ChatGPTQueue skyrockets your productivity by allowing you to queue up messages for ChatGPT.
Putting you in the top 1% of users 🪄
Try it now: https://t.co/xwTy67n2w5
it’s in gemini, just create it in ai studio. oh, that’s for your personal google one account. for workspace you need gemini business. no, not gemini advanced, that’s ai pro now. unless you need ai ultra. oh agents? you do that in spark actually. no, not gemini api managed agents, that’s different. for coding use jules. unless you mean the agentic ide, that’s antigravity. no, that’s the old antigravity, download the new one. actually gemini cli is being deprecated, use antigravity cli. no the flash model is smarter than the pro model. unless you need pro. if it’s video, use flow. no, flow uses veo. no, nano banana is images. actually that’s in gemini now. unless you’re in search, then it’s ai mode. no, research is notebooklm. anyway it’s all very simple.
I’m looking for someone to sponsor my token maxxing, just DM me.
- I’ll share a full weekly report on everything we use it for
- Implement any useful workflows into your business
- Give you 10% profit share on anything I build.
i am excited to see what will happen with tokenmaxxing startups, both for how they work internally and the products they can build.
openai offered to invest $2M in tokens into every startup in the current yc batch.
happy building!
The highest leverage play right now is compounding your knowledge and workflows into a agent like Hermes
Turn your computer and phones into a client to interact with your agent.
And step away from your desk, move around the world and delegate work to your agent.
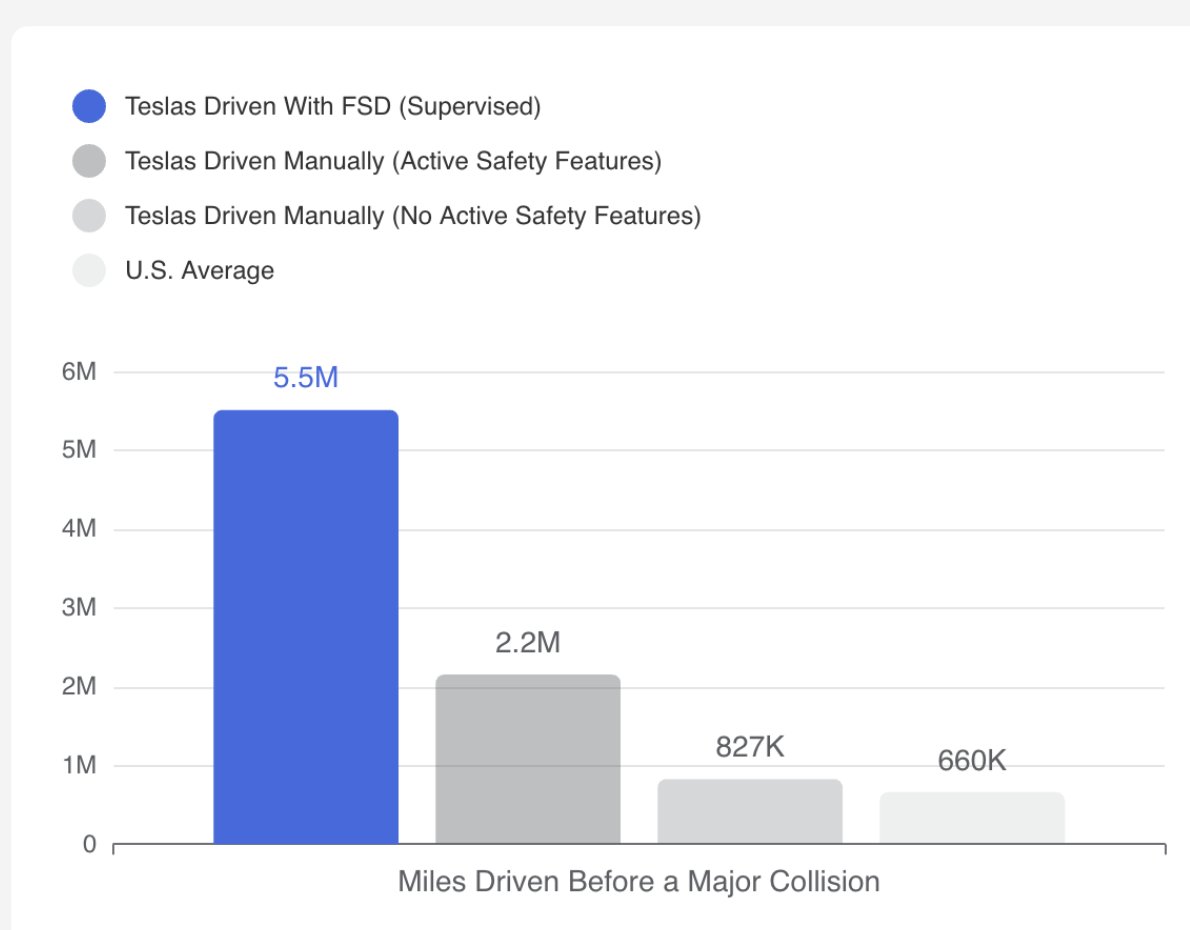
People completely miss the most important thing about Tesla FSD
It’s not just about convenience. It’s not a "cool self-parking trick."
It’s about the fact that car crashes are the #1 killer of healthy people aged 5-29 globally and one company has gathered over 10 billion miles of real-world data to actually solve it
Look at the recent data: Tesla just became the FIRST vehicle to pass NHTSA's new ADAS safety tests. Not the first EV. The first vehicle. Period.
The reality is harsh but simple. Countries that approve FSD get safer roads overnight. Countries that delay will literally watch their citizens die in preventable crashes while bureaucrats sit in meeting rooms debating "safety."
The "safety" argument against FSD is officially dead
Chamath just delivered the clearest diagnosis of what is happening to enterprise software and the OpenAI Deployment Company is the most damning piece of evidence he could have picked.
"The low end of the market is basically finished. There is no safe space."
90% of public SaaS stocks are down 30-80% from their 52 week highs, the median software stock is now negative over the last 3-6 months.
Goldman Sachs reported that software forward P/E multiples fell from 35x to 20x, the lowest absolute level since 2014 and the smallest premium to the S&P 500 since 2010.
The low end died first and fastest, because AI replaced it most directly.
The small business tools, the lightweight project managers, the single function SaaS products that charged $49 a month per seat, those are being replaced by AI agents that do the same work as a workflow, not a product.
You do not buy an AI powered tool, you describe what you need and it builds it and the seat based model that created the SaaS industry simply does not apply to that transaction.
But Chamath's more interesting argument is about the high end and the tell he points to is perfect.
OpenAI just raised $4 billion from 19 investors including TPG, Brookfield, Bain, and McKinsey to launch a consulting company and guaranteed those investors a 17.5% annual return to do it.
On $4 billion in committed capital, that is roughly $700 million per year in guaranteed payouts, owed by a company that is projected to lose $14 billion in 2026.
The goal of this venture is to compete directly with Deloitte, PwC, Ernst & Young, Andersen, and Cognizant.
Think about what that structure reveals.
OpenAI lost half of its enterprise LLM API market share from 50% to 25% between late 2023 and mid-2025, with Anthropic now leading at 32%.
Its response was not to build a better model but rather to raise $4 billion, offer guaranteed PE-tier returns and hire embedded engineers to physically sit inside client organizations and make AI actually work in production.
The reason, as Chamath identified, is that the high end of the market is not easy.
"It's not like boop boop boop, put in a prompt and beep bap boop, it all works," he said and the data confirms exactly that.
88% of organizations running AI agents reported a security incident in the past year, 42% of C-suite executives say AI adoption is creating internal organizational conflict.
The average enterprise AI consulting implementation costs $228,000 in year one versus $77,000 for platform-based approaches and most still stall before reaching production.
Anthropic immediately matched OpenAI with a competing $1.5 billion consulting venture backed by Blackstone, Goldman Sachs, and Hellman & Friedman bringing the combined spend by the two leading AI labs on human powered enterprise deployment to $5.5 billion in a single month
Chamath's read is that the high end, the large enterprise platforms like Salesforce with proprietary data flywheels, Palantir with its FDE model already proven at scale, Oracle with vertical specific data moats will survive and consolidate.
The mid-market point solutions, the single function tools, the lightweight enterprise apps without defensible data assets, those are on the conveyor belt.
The AI industry is not just disrupting the companies that use software but rather disrupting the companies that sell it.
Your brain is wired to quit at the exact moment you're about to break through.
Most people think they quit because they lack discipline or motivation. They blame their willpower. They assume successful people have some genetic advantage or superior mental toughness.
The real reason runs much deeper.
Neuroscientists at UC San Diego studied brain scans of people learning complex motor skills over several months. They discovered something counterintuitive: during the weeks when learners felt most frustrated and considered quitting, their brains were undergoing the most dramatic structural changes. New neural pathways were forming at accelerated rates. Myelin sheathing around neurons was thickening rapidly. The very period that felt like stagnation was actually when the most profound rewiring was happening.
The participants had no conscious awareness of this transformation. Subjectively, they felt stuck. Objectively, their brains were rebuilding themselves.
Your nervous system interprets sustained incompetence as a survival threat. When you attempt something new and fail repeatedly, ancient circuits fire that once kept your ancestors alive by making them avoid dangerous situations. The same neural pathways that prevented early humans from repeatedly approaching predators now prevent modern humans from repeatedly approaching challenges.
Competence feels safe. Incompetence feels like death.
Every time you miss the shot, fumble the presentation, or write garbage, your amygdala sends distress signals. Your brain floods with cortisol. Your body creates the same physiological experience it would create if you were being chased by something that wanted to kill you. After days or weeks of this neurochemical assault, quitting feels like escape from genuine danger.
But what the UC San Diego researchers revealed changes everything about how we should interpret that discomfort. The biochemical chaos you feel during extended periods of failure is actually evidence that deep learning is occurring. Your brain consumes massive amounts of energy to build new neural architecture. The exhaustion, frustration, and sense of being overwhelmed are byproducts of construction, not signs of inadequacy.
People who master difficult skills have accidentally discovered something profound: they've learned to interpret the discomfort of incompetence as evidence they're in exactly the right place. They've trained themselves to recognize the specific feeling of neural restructuring and chase it instead of avoiding it.
The shift is so subtle most people never notice it happening. But once it clicks, the entire relationship with difficulty inverts.
Watch someone who genuinely enjoys the learning process. They don't celebrate successes the way normal people do. They celebrate failures that teach them something. They get excited by obstacles that reveal gaps in their understanding. They treat confusion as information, not as evidence they should quit.
They've rewired their internal reward system to crave precisely the experiences most people avoid.
What makes this psychological rewiring possible is understanding that competence emerges from chaos, not from clarity. Your first attempts will be embarrassingly bad because your brain is literally constructing the neural infrastructure required for skill. The timeline for moving from "terrible" to "decent" is always longer than you expect because biological change operates on its own schedule.
Most people never reach competence because they interpret the gap between where they are and where they want to be as evidence they're not cut out for it. They quit during the exact window when their brain is doing the rewiring that would eventually make them good.
The secret is learning to love that window. The period that feels like failure is actually the period when your brain is working hardest on your behalf. The discomfort you're avoiding is the discomfort of becoming someone new.
Based on this post by Karpathy, I was able to launch https://t.co/4eUhI0xyNm an entrepreneurial wiki based on my favorite writers and books.
I’m having a blast just reading through its findings!
LLM Knowledge Bases
Something I'm finding very useful recently: using LLMs to build personal knowledge bases for various topics of research interest. In this way, a large fraction of my recent token throughput is going less into manipulating code, and more into manipulating knowledge (stored as markdown and images). The latest LLMs are quite good at it. So:
Data ingest:
I index source documents (articles, papers, repos, datasets, images, etc.) into a raw/ directory, then I use an LLM to incrementally "compile" a wiki, which is just a collection of .md files in a directory structure. The wiki includes summaries of all the data in raw/, backlinks, and then it categorizes data into concepts, writes articles for them, and links them all. To convert web articles into .md files I like to use the Obsidian Web Clipper extension, and then I also use a hotkey to download all the related images to local so that my LLM can easily reference them.
IDE:
I use Obsidian as the IDE "frontend" where I can view the raw data, the the compiled wiki, and the derived visualizations. Important to note that the LLM writes and maintains all of the data of the wiki, I rarely touch it directly. I've played with a few Obsidian plugins to render and view data in other ways (e.g. Marp for slides).
Q&A:
Where things get interesting is that once your wiki is big enough (e.g. mine on some recent research is ~100 articles and ~400K words), you can ask your LLM agent all kinds of complex questions against the wiki, and it will go off, research the answers, etc. I thought I had to reach for fancy RAG, but the LLM has been pretty good about auto-maintaining index files and brief summaries of all the documents and it reads all the important related data fairly easily at this ~small scale.
Output:
Instead of getting answers in text/terminal, I like to have it render markdown files for me, or slide shows (Marp format), or matplotlib images, all of which I then view again in Obsidian. You can imagine many other visual output formats depending on the query. Often, I end up "filing" the outputs back into the wiki to enhance it for further queries. So my own explorations and queries always "add up" in the knowledge base.
Linting:
I've run some LLM "health checks" over the wiki to e.g. find inconsistent data, impute missing data (with web searchers), find interesting connections for new article candidates, etc., to incrementally clean up the wiki and enhance its overall data integrity. The LLMs are quite good at suggesting further questions to ask and look into.
Extra tools:
I find myself developing additional tools to process the data, e.g. I vibe coded a small and naive search engine over the wiki, which I both use directly (in a web ui), but more often I want to hand it off to an LLM via CLI as a tool for larger queries.
Further explorations:
As the repo grows, the natural desire is to also think about synthetic data generation + finetuning to have your LLM "know" the data in its weights instead of just context windows.
TLDR: raw data from a given number of sources is collected, then compiled by an LLM into a .md wiki, then operated on by various CLIs by the LLM to do Q&A and to incrementally enhance the wiki, and all of it viewable in Obsidian. You rarely ever write or edit the wiki manually, it's the domain of the LLM. I think there is room here for an incredible new product instead of a hacky collection of scripts.
Still pretty impressive how much utility we’ve derived from memory machines.
I like this benchmark but I also think it will be added to the pre-training over time and lose relevancy
🚨 Shocking: Frontier LLMs score 85-95% on standard coding benchmarks. We gave them equivalent problems in languages they couldn't have memorized. They collapsed to 0-11%.
Presenting EsoLang-Bench.
Accepted to the Logical Reasoning and ICBINB workshops at ICLR 2026 🧵