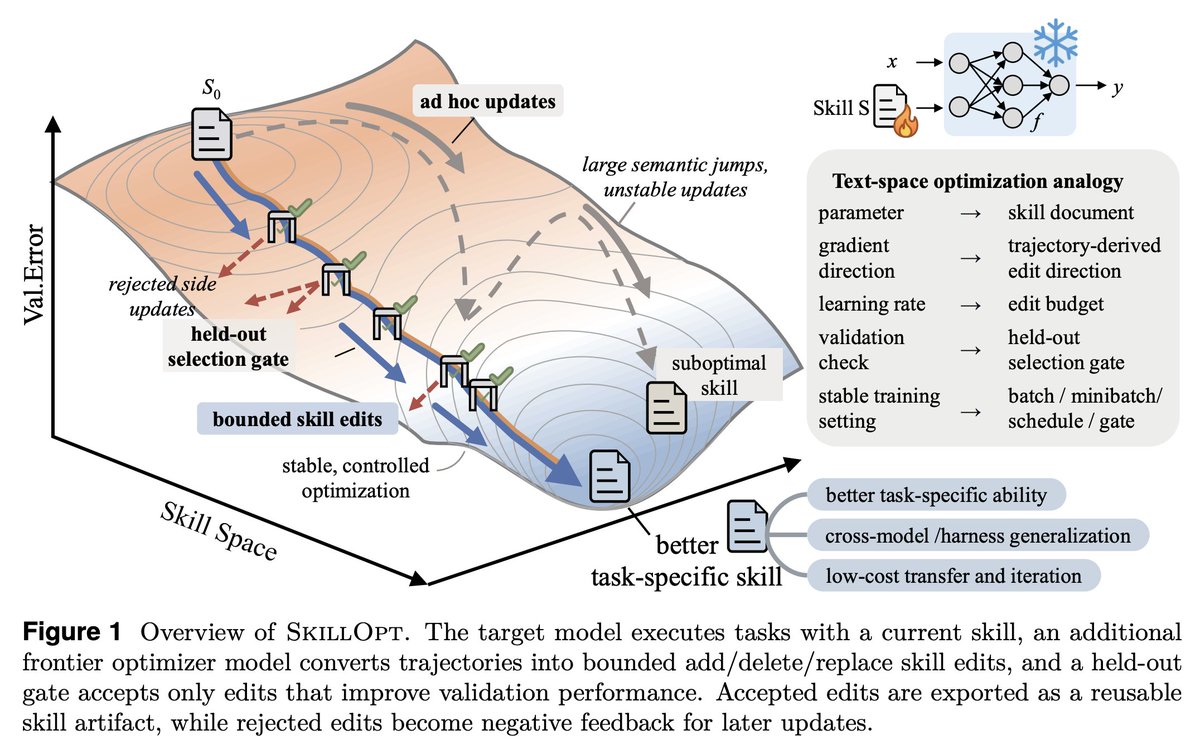
Gradient descent for SKILL.md files sounds interesting, maybe a bit complex but it's becoming a real part of agent harness.
SkillOpt is one of the first papers to treat markdown skill files as trainable parameters and provides a proper optimization framework for them.
A few things I learned that you should consider too.
1. The validation gate is the only thing that matters in a self-editing loop.
Held-out set, strict improvement, ties rejected. End-to-end, their best skills land with 1 to 4 accepted edits total. If your "self-improving agent" is accepting most of what it proposes, you're shipping slop.
2. Bounded edits are better than full rewrites. 4 to 8 edits per step is the sweet spot.
Remove the budget and performance collapses. This is the textual analog of learning rate, and it transfers to any LLM-as-author loop. If you're using an agent to refactor your docs, your prompts, or your skills, cap the diff size.
3. Compactness wins. Median final skill: ~920 tokens.
Skills do not need to be long. They need to be high-signal. Most skill files I see are bloated because length feels like effort. It isn't.
4. The harness is becoming less important; the skill is becoming more important.
A Codex-trained skill ported into Claude Code hit +59.7 points on SpreadsheetBench. Procedural knowledge is more general than the runtime that
produced it.
5. Frozen model + trained context is the practical adaptation.
GPT-5.4-nano with a SkillOpt'd skill ≈ frontier behavior on procedural benchmarks. Cheaper, portable, inspectable, zero inference-time cost. This is
the answer to "how do we adapt a frontier model for our domain" for almost everyone who isn't training their own models.
6. Verification is the bottleneck.
Every gate in this paper depends on an auto-grader. That works for benchmarks. It fails for writing, design, and strategy, exactly the open-ended work we want to automate. Whoever builds the verifier for open-ended tasks owns the next stage.
There are also two leassons I learned while shipping v2.3.0 of my Context Engineering Agent Skills repo, measured across composer-2, claude-opus-4-7,
gpt-5.5, and gemini-3.1-pro via the @cursor_ai SDK:
- Description and body are two different surfaces. The router only sees the description. The agent sees the body once activated. They can quietly disagree, and only end-to-end task tests catch it.
- Aggregate accuracy is the wrong unit. When I rewrote three descriptions, the corpus average moved ~1pp. Individual skills moved 23–25pp. Per-skill effect size is where the action is.
Also, in Feb 2026 I shared a piece called Personal Brain OS arguing that the markdown file is a first-class substrate for agent state. SkillOpt is the optimizer-shaped version of that same argument: not "store memory in files" but "treat files as trainable parameters with proper optimization machinery around them." That's the move from static to measured.
The fast/slow split they describe already lives implicitly in the digital-brain-skill repo:
- voice-guide and tone-of-voice.md are slow-state (rarely touched)
- posts.jsonl and bookmarks.jsonl are fast-state
What SkillOpt adds that I didn't have is a protected section invariant, a structural guarantee that fast edits cannot overwrite slow lessons. Removing that mechanism cost them 22 points on SpreadsheetBench. Worth borrowing.
If you're building agents, SkillOpt: Executive Strategy for Self-Evolving Agent Skills is a good paper to read: https://t.co/ZS9SZXQ6Mv
AI agents are advancing research-level math. 🚀
I’m thrilled to share @GoogleDeepMind’s AlphaProof Nexus - an agentic framework for formal proof search powered by Gemini.
When applied to a set of open formal math problems, our agent autonomously solved:
✅ 9 open Erdős problems (including two open for 56 years!)
✅ 44 Online Encyclopedia of Integer Sequences (OEIS) problems
✅ A 15-year-old open problem in algebraic geometry ✅ A 7-year-old open question in min-max optimization
We are collaborating with mathematicians across disciplines - from combinatorics and graph theory to quantum optics. Ultimately, these results show the massive potential of even simple agentic loops powered by Gemini.
Read the paper here: https://t.co/c5M9ZjRXU1
Spark 2.0 is here! 🚀
We’re redefining what’s possible on the web with a streamable LoD system for 3D Gaussian Splatting.
Built on Three.js, you can now stream massive 100M+ splat worlds to any device from mobile to VR using WebGL2. All open-source.
Dive into the tech 👇
How do we process long videos efficiently without losing crucial information?
NVIDIA, Stanford University, and National University of Singapore have an answer!
They introduce InfoTok, a breakthrough method inspired by Shannon's information theory. It intelligently allocates data tokens to video frames based on their informational richness, avoiding both redundancy and loss. Think of it as a smart compressor for video.
InfoTok delivers state-of-the-art video compression, saving 20% tokens without performance impact and achieving 2.3x higher compression rates than prior adaptive methods. Big step for video AI!
InfoTok: Adaptive Discrete Video Tokenizer via Information-Theoretic Compression
Paper: https://t.co/23nv7y1Ozi
Project: https://t.co/3A7wO8SySM
Code: https://t.co/FWUxi9UISW
Our report: https://t.co/erYlvxdqdQ
📬 #PapersAccepted by Jiqizhixin
Three years ago we started working on a stealth project that we weren’t sure we’d ever talk about publicly... until today.
Breakthrough: Introducing LFM-Zero: the first foundation model trained on 0 tokens.
No pretraining. No finetuning. No data. Instead, we initialize from an implicit probabilistic prior over the underlying data-generating process, allowing the model to converge without ever observing data.
LFM-Zero matches or surpasses models trained on 10T+ tokens across reasoning, coding, and multimodal tasks. Turns out that pretraining was just regularization that was holding us back.
> Read our Tech Report here: https://t.co/aIWbx77IEf
🚀 #CVPR2026 paper alert: 🦏 RINO: Rotation-Invariant Non-Rigid Correspondences
Our network learns robust SO(3)-invariant features directly from raw 3D geometry. End-to-end, no pre-alignment or handcrafted descriptors!
Joint work @tumcvg & @Stanford.
you can instantly 10x your vibecoded frontends by just learning what different ui components are called
ofc opus is creating generic slop, the only words you know are menu and button.
Robots can now reconstruct 3D scenes in real time from a single RGB camera.
[📍 Projects page + paper]
No depth sensor. No retraining. 30 FPS.
Researchers at the Imperial College London introduced KV-Tracker, a training-free method that makes heavy models like π³ and Depth Anything 3 fast enough for real-time tracking.
The idea is simple.
These models use global self-attention, which is powerful but computationally expensive.
KV-Tracker caches the key and value pairs from selected keyframes and reuses them for new frames.
That cache becomes an implicit scene representation.
Result:
• Up to 30 FPS
• 10 to 15x speedup
• Accurate 6-DoF tracking on benchmarks like TUM RGB-D and 7-Scenes
• Works with monocular RGB only
It also supports object-level tracking with masks and allows saving the KV-cache for later reuse.
For robotics, this reduces hardware constraints and moves real-time 3D perception closer to practical deployment.
Credit to Marwan Taher (@marwan_ptr) at Imperial’s Dyson Robotics Lab and many others who contributed to this!
📍 Save projects page + paper for later:
https://t.co/IxgTl19zZ7
Video: https://t.co/wVxLhd6VpP
——-
if it matters in AI or Robotics you'll read it here first: https://t.co/9Nm01QUcw3
Sharing on behalf of a friend:
"""
New compute & funding opportunity for researchers!
We're launching the 2026 Google TPU Research & Education Awards.
We want to support researchers pushing the boundaries of ML systems, performance, and efficiency, and those working in high-impact applied science.
What's included:
- Compute: Free access to the latest generations of TPUs.
- Funding: An unrestricted gift to support or partially support a grad student.
- Credits: Google Cloud credits to support your work.
If you or a colleague are exploring what is possible with TPUs, we want to hear from you.
Read the RFP and apply here: https://t.co/mu6GvkKx3D
If you have questions, email [email protected]
"""
Google and Microsoft just co-authored the spec that turns every website into an API for AI agents. The second-order effects here are massive.
Right now, browser agents work by taking screenshots, parsing the DOM, and guessing which buttons to click. It works about as well as you’d expect. Fragile, expensive, slow. WebMCP replaces all of that with a single browser API: navigator.modelContext. Websites register structured tools directly in client-side JavaScript. The agent reads a menu of available actions, calls them, gets structured data back. No scraping. No backend MCP server in Python or Node. The tools run inside the browser tab and share the user’s existing auth session.
Early benchmarks show ~67% reduction in computational overhead compared to visual agent-browser interactions. Task accuracy around 98%.
The second-order effect is where this gets wild. Today, when a browser agent visits two competing airline sites, it’s guessing at both interfaces equally. Once WebMCP adoption spreads, the site that exposes structured tools gives the agent a clean, reliable path to complete the task. The site that doesn’t forces the agent to fumble through the UI. Agents will prefer the cheaper path. Every time.
This means “Agent Experience Optimization” becomes a real discipline. Tool naming, schema design, description quality. Sound familiar? It’s the same shift that happened when meta descriptions and structured data became optimization surfaces for search engines. Except this time, the traffic source isn’t Google’s crawler. It’s every AI agent on the internet.
Bots already make up 51% of web traffic. Google just gave them a front door.
Google just mass-published how 34 researchers actually use Gemini to solve open math and CS problems. not benchmarks. not demos. real unsolved problems across cryptography, physics, graph theory, and economics.
145 pages of case studies. here's what actually matters:
@pmddomingos Agents are what happens when you let software engineers cosplay as researchers. The papers have more 'we integrated X' than actual novelty.
Byebye diffusion, say hello to Drifting models.
Drifting models will take over diffusion models within the next year.
I was told many times that we figured it all out, that there was nothing else to invent in generative AI and it was just about scaling. Wrong again and again.
🚨BREAKING: Someone just solved Claude Code's biggest problem.
It's called Claude-Mem and it gives Claude persistent memory across sessions.
- You can use up to 95% fewer tokens each time.
- Make 20 times more tool calls before reaching limits.
100% Opensource.