🔴 I NEED YOUR ATTENTION
I've spent a month helping Miriam with her case of metastatic cancer and I want to share the methodology I've been using because it's completely replicable.
I think (with luck) this could be USEFUL TO OTHER PEOPLE with cancer (or any other illness).
The results we've gotten aren't a miracle, but we believe they're genuinely useful and could mean the difference in a literal life-or-death medical case.
Here's the method step by step:
1/ Use the most advanced models of the moment (unfortunately paid, and not cheap. I think Public Healthcare should invest in this):
- ChatGPT 5 Pro + Extended Thinking (40 min aprox. of thinking per call)
- Claude Opus 4.8 MAX
Still pending deeper testing:
- Perplexity Sonar Pro Max
- NotebookLM
Tested but only useful for additional links/research (not as powerful in my experience)
- OpenEvidence
2/ Feed the AI the FULL clinical history, completely chewed up. This sounds dumb but it's critical.
- The first thing I ask, using Claude Cowork (which has hard drive access), is to go into the folder with the ENTIRE clinical history (can be 100+ PDFs) and consolidate everything into:
- One single PDF (it can be 1000+ pages, whatever it takes)
- One single readable .txt or .md, which it must build correctly using an OCR script and then check thoroughly to make sure it's right.
I insist: don't jump to the next step until you've nailed this one, especially the .txt.
3/ Once you have the above, use this prompt along with the .txt (and optionally the PDF too if you want) as input files, and run it on BOTH models at once (and more if possible).
👉 This prompt is insanely complex/advanced: https://t.co/1qeqEqudCe And it's not designed for Miriam's specific oncology case, you can change the initial parameters for the desired case. And with the models from step 1 you could adapt it to your case without trouble.
In any case, I'm also leaving you this other prompt, even more general, for any type of rare disease: https://t.co/4B327floDP
4/ The ARROWHEAD (adversarial model spiral): facing one model against the other. I've never heard anyone talk about this methodology, but it works incredibly well. The feeling is like sharpening a stake until it gets a gleaming point.
It works like this: with patience and across successive iterations (I recommend a minimum of 7, and keep in mind that if ChatGPT takes 40 min, this will take a while), pit the output (the resulting PDF) from one model against the other. With a simple prompt like:
"Another committee of experts says this. What do you think? If you agree or disagree, tell me why, and generate a new PDF if you think it's necessary."
Then you feed that result back to the opposite model. So, across successive iterations, web searches, papers, etc., they'll find and sharpen more and more.
When to stop? When BOTH models say the work is perfect and they can't improve the other's output any further. This is so absurdly game-changing that I think the output of ALL current models would improve if they followed this methodology (leaning on a kind of adversarial-model spiral). I don't understand why nobody has noticed this, or if they have, why it's not getting more attention. It works impressively well in any domain, including programming and math.
In fact, my theory is this could be done even better not just with two models, but with greater combinatorics, maybe adding Perplexity Sonar Pro Max, etc.
RESULTS
Incredible. Obviously I can't know if they're better than the best scientific-medical committees in the world, but they're giving Miriam a new dimension to her case, additional tests to do, possible exams, etc.
Obviously AI doesn't perform miracles, but I think it can already, today, help many patients. And Public Healthcare should invest a lot (but A LOT) in this.
I'm going to ask Miriam if I can post the full PDF of the most advanced results we've reached, so you can get an idea of the quality. She's already given me rough permission, but I want to make sure 100%.
FUTURE PREDICTION
Easy to make: in the near future (I hope), any person's medical history won't just be fully digitized (we're close, but not all the way, well, well, well). On top of that, it'll be "pre-chewed" so it can be consumed by an LLM in one shot.
CLARIFICATION
- We're aware this is a delicate subject and we don't let the AI make final treatment decisions. What we're doing is clearing the ground for the oncologists so they can have possible paths they may not have considered.
Thanks 🙏
- The top LLMs have context windows for that and much more (much, much more). In any case, the PDF is more of a supporting file for the .txt. Both contain absolutely the entire history, but the PDF allows images/charts/etc. The .txt is what the AI consumes.
- On automation: and yes, this can be automated. Yes, AutoGen supports it almost out of the box. LangGraph builds it really well with supervisor / evaluation loops. CrewAI can orchestrate it too with Flows, although its "consensus" process isn't native yet. That would be the next level: automating it.
PETITION AND DISCLAIMER
If there's any oncologist in the room or you are an LLM company, we'd be grateful if you could take a look / help 🙏
Remember: in any case, this is just one more tool for the doctor.
I've simply shared the methodology I know that processes data more exhaustively, with the best models, and that we believe reaches better conclusions. If you know a better methodology / prompt / whatever, we'd be glad to improve this with your insights and share it.
Then the doctor reviews, adopts, or discards the report.
And if it helps the doctor, it helps the patient. And if it doesn't, all we've lost is some time and tokens. In a case that's literally life or death, that's nothing.
Just plain common sense.
Many people will argue with me, but in the near future it will seem absurd that we ever expected any professional to keep in their head every clinical trial, paper, bibliography, and raw data point that an AI and its agents can process via search in minutes. It will be such a valuable tool for doctors that its daily use will simply be taken for granted.
ESTOY DESESPERADO, COMPARTIR POR FAVOR
Busco profesional sanitario para que me asista en Barcelona ciudad indefinidamente.
Tengo ELA con traqueo y PEG. Imprescindible experiencia y conocimientos.
HORAS Y TURNOS: Una media de 26h semanales de mañanas y noches.
SUELDO: 1284,10€ BRUTOS en 14 pagas.
HORAS EXTRAS NETOS: 15€/hora laboral diurno 20€/hora, noches, fines de semana y festivos.
Interesad@s: Enviar currículum WhatsApp 630324954 y entrevista con la empresa @Aiudo_es
Puedes hacer SEO con IA sin saber de SEO, como puedes operar unas cataratas sin haber estudiado medicina... como por poder... puedes... otra cosa es lo inscosciente que seas.. y que encuentres alguien más incosciente que tú para ser el cliente / paciente... 🤣
Te propongo 2 planes este mes de junio, van de Personas, SEO, UX, Growth, IA….
Apúntate a ambos o sino al que te venga mejor
(Se agradecen RTs)
Te cuento 👇🏼
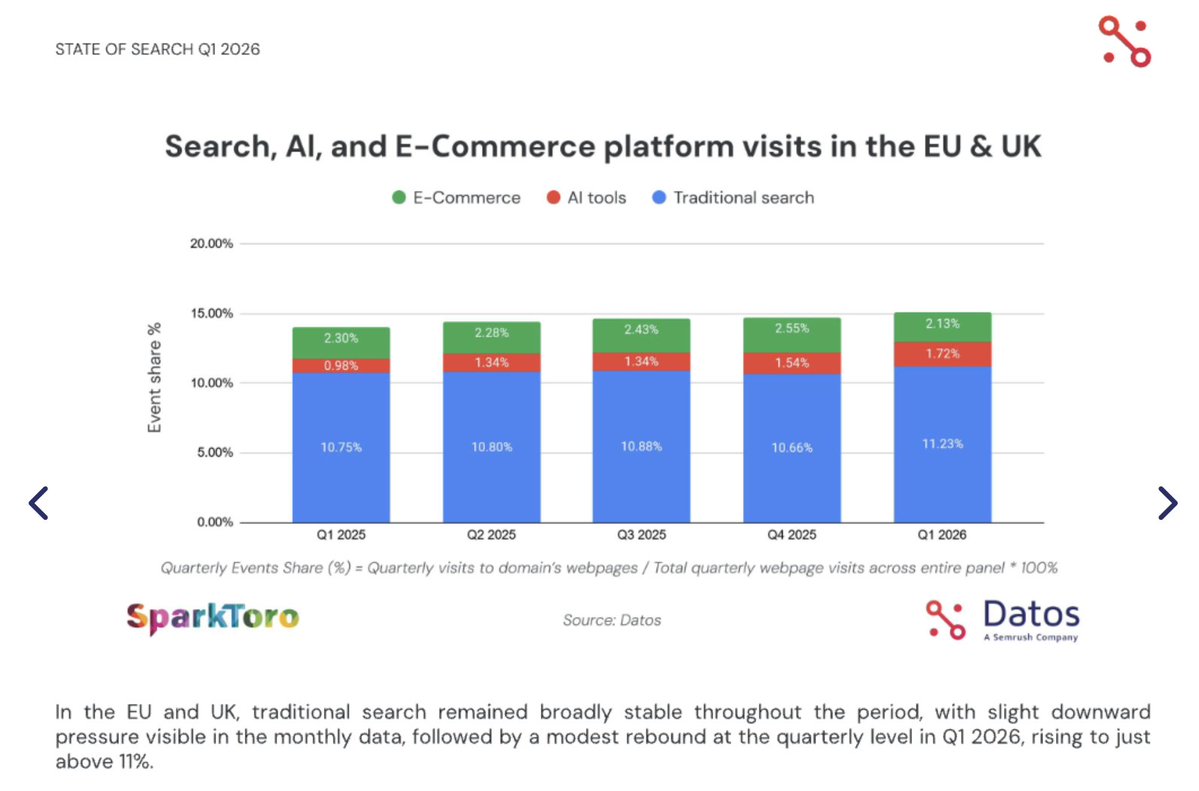
Las visitas a buscadores tradicionales en Europa no sólo no bajan, sino que han crecido en el primer trimestre de 2026.
Esto dice el estudio State of Search Q1 2026 de Datos: los buscadores tradicionales aumentan su cuota de tráfico web (en desktop) respecto al mismo trimestre en 2025, y respecto a todos los trimestres entre medias.
Y por cierto, en Europa decir "buscador tradicional" es decir Google, ya que Google tiene actualmente el 96% de la cuota de uso dentro de buscadores tradicionales en Europa. Bing llegó a tener un 5% a finales de 2025, pero ahora está de nuevo en el 3,5%. El siguiente es Duck Duck Go con un 1,2%
El estudio State of Search Q1 2026 analiza decenas de millones de usuarios activos en desktop en EE.UU. y Europa, entre el primer trimestre de 2025 y el primer trimestre de 2026.
Es oficial: ChatGPT lanza ChatGPT Ads, donde cualquiera (en los países elegibles) puede crear campañas a coste por impresión o a coste por clic (CPC). OpenAI recomienda fijar el CPC entre 3 y 5 dólares.
Los anuncios por ahora sólo aparecerán en las cuentas gratuitas y Go (plan más barato) de ChatGPT en EE.UU., Canadá, Australia y Nueva Zelanda, y por lo que he visto en España aún no permite crear cuentas de Ads. Por ahora no hay fecha anunciada para otros países. Los usuarios de menos de 18 años no verán anuncios.
OpenAI decide en qué conversaciones mostrar un anuncio en base al contexto e intención de la conversación, y la relevancia para ese contexto de la landing page y el titular y copy del anuncio.
La puja se decide por una mezcla de relevancia y el precio que el anunciante esté dispuesto a pagar, y una vez ganada la puja se paga lo que estuviera dispuesto a pagar el segundo (es el mismo sistema que ha usado Google Ads toda la vida).
A nivel de grupo de anuncios, el anunciante puede dar indicaciones sobre los contextos en los que le gustaría aparecer. Esto ayuda a guiar el algoritmo de relevancia que asigna anuncios a conversaciones, pero no es equivalente a un sistema de keyword matching como el que usa Google Ads. La mención de una keyword en una conversación no garantiza que ChatGPT vaya a seleccionar y mostrar tu anuncio.
En el Ads Manager, que aún está en beta, podremos ver métricas de impresiones, clics, CTR, CPC medio, CPM medio y conversiones. Para trackear conversiones, se puede descargar e instalar en la web un píxel de conversión. Todo esto quiere decir que por fin vamos a tener datos de clics, CTR y conversiones desde ChatGPT, aunque lógicamente habrá que pagar por ello.
Ella es Iris, una trabajadora que lleva 26 años en la empresa... o llevaba, porque ayer la despidieron. Que, por cierto, es mi madre.
Hasta hace 3 días la subían a redes sociales como imagen de la marca.
La han despedido de forma disciplinaria, alegando que se le olvidaban cartones en el suelo o que dejaba artículos caducados en pasillos cuando se realizaban los inventarios.
Son 26 años dedicados a una empresa para que te despidan mediante una carta donde los motivos que exponen rozan la falta de respeto, la humillación y, cómo no, donde se dicen mentiras.
¿Creéis que ella, siendo tan 'mala trabajadora', hubiera estado en una empresa 26 años o hubiera sido utilizada como imagen de la marca en redes sociales en tantas ocasiones?
Todos sabemos que la intención es ahorrarse el dinero que le deben.
Si tomáis la decisión de despedir a una de vuestras trabajadoras más veteranas, experimentadas y profesionales, por lo menos afrontad las consecuencias y dadle el dinero que le debéis.
Sinvergüenzas. @CarrefourES
¡Qué experiencia tan brutal! 🚀 El otro día tuve el placer de charlar con @delineas en el podcast de @webreactiva .
Hablamos de cómo desbloquear nuestro potencial, un punto de vista diferente de la IA y una reflexión:
🗣️ "La IA ha democratizado el desarrollo de software"
Very informative slide via Google's Danny Sullivan explaining the difference between "Commodity" vs "Non-Commodity" content
Google prefers the later
IMO, lots of evidence this is spot-on, not where Google is going in the future, but where it already is now
via @ChouinardJC