🚀 GLM-5.2 is here — and https://t.co/pP0HtsOYJu is Day 0 ready.
🧠 Stable 1M context
💻 Stronger coding & agent capabilities
📜 MIT-licensed weights
⚡ KTransformers now supports running GLM-5.2 token service on edge devices, powered by SGLang + KT-Kernel.
👉 Get started:
https://t.co/UxI4Dt6JWA
🚀 We just launched KV Cache Analyzer by https://t.co/EO7MXLjRIs!
📊 Analyze KV cache hit rates and estimate prefill throughput speedup under different cache budgets and eviction policies.
🧪 Use preset traces or your own local traces, choose the model and parameters, and see how KV cache reuse improves LLM inference performance across different settings.
👉 Try it now: https://t.co/3dccW3r657
KV Cache re-use is the most important thing for agentic rollouts. We've integrated Mooncake Store into prime-rl with vLLM, you can now use it as a drop-in replacement for native CPU/Disk offloading, giving you cross-node prefix cache reuse to make your agents go brrr🚀
@KVCache_AI Accurately quantifying your KV cache footprint is typically step one for inference optimization.
Thanks for the incredible support! We've officially updated our KVCache calculator with more models.
Big congrats to the TokenSpeed team & Qwen Inference team! 🙌 This is just chapter one. We’ll keep co-engineering to unlock speed-of-light inference for every Qwen model.
Cold starts are super painful for scaling LLM workers.
Check out our work at restoring inference workers (including AOT traces) in seconds, not 10s of minutes!
Proud to collaborate with @Alibaba_Qwen, @lightseekorg, @NVIDIAAI, @PyTorch, and @tri_dao on this milestone 🚀
Together, we helped push Qwen3.5 on the TokenSpeed inference engine to a record-breaking 580 tokens/sec for agentic workloads on NVIDIA GPUs.
From KV cache systems and runtime infrastructure to kernels, scheduling, and benchmarking, this was a true cross-stack co-design effort for high-performance open-source LLM inference.
Full PyTorch blog 👇
https://t.co/jDW0lNsUPd
Fast, faster, Qwen. 🚀
Thrilled to see Qwen3.5 reaching a record-breaking 580 tps for agentic workloads on the TokenSpeed engine! This milestone wouldn't be possible without our incredible partners.
Huge thanks to @lightseekorg, @NVIDIAAI, the Mooncake team, and @tri_dao for the pioneering FA4 optimization. Together, we are pushing the boundaries of open-source LLM inference. 🤝✨
Dive into the full @PyTorch blog post below! 👇
https://t.co/p04wookcZj
#Qwen #Qwen3_5 #TokenSpeed #LLM #Inference #AI #PyTorch #OpenSource #AgenticAI #HighPerformance
The speed-of-light optimization for Qwen3.5 on the TokenSpeed inference engine is a significant milestone, achieving a record-breaking 580 tokens per second (tps) for agentic workloads on NVIDIA GPUs.
In the PyTorch Foundation's latest community blog post, you can learn all about the complete design, implementation, and optimization of Qwen3.5 models in the TokenSpeed inference framework and see for yourself how this work is improving performance 👉 https://t.co/Qr1PTIhqok
This achievement was a joint effort between the @Alibaba_Qwen inference team, @lightseekorg Foundation TokenSpeed team, @NVIDIAAI , and the Mooncake team, with special contributions from @tri_dao for FlashAttention-4 (FA4) optimization. @KVCache_AI
🚀 We just launched the open-source KV Cache Size Calculator by https://t.co/GavTTEDu5C!
Calculate KV cache size for mainstream LLMs with flexible precision settings and detailed breakdowns.
Supports DeepSeek, GLM, Kimi, Qwen3 and MiniMax.
Try it now: https://t.co/PpN0bvKSVI
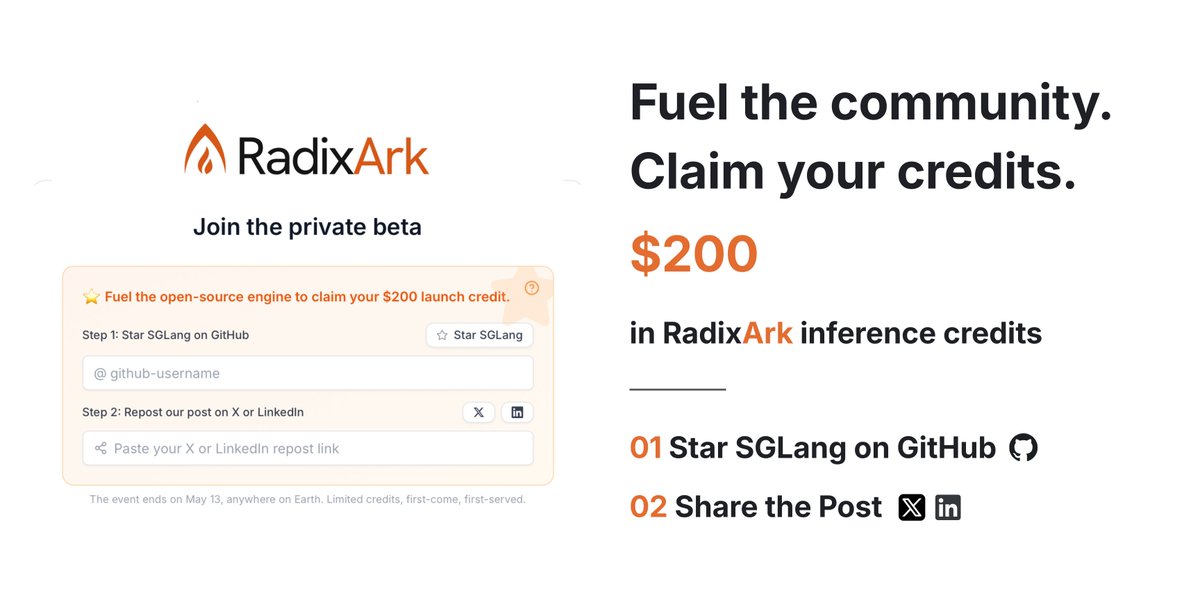
$200 FREE CREDIT! We just launched our inference platform for beta testing, and we're giving it to the community first.
⭐ Star SGLang on GitHub (https://t.co/uEeiF4ANRf) + repost this to claim your credits.
→ Limited spots, first come first serve
→ Deadline: May 13, 2025 (AoE)
Every star, every issue filed, every PR reviewed, every question answered in Slack — You built this with us. Thank you for believing in open-source AI infrastructure, in our mission, and in us.
Claim your credits: https://t.co/MVDvcvkFGX
🚀 Mooncake is powering agentic workloads serving with @vllm_project
Agentic traces reach 80K+ tokens with highly reusable prefixes. By turning KV cache into a distributed, reusable resource, we eliminate redundant compute and unlock massive gains: 🚀 3.8x higher throughput, ⚡ 46x lower P50 TTFT, 🌐Scales near-linearly to 60 GB200 GPUs at >95% hit rate.
Built in close collaboration with @Inferact 🤝
Excited to share what we've been building 🎉
3.8x higher throughput and 8.6x lower E2E latency on real Codex agentic traces, powered by @vllm_project and Mooncake (@KT_Project_AI).
Blog + code + open-sourced traces 👇
More to come!