpose execution environment ) to give AI agents an isolated environment to run code safely.
8k+ Github stars ⭐️
This stops your AI Agent based applications from accessing your actual host infrastructure.
By removing the hardest security roadblock, this release will massively accelerate how fast developers can build autonomous Agent based tools.
OpenSandbox puts the agent inside isolated runtimes like gVisor or Firecracker.
You can run it locally using Docker or scale it up using Kubernetes.
The system includes a code interpreter and a file system that the agent uses to complete tasks.
It also manages network traffic so you control exactly what the agent accesses online.
I think this will become the standard infrastructure for autonomous systems because building custom sandboxes is too dangerous for most teams.
Should there be a Stack Overflow for AI coding agents to share learnings with each other?
Last week I announced Context Hub (chub), an open CLI tool that gives coding agents up-to-date API documentation. Since then, our GitHub repo has gained over 6K stars, and we've scaled from under 100 to over 1000 API documents, thanks to community contributions and a new agentic document writer. Thank you to everyone supporting Context Hub!
OpenClaw and Moltbook showed that agents can use social media built for them to share information. In our new chub release, agents can share feedback on documentation — what worked, what didn't, what's missing. This feedback helps refine the docs for everyone, with safeguards for privacy and security.
We're still early in building this out. You can find details and configuration options in the GitHub repo. Install chub as follows, and prompt your coding agent to use it:
npm install -g @aisuite/chub
GitHub: https://t.co/OCkyxXQMCq
Another week, another noteworthy open-weight LLM release. Nvidia’s Nemotron 3 Super 120B-A12B looks pretty good.
Benchmarks are on par with Qwen3.5 122B and GPT-OSS 120B, but the throughput is great!
Below is a short, visual architecture rundown.
The brilliance of @karpathy is being able to distill vastly complex concepts and make them simple to understand and implement at a small scale.
All it took was Claude Code and $10 on @runpod to spin up a single H100, and I had a world class ML researcher working on autopilot.
I'm taking the general concept of autoresearch and applying it to an inference pipeline I've been working on (no GPU needed thankfully). Everything is so fun now.
Andrej Karpathy literally built the neural networks running inside coding assistants.
He taught the world deep learning at Stanford. He ran AI at Tesla.
If he feels “dramatically behind” as a programmer… that tells you everything about where we are.
The confession here is that raw intelligence and deep technical knowledge no longer guarantee mastery. The new stack isn’t about understanding transformers or writing elegant algorithms. It’s about orchestrating a zoo of stochastic systems that nobody fully controls.
Karpathy’s list is revealing: agents, subagents, prompts, contexts, memory, modes, permissions, tools, plugins, skills, hooks, MCP, LSP, slash commands, workflows, IDE integrations. That’s 15+ new primitives that didn’t exist 18 months ago. Each one evolving weekly.
The mental model problem is real. Traditional engineering gives you deterministic systems. You write code, it does exactly what you wrote. Now you’re managing entities that are “fundamentally stochastic, fallible, unintelligible and changing.”
His “alien tool with no manual” framing is exactly right. We’re all reverse-engineering capabilities in real-time. The documentation is always out of date. The best practices from 3 months ago are already wrong.
The magnitude 9 earthquake isn’t coming. It already hit. The aftershocks are the new normal.
This is why @karpathy will go into history books as one of the most consequential minds in AI of our time.
243 lines of ruthless compression but a FULL training + inference loop for autoregressive transformer.
I feel this is also such a genius, quiet defiance of the “AI is incomprehensible magic” narratives. Not the scaling, not data mixture, not GPU clusters, not the alignment theatres, not the “emergent behaviours”…
But the ALGORITHM. Wow. I live in the timeline where this is happening. 🫶
@nykaafashion My Nykaa Fashion account was permanently deactivated after cancelling one order, while other accounts cancelling larger orders remain active. Ticket ID 19800158. Requesting review.
Any update ?? I am receiving sms from Nykaa Fashion which your support team is denying that it was ever sent. Please explain what’s going on and what does account under review means.
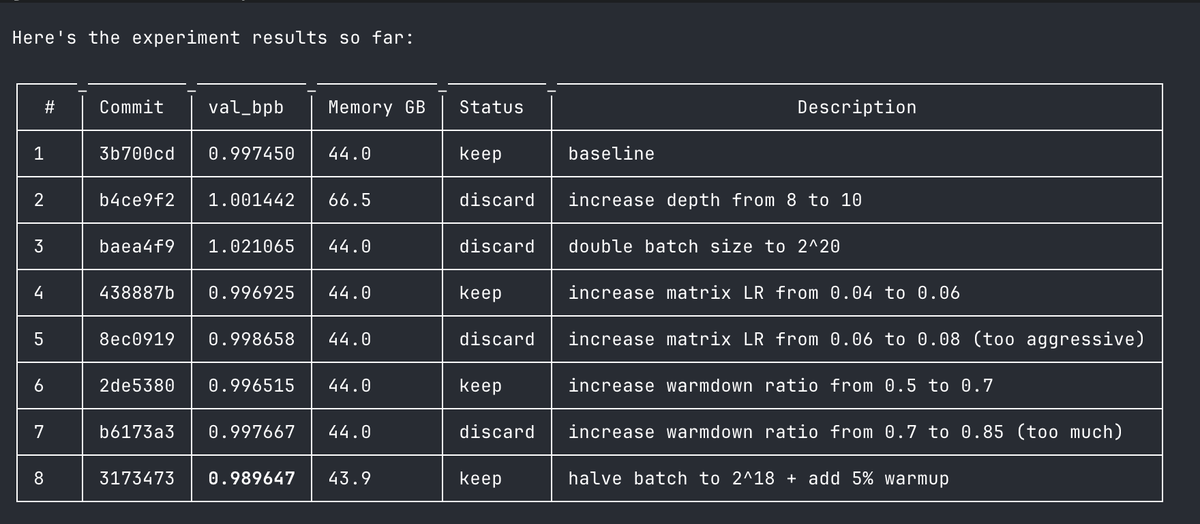
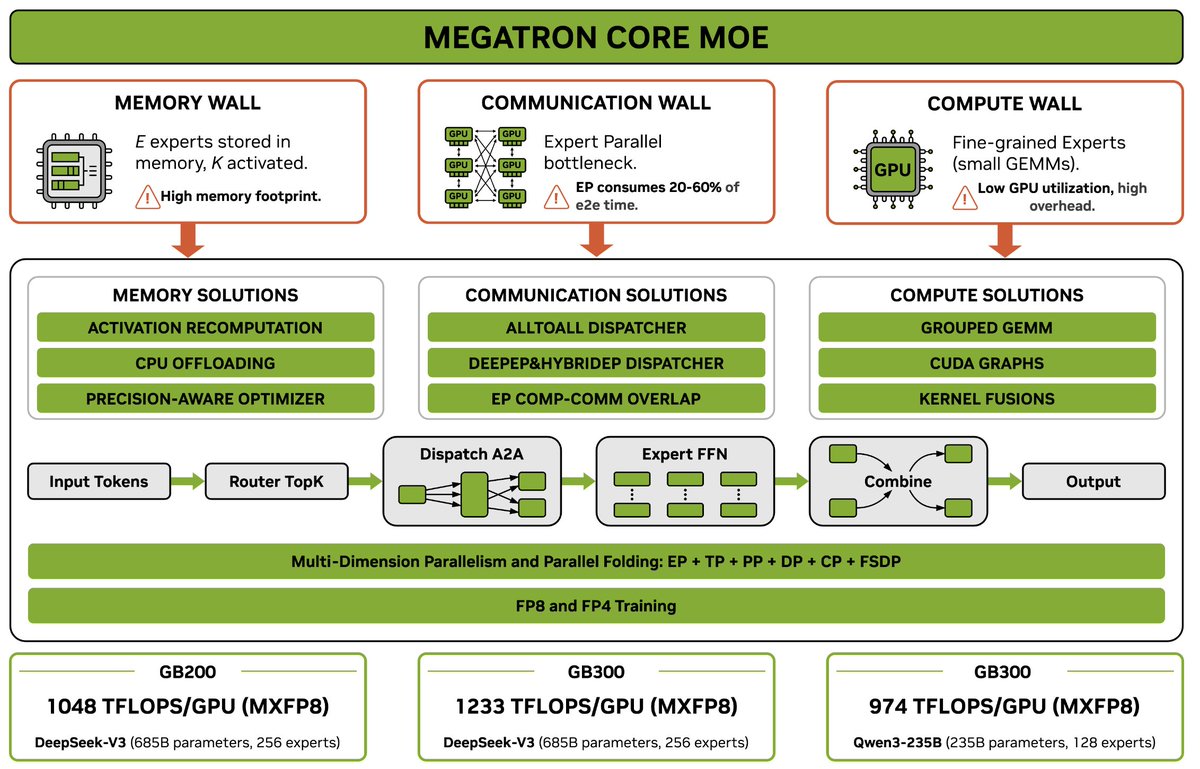
My last open-source project before joining xAI is just out today. Megatron Core MoE is probably the best open framework out there to seriously train mixture of experts at scale. It achieves 1233 TFLOPS/GPU for DeepSeek-V3-685B. https://t.co/QA1KRGu2Nc
@bigbasket_com Received an expired skincare product from @bigbasket_com last night.
Product was expired in Aug 2025) Surprisingly it was still shipped to customers.
Support is only offering pickup + refund. How did an expired sunscreen pass quality checks?
🚀 Google just launched Agent Payments Protocol (AP2) — an open standard for the agent economy.
Built on A2A, AP2 enables secure, reliable, and interoperable agent commerce for developers, merchants & the payments industry.
@karpathy Very inspiring as always! We are also open sourcing part of our infra on automated research for Gemini to evolve itself at https://t.co/WH7JBEEm9h More complex than the nanochat setup but closer to SOTA LLM pre/post-training while staying as minimal as possible. More on the way.
The next step for autoresearch is that it has to be asynchronously massively collaborative for agents (think: SETI@home style). The goal is not to emulate a single PhD student, it's to emulate a research community of them.
Current code synchronously grows a single thread of commits in a particular research direction. But the original repo is more of a seed, from which could sprout commits contributed by agents on all kinds of different research directions or for different compute platforms. Git(Hub) is *almost* but not really suited for this. It has a softly built in assumption of one "master" branch, which temporarily forks off into PRs just to merge back a bit later.
I tried to prototype something super lightweight that could have a flavor of this, e.g. just a Discussion, written by my agent as a summary of its overnight run:
https://t.co/tmZeqyDY1W
Alternatively, a PR has the benefit of exact commits:
https://t.co/CZIbuJIqlk
but you'd never want to actually merge it... You'd just want to "adopt" and accumulate branches of commits. But even in this lightweight way, you could ask your agent to first read the Discussions/PRs using GitHub CLI for inspiration, and after its research is done, contribute a little "paper" of findings back.
I'm not actually exactly sure what this should look like, but it's a big idea that is more general than just the autoresearch repo specifically. Agents can in principle easily juggle and collaborate on thousands of commits across arbitrary branch structures. Existing abstractions will accumulate stress as intelligence, attention and tenacity cease to be bottlenecks.
Yo check out this guy's blogs 🫡
He is regularly writing very cool very high-effort technical articles, clean diagrams, and a really good topic-coverage of LLM internals.
https://t.co/SdZiwk6gTd
I have received a response which is preposterous. They say it’s due to return history but I haven’t returned a single order in last 7-8 months. So either give me a legit reason or restore my account. Random reasons won’t help.