Today's Future Data Systems Seminar Speaker: Jark Wu from @alibaba_cloud will finish off this semester with an overview of Apache Fluss. Zoom talk open to public at 4:30pm ET. YouTube video available after: https://t.co/bn07bMOiBf
Real-time multimodal AI is finally practical ⚡️
With Apache Fluss (incubating) + Lance, you can stream data in, tier it automatically, and query it instantly for RAG, analytics, or training.
Full walkthrough 👉https://t.co/T8BHPFzVu7
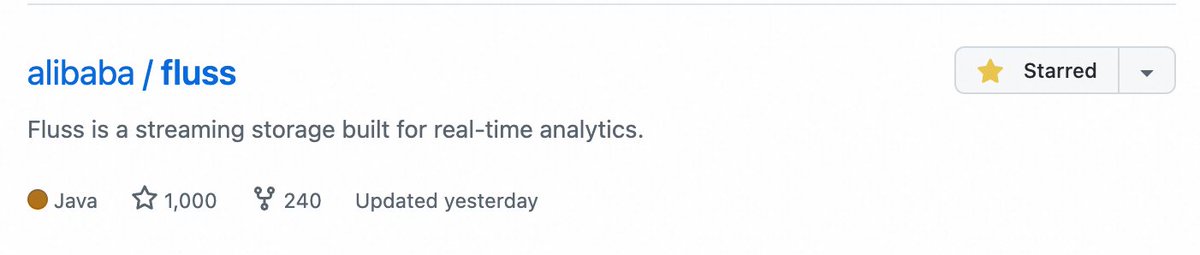
🎉 #Fluss has reached 1,000 stars on GitHub! 🚀 This is an incredible milestone and a new beginning for our growing open-source project. A huge thanks to everyone who has contributed, provided feedback, or shown support in any way.
🌟 https://t.co/6Rimt66xsY
Open sourcing #Fluss on site of #FlinkForward Asia was an incredibly memorable experience, and it fulfilled a small dream of mine as a tech enthusiast. Join the Fluss community and build the next generation of real-time architecture together! 🚀🚀🚀
https://t.co/6Rimt675iw
The busy #FlinkForward has come to a successful conclusion, and it is an honor to share FLUSS on the Future part of Flink's 10-year anniversary. It is like Fluss returning to the birthplace of its name and taking the torch from Flink to start a new decade!
Join us at #FlinkForward Berlin 2024 for an exciting exploration into the Past, Present, and Future of Apache Flink! 🐿️ Learn exclusive ecosystem advancements and a special announcement from Ververica.
⚡Register now: https://t.co/YNPC29DzlM
@jarkwu, @BenGamble7, @StephanEwen
Join us at #FlinkForward Berlin 2024 for an exciting exploration into the Past, Present, and Future of Apache Flink! 🐿️ Learn exclusive ecosystem advancements and a special announcement from Ververica.
⚡Register now: https://t.co/YOgT0omEGS
@jarkwu, @BenGamble7, @StephanEwen
Join us for our Hong Kong Apache Flink Meetup, hosted by #AlibabaCloud on 13 June 2024. This exciting afternoon aims to deepen your understanding of streaming data with Apache Flink & Apache Paimon-based streaming lakehouse to drive greater value for your business.
Register now:
Let's deep dive into the shared-storage architecture of AutoMQ(https://t.co/yzhEam4qWi):
1. The classic Kafka architecture, known as shared nothing, requires each broker to have a TiB-level local disk and 3 replicas. However, this setup can lead to high costs and scalability challenges in the cloud-native environment.
2. Tiered storage has indeed reduced storage costs, but the need for expensive replication and large local disks still remains. Yes, tiered storage won't fix Kafka.
3. AutoMQ's shared storage architecture utilizes EBS and S3 for shared storage. EBS functions as the WAL for recovery, while S3 serves as the primary storage. Each broker only needs a small EBS volume, making it a cost-effective solution.
This design encompasses all the benefits touted by the confluent freight cluster or WarpStream, while maintaining crucial low latency for stream processing.
📢📷The #ApacheFlink community is very happy to announce the release of #Flink 1.19, which contains a number of exciting improvements. Please check out the release announcement for details. https://t.co/euX30s1243… Thank all the contributors who made this release possible!
Apache Flink 1.19.0 is here! Packed with enhancements and new features contributed by 162 amazing individuals (including our Head of Engineering, Jing Ge!), completing 33 FLIPs and fixing 600+ issues. Huge THANK YOU to everyone involved! 🙌 Let's delve in!
https://t.co/90Q5qrDy5A
Thanks Gunnar and @debezium community for the great work ❤️. Hope we can help more @ApacheFlink users and feedback more to upstream communities (mainly debezium) as well.
Here are slides of another talk "Apache Flink 2.0 Preview" co-authored with @Xintong_Song at #FlinkForward 2023.
We shared the planned important changes and progress of Flink 2.0.
https://t.co/CNW1Pmx70P