https://t.co/k7JtGgr4xu funciona amb models lliures: Llama 4 per a tasques de filtratge i gpt-oss-120b de generació, els dos models de pesos lliures. Amb https://t.co/dvoubkn8nj gasto un euro al mes, 10-15 cops més barat que amb Gemini o GPT de mida similar. La pipeline és👇
Els professors catalans haurien de fer una vaga a la japonesa. Omplir de deures els nens i exigir el nivell que correspon a cada curs. Suspendrien el 75% o més dels alumnes i col·lapsaria el sistema.👇🏼
La idea de les webs que afegeixen transparència és molt bona. Ens cal el mateix, però amb la part dels impostos que s'envien a l'estat espanyol i no tornen i que la Generalitat estima en +20.000 M€ anuals.
👋 Hola, Ministerio de Transformación Digital, @mintradigital:
👋 Hola, Secretaría de Estado, @SEtelecoGob:
Autofirma es un componente esencial de la Administración Electrónica española. Millones lo utilizamos para relacionarnos con la Administración. No por placer, sino porque es ✨requisito✨.
----8<----8<----8<----8<----8<----8<----
El paquete de Autofirma que distribuís para Mac no cumple las garantías de seguridad modernas (notarización), así que el sistema dice que es malware que puede dañar el sistema y rechaza instalarla. 😃🔫
----8<----8<----8<----8<----8<----8<----
🤦 Para instalarla hay que —ojo al dato— desactivar las políticas de ciberseguridad del sistema operativo. 🤦
¡Hola, @INCIBE! Hacéis campañas fabulosas para concienciar a la ciudadanía de los riesgos de ciberseguridad, pero luego nos enjaretáis —el Estado— marrones como este. ¿Podéis hacer algo, por favor?
Respetado ministro @oscarlopeztwit:
Respetada secretaria de Estado @mariagv:
— Si hacéis software, cumplid los estándares modernos de empaquetado y distribución de software.
— Si no podéis notarizar Autofirma, modernizad la arquitectura del programa para que se pueda.
— Si no podéis modernizar Autofirma, necesitamos un Ministerio para la Transformación del Ministerio de la Transformación Digital.
Esto es lo que ve un usuario al intentar instalar Autofirma en un Mac:
🔥 Freepik ahora es Magnific! 🔥
Rebranding completo.
Os cuento la historia de cómo dos murcianicos crearon la startup bootstrapped de mayor crecimiento de la historia y su historia de amor con Freepik 🧵👇
@barckcode Crees que el sistema puede ser suficientemente robusto para ponerlo en algún sistema en producción? Por ejemplo para un chatbot de documentación de una página web?
Basit ve güzel bir anlatımla " tüm çokgenlerin dış açılarının toplamının neden 360 derce olduğunun ispatı. Hiç bir çocuk bu şekilde anlatıldığında bunu unutmaz.
Mañana se viene vídeo épico! 🤘
Hay un furor de locos con Gemma 4, especialmente el modelo 26B, porque se puede ejecutar en máquinas de consumo y algunos benchmarks lo ponen por encima de modelos mucho más grandes.
Pero hasta ahora no he visto un vídeo donde lo pongan a prueba de verdad.
Así que había que hacerlo. Y se hizo 😎
Mañana verás cómo he probado 7 tipos de tareas diferentes:
👉 Resumen de textos largos
👉 Traducción
👉 Flujos de publicación en redes (esta que enlazo salió de ahí)
👉 Uso de skills y herramientas de terminal
Y muchas cosas más, entre ellas, por supuesto, programación.
Le lancé el reto de una pequeña app, y verás los resultados 😁
¿Hemos llegado a la era de los modelos en local?
Mañana lo verás! Y será primero aquí, en X, a las 10 de la mañana.
Follow para no perdértelo!
@antonioleivag Confirmado, lo he probado con LM Studio y la diferencia en velocidad es enorme. No sé si hay algo incorrecto en la configuración de ollama. Investigaré, pero de momento voy a probar estos modelos en local. Gracias por el vídeo: https://t.co/B4qMUI63ef
🔴 NECESITO TU ATENCIÓN
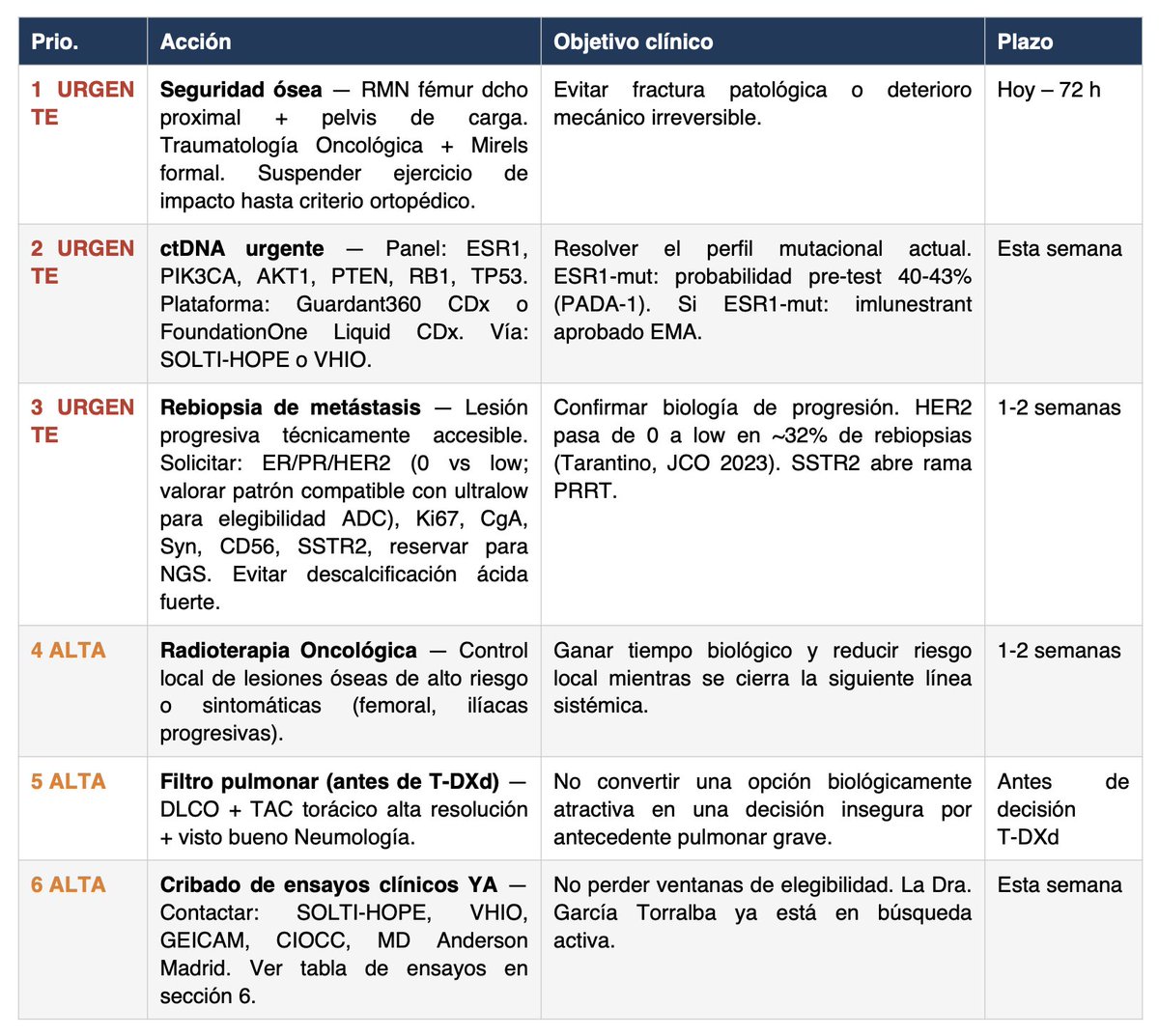
Llevo una semana ayudando a Miriam en su caso de cáncer metastásico y quiero compartir la metodología que he estado usando porque es absolutamente replicable.
Pienso que, con suerte, puede ser ÚTIL A OTRAS PERSONAS con cáncer (o con cualquier otra enfermedad).
Los resultados que hemos conseguido no son un milagro, pero pensamos que son realmente útiles y pueden significar una diferencia crucial en un caso médico de vida o muerte.
Aquí va paso a paso el método:
1/ Usar los modelos más avanzados del momento (por desgracia de pago, y no son baratos, opino que Sanidad Pública debería invertir en esto):
- ChatGPT Pro + Extended (40min de pensamiento aprox por llamada)
- Claude Opus 4.6 MAX
Pendientes de probar a fondo:
- Perplexity Sonar Pro
- Notebook LM
2/ Dárselo MUY MASCADO a la IA todo el historial. Esto parece una tontería pero es muy importante.
- Lo primero que pido, con Claude Cowork que tiene acceso al disco duro, es que entre en la carpeta en la que está TODO EL HISTORIAL (pueden ser más de 100 pdfs) y lo unifique todo en:
- Un único PDF (puede ser de más de 1000 páginas o lo que sea necesario)
- Un único txt legible, que debe hacer correctamente usando un script con OCR y luego comprobar con lupa que está bien hecho.
Insisto: no saltar al siguiente paso antes de tener muy bien hecho lo anterior, sobre todo el txt.
3/ Una vez tenemos lo anterior utilizar este prompt junto con el txt y el PDF como archivos de entrada y lanzarlo en AMBOS modelos (y en más si es posible) a la vez.
👉 Os lo dejo aquí, este prompt es increíble complejo/avanzado: https://t.co/KEEWc8WNvW Está pensado para el caso concreto de Miriam, pero con los modelos del punto 1/ podrías adaptarlo a tu caso particular sin problemas.
4/ La PUNTA DE FLECHA enfrentando un modelo al otro: esta metodología no la he escuchado a nadie, pero funciona increíblemente bien. La sensación es la de ir afilando una estaca hasta que adquiere una punta reluciente.
Funciona así: con paciencia y en sucesivas iteraciones (aconsejo mínimo 5 veces, y en en cuenta que si ChatGPT tarda 40min te va a llevar un buen rato) enfrenta el resultado (el PDF) de un modelo a otro. Con un prompt sencillo del estilo:
"Otro comité de expertos opina esto. ¿Cómo lo ves? Si estás de acuerdo o lo contrario dime por qué, y genera un nuevo PDF si lo ves preciso".
El resultado se lo cruzas al modelo contrario. Así, en sucesivas iteraciones, búsquedas de internet, papers, etc. irán encontrando y afilando más cosas.
¿Cuándo acabar? Cuando AMBOS modelos digan que está perfecto y no puedan mejorar más el trabajo del contrario. Esto es tan absurdamente rompedor que pienso que los resultados de TODOS los modelos actuales mejorarían si siguieran esta metodología (apoyándose en una espiral rollo "adversarial model". No entiendo por qué nadie se ha dado cuenta de esto, si lo ha hecho, por qué no se le da más bombo. Funciona impresionantemente bien en cualquier ámbito, inclusive programación y matemáticas.
Es mas, mi teoría es que esto podría hacerse todavía mejor haciéndolo no solo con dos modelos: sino con una mayor combinatoria, añadiendo quizás Perplexity Sonar Pro, etc.
RESULTADOS
Increíbles. Obviamente no puedo saber si mejores que el mejor de los comités científico-sanitarios del mundo, pero le están dando a Miriam una nueva dimensión del caso, tests adicionales que hacer, posibles pruebas, etc.
Obviamente la IA milagros no hace, pero pienso que puede ya, a día de hoy, ayudar a muchos pacientes. Y Sanidad Pública debería invertir mucho, pero mucho, en esto.
Voy a preguntarle a Miriam si puedo poner el PDF completo de resultados más avanzado que conseguimos, para que os hagáis una idea de su calidad. Ya me ha dado más o menos permiso, pero quiero asegurarme 100%.
Tengo 35 años y cancer de mama metastásico, un caso raro, menos del 1% de tumores de mama son como el mío y hay poca documentación sobre ello.
Por eso me gustaría encontrar personas que se dediquen a esto y que quieran investigar con mi caso. Twitter haz tu magia
Administración pública ❤️ PDF
¿Por qué esta querencia?, ¿¡por qué!?
PDF tiene su lugar, claro que sí. Pero PDF no debería ser el formato por defecto para publicar.
—¿Cuál lo es, entonces?
—La web.
Muchos de los documentos que la Administración publica en PDF deberían estar publicados en la web. En HTML.
1️⃣ Un documento web está vivo. Puede evolucionarse. Actualizar un PDF, en cambio, implica redistribuirlo. Eso es una autopista al infierno: ¿cuál es la última versión?, ¿quién tiene una antigua?, ¿tengo que descargar una nueva? 💀 Cuando la información se publica en la web, en cambio, todos estamos siempre en la última versión. 🎉
2️⃣ PDF es una representación digital de un soporte físico, generalmente un papel A4. Leer un PDF en el móvil es por ello tortuoso. La documentación web, en cambio, es adaptativa (responsive): el contenido fluye para amoldarse al contenedor, que es el dispositivo.
3️⃣ PDF no es un formato web. Cada vez que un organismo público publica o enlaza a un PDF está, literalmente, sacándote de la web. Pero mucha de nuestra tecnología está pensada para la web: navegadores, buscadores, redes sociales…
Hay muchas más razones, pero me quiero ir a comer. 😂
¡Redifunde esto, querido amigo! Ayúdame a que llegue a gobiernos y ayuntamientos. Necesitamos inspirar, hacer pedagogía para que todo mejore para todos.