🚀 Muse Spark Safety & Preparedness Report for Meta AI is out.
We start with our pre-deployment assessment under Meta's Advanced AI Scaling Framework, covering chemical and biological, cybersecurity, and loss of control risks. Our assessment flagged potentially elevated chem/bio risk, so we implemented safeguards and validated mitigations before deployment - bringing residual risk to within acceptable levels.
Beyond the Framework, we also share findings and early explorations of model behavior (honesty, intent understanding, etc.), jailbreak robustness, eval awareness, and more.
We're sharing this report to give a closer look at how we evaluate advanced AI safety. Always more work to do, and we welcome feedback from the community.
https://t.co/azpKHwu7x9
1/ today we're releasing muse spark, the first model from MSL. nine months ago we rebuilt our ai stack from scratch. new infrastructure, new architecture, new data pipelines. muse spark is the result of that work, and now it powers meta ai. 🧵
Today our AI security team @ Meta launched open source tools to support the open source GenAI ecosystem, including:
- LlamaFirewall; a security-first guardrail framework for mitigating agentic prompt injection, misalignment, and insecure coding risks: https://t.co/lNxQB34jmz
You thought LLM chatbots required a lot of compute? That's cute. It's when fully-generative TikTok/YouTube hits the mainstream that you'll start needing a *lot* of GPUs. Orders of magnitude more compute, both because the medium is more intensive and because the audience will be 5x-10x larger. For now we've barely scratched the surface.
AGI doesn't seem to be getting any closer, but the practical applications of scaling up deep learning aren't going to slow down.
LIMA, a 65B LLaMa fine-tuned only with supervised learning on 1000 curated examples, without any RLHF, demonstrates remarkably strong performance, generalizes well to unseen tasks not in training data. Comparable to GPT-4, Bard, DaVinc003 in human studies.https://t.co/vNuecWIP5K
I suspect GPT-4's performance is influenced by data contamination, at least on Codeforces.
Of the easiest problems on Codeforces, it solved 10/10 pre-2021 problems and 0/10 recent problems.
This strongly points to contamination.
1/4
Happy 2021 from the AIxD team to you and yours! To a year of connection, creativity, learning, growth, collaboration, and joy 🎆this wish comes accompanied by @jctestud's pix2pix generated fireworks
Introducing #Imaginaire
a #PyTorch library with optimized implementations of several #GAN image and video synthesis methods developed at #NVIDIA
code https://t.co/fWMHEwhS3q
video https://t.co/BUkEE7RB3D
By @liu_mingyu@tcwang0509@arunmallya @xunhuang1995
Life of a paper:
1. Appears on arXiv
1.001. @ak92501 and I tweet
1.002. @lucidrains makes a repo
2. The author tweets
3. Appears on ML subreddit
4. @hardmaru tweets
5. @ykilcher makes a video
Aleph-0. Rejected by reviewers for "lack of novelty"
0. Conceived by Jurgen in 90s
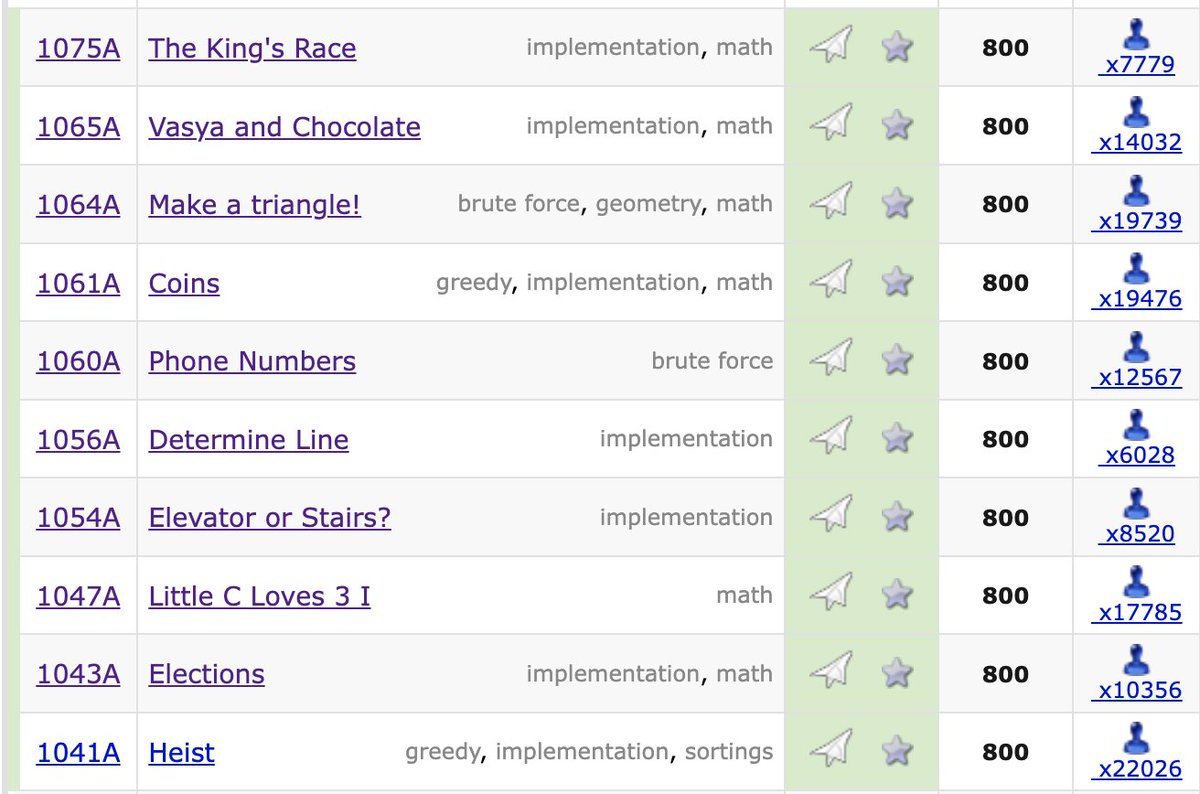
Unsupervised Translation of Programming Languages. Feed a model with Python, C++, and Java source code from GitHub, and it automatically learns to translate between the 3 languages in a fully unsupervised way. https://t.co/FpUL886KS7
with @MaLachaux@b_roziere @LowikChanussot
Every once in awhile a paper comes out that makes you breathe a sigh of relief that you don't publish in that field...
https://t.co/56heAufhGA
"Our results show that when hyperparameters are properly tuned via cross-validation, most methods perform similarly to one another"
Inspired by @minsukkahng amazing works, I also played with visualizations of the GAN training process. And it really can give cool insights on why the GAN works at all. I made a Colab notebook, and you can also try to tune various hyperparameters. https://t.co/fL8O5HdXeu
In the early days, the model didnt know English (we didnt show it any lyrics) and so it used to just make words up. Led to some uncanny samples like this one. I love that it gets the spacy vibes of David Bowie!
https://t.co/MvJBMy7Tpf
"You can't learn language from the radio." 📻
Why does NLP keep trying to?
In https://t.co/yWEnq5QW9R we argue that physical and social grounding are key because, no matter the architecture, text-only learning doesn't have access to what language is *about* and what it *does*.
How can you successfully train transformers on small datasets like PTB and WikiText-2? Are LSTMs better on small datasets? I ran 339 experiments worth 568 GPU hours and came up with some answers. I do not have time to write a blog post, so here a twitter thread instead. 1/n
Our new paper, Deep Learning for Symbolic Mathematics, is now on arXiv https://t.co/cxAa3upB6h
We added *a lot* of new results compared to the original submission. With @f_charton (1/7)
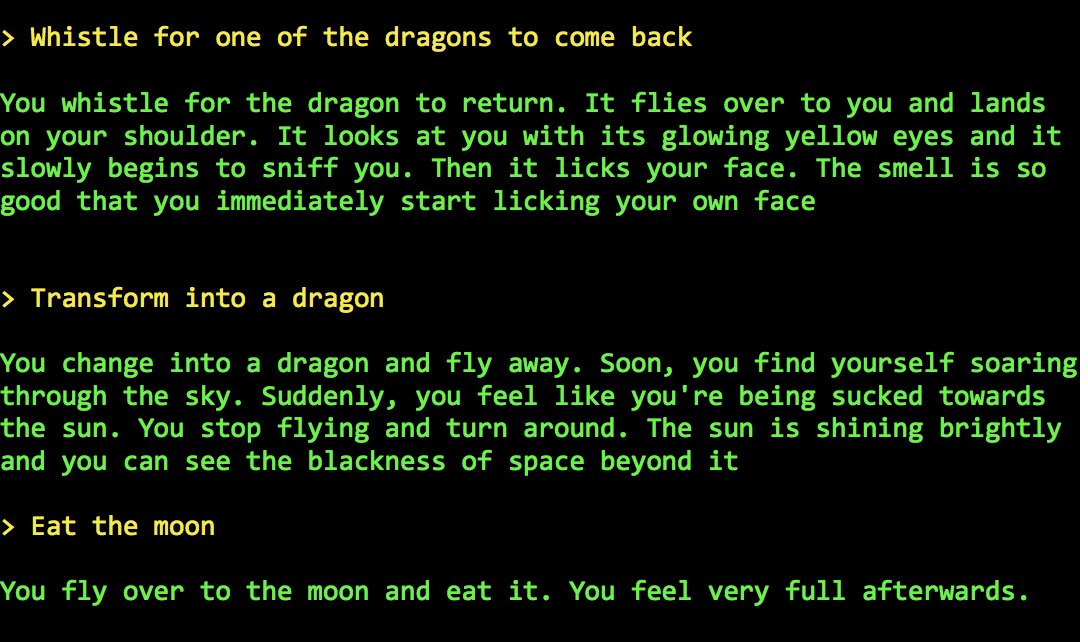
You MUST play AI Dungeon 2, a text adventure game run by a neural net.
@nickwalton00 built it using @OpenAI's huge GPT-2-1.5B model, and it will respond reasonably to just about anything you try. Such as eating the moon.
https://t.co/3ovYyEMWpf