Building @jazz_tools v2 in public, Ep 3
Main learning: ground your LLMs in your concrete problem, build jigs, religiously optimize code iteration speed.
The last couple days were more perf work, driven by a specific target that a commercial use case gave us.
Optimization un/fortunately has always been extremely addictive to me: a giant puzzle with a clear reward function.
LLMs are good at it for the same reason. They especially help with the tedious parts: run the benchmark, interpret profiles, correlate with code impl, small thesis, small experiment, rebuild, remeasure, repeat.
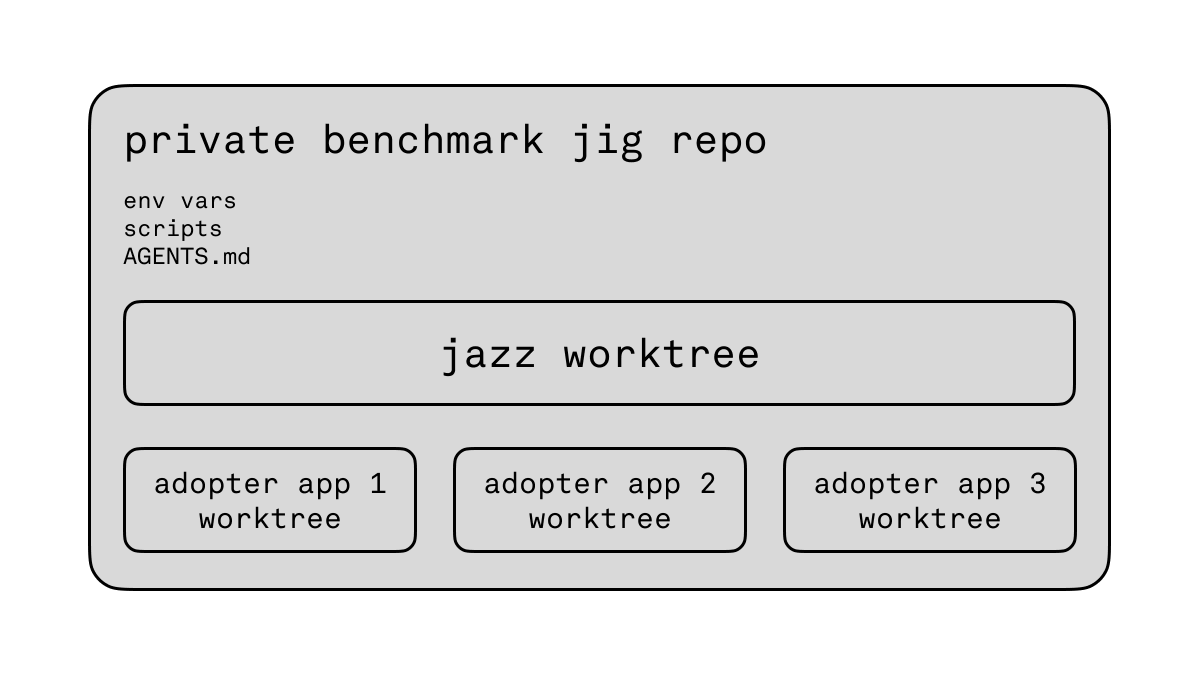
This already worked well for our synthetic benchmarks in our monorepo, but here we were particularly interested in perf in a concrete adopter app, in their own repo, under NDA, etc.
And what mattered here was end-to-end performance including the jazz server and their use of jazz in their app’s frontend. For a while I was manually getting the app in the right state, profiling, then feeding the profiles to codex. I was the slowest element in the process. Annoyingly, browser automation was similarly slow.
So I set up a private meta-repo that had links to a jazz worktree and a worktree of the adopter app. Made codex set up a small jig that directly imported their app code and ran only the perf-relevant part in bun, bypassing all the app setup around it.
This shortened the iteration cycle to around 10s (plus Rust build times) and meant codex could reliably iterate on the problem autonomously.
In one afternoon of using this setup we found more optimization opportunities than I had in the entire week before, speeding up one particular load pattern by about 24x
I’m now using this same jig to optimize cache re-use of subqueries across similar queries, especially for row-level-security policy evals, allowing me to try different designs super quickly. And again, both performance and correctness are grounded in adopter apps that actually are more demanding and intricate than any synthetic benchmarks we could have come up with this early.
The longer-term goal is to extend this to as many adopter apps as possible and to automate measuring the effect of changes to jazz on real apps even more.
Our North Star here is the equivalent of the “crater run” of the Rust compiler that is run over a large amount of (all?) public rust crates, being a comprehensive check of compile success and performance over the broad ecosystem.
Fluid migrations are one of the most novel features of @jazz_tools v2.
Inspired by @inkandswitch's Cambria paper, they re-imagine what migrations are:
- not a stop-the-world global mutation
- but bidirectional lenses (mappings)
- translating between a pair of schema versions
- that can be chained
This solves the problem of backwards and forwards compatibility of old and new clients in a local-first distributed apps.
It's also good for any kind of app: whether you're a single dev with a horde of Claudes, or a large org continuously rolling out features behind feature-flags, everyone is shipping more app features in parallel. And fluid migrations remove the last coordination bottleneck there (schema evolution).
But the novelty also means that we have to work out the developer experience around fluid migrations from scratch. This is partly the CLI workflows that we're iterating on and partly good docs that make the concept intuitive.
Yesterday, I woke up to this sick interactive diagram that Joe (who does our docs and carries the Discord server) built, which lets you play through different scenarios of schema and client versions and shows clearly how the migration lenses translate appropriately.
Link below if you want to play with it yourself.
Soon, we will probably incorporate a version of this into the Jazz inspector, so you can reason about the exact schema versions and how your own data gets translated in your app.
Let me know if this made sense or if you have any questions!
As promised, yapping more on @jazz_tools
After launching the v2 alpha at @ReactMiamiConf our focus has been polish and perf, and there is a lot to do.
Often, refactoring and nailing down semantics go hand in hand with performance.
We realized this again over the last couple days, working on clarifying the difference between “batches” and “transactions”.
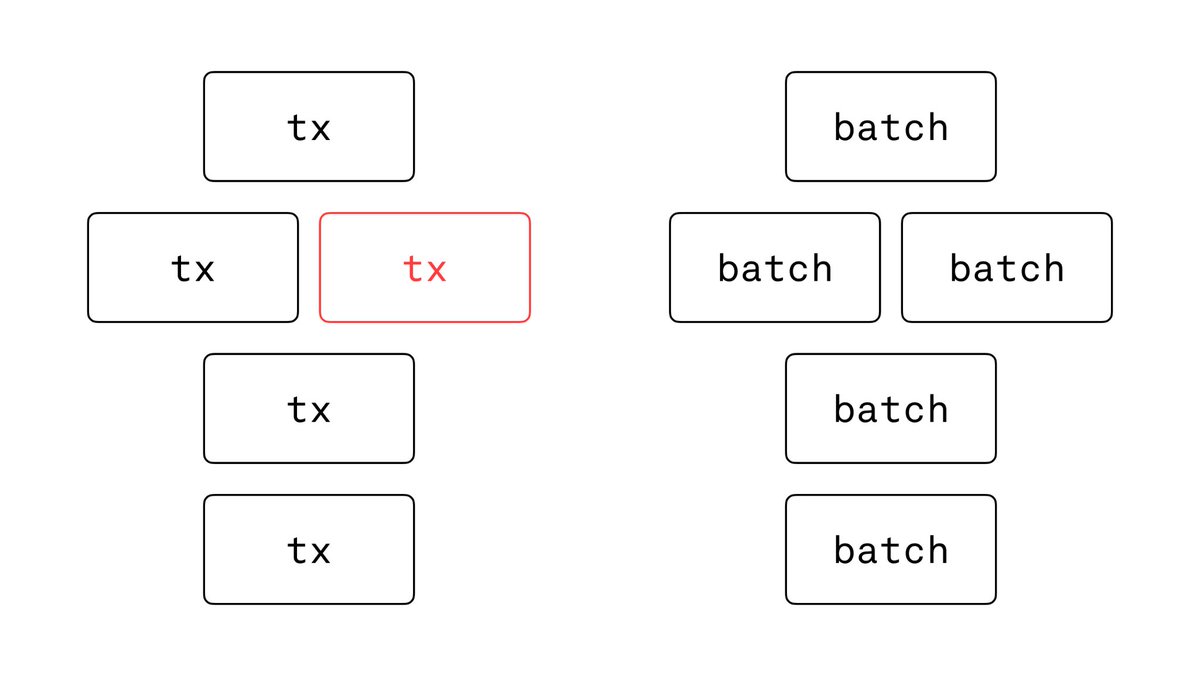
Jazz v2 is unique in that it offers both globally consistent MVCC-style ACID transactions as well as local-first, eventually consistent writes (this is actually the default).
But then we realized that even for the eventually consistent writes, it sometimes makes sense to group them into units, which we called “batches”.
Initially, we thought of this as a pure perf optimization primitive and were quite loose with their semantics compared to transactions, where strictness really mattered.
For example, in transactions you clearly want all-or-nothing and rollbacks, but we didn’t really think this was important for batches.
But then, trying to actually implement the perf optimizations, we realized that per-row bookkeeping in large batches made them basically pointless.
So perf guided us towards a clearer meaning for batches: they should also be all-or-nothing, now only being separated from transactions by one clear distinction: multiple concurrent batches can all be accepted and participate in merge-previews, while only one of multiple transactions gets accepted, resulting in global consistency and linearizability.
With all the rows per batch sharing one fate, the bookkeeping overhead disappears and the decision for which tool to use in each case becomes crisp:
- eventual consistency ok but need operations to have truly independent fates? Use separate batches.
- eventual consistency ok and operations sharing fate ok or even desired as a logical unit? Use one batch.
- need global consistency? Use a transaction.
It’s fun to see how this loosens up complexity throughout storage format, query subscription updates, sync protocol etc.
Now that the @jazz_tools v2 alpha is out, we're iterating on polish and performance. I knew there would be lots of low-hanging fruit, but today was particularly juicy.
Or a "pretty spectacular little gremlin hunt" as codex would of course say.
In SF tomorrow?
I’ll give a mini version of my “four fresh ideas for local-first” Jazz v2 launch talk!
With the creators of three great syncing databases / sync engines in one place, this is a great opportunity to learn about the space and the different tradeoffs!
luma in Wayne’s post:
huge congrats again to the winners of the "best app that uses Jazz" prize at the @FrontierTechWk hackathon.
incredible strategy of using all the sponsor technologies in one stack 👍
PRIZE ANNOUNCEMENT!
Jazz Tools is coming through with an amazing prize pack including a Xteink X4 Ereader for the team with the best use of @jazz_tools as your DB!
Don't miss it → April 22 → Between @AIEMiami and @ReactMiamiConf ↓
Miami was a vibe.
@ReactMiamiConf lives up to all the hype.
Met so many old friends, so many of the OGs for the first time and a surprising number of eager, fresh developers.
It’s still all about the people, and always will be.
Wholesome, high-caliber, fun as hell.
Shout out to the great people at @jazz_tools for supporting us as a Pit Crew Sponsor!
Jazz is the database that syncs. Efficiently sync data, files and LLM streams. Use them like reactive local JSON state.
https://t.co/mIIIm059FB
Wow seems like I disagree with literally everyone after a decade+ of using RLS
But learning that Supabase schemas are public by default (!!) and imagining less technical people grappling with getting RLS exactly right…
Will have an answer to this in product & text shape soon!
PRIZE ANNOUNCEMENT!
Jazz Tools is coming through with an amazing prize pack including a Xteink X4 Ereader for the team with the best use of @jazz_tools as your DB!
Don't miss it → April 22 → Between @AIEMiami and @ReactMiamiConf ↓