⭕️🤯 Starship Flight 12 : absolument renversant, les ondes de choc provoquées par les 33 moteurs Raptor. La poussée au décollage est deux fois supérieure à celle de la Saturn V Block II, faisant du Starship le lanceur le plus puissant jamais construit.
Its funny how much the whole "strawberry" thing, which turned out to be o1-preview, was dismissed as overhyped at launch when it is clear in retrospect that it was way underhyped.
A direct line from models unable to do basic math to solving unresolved math problems in 18 months.
4/
Rubik’s Cube solving has been a long-standing challenging benchmark for robotic manipulation. The task requires fine-grained control under the geometric and kinematic constraints imposed by the cube itself. Prior state-of-the-art is still the single-handed solver from OpenAI’ in 2019. For the first time, we can solve a Rubik's Cube using two hands together, powered by GENE.
🚀 Major update: We let the model design a multi-agent system — and it improved on ARC-AGI.
Self-evolution isn’t just the model improving itself. It’s the model acting as a researcher that designs other agents.
For single-agent tasks (coding, MCP-Atlas, etc.), we’ve shown the model can successfully design and evolve its own harness. But for harder tasks like @arcprize, the optimal solver is a complex multi-agent system.
The real question: Can the model evolve a multi-agent system from scratch?
We ran A-Evolve on ARC-AGI and proved yes — the model successfully evolved a multi-agent solver and achieved a clear performance uplift: 10% → 12%.
(Attached: one example task solutions of agent before & after A-Evolve)
Full results + details in the reply below 👇
#AgenticAI #AEvolve #SelfImprovingAgents #ARCAGI
🕳️💫 Ce timelapse exceptionnel, réalisé sur près de 20 ans avec le Very Large Telescope (VLT) de l’ESO, révèle des étoiles en orbite autour du trou noir supermassif Sagittarius A* au cœur de notre propre galaxie, la Voie lactée.
📄 : Instrument NACO sur VLT, ESO, MPE
On April 22, 1993, students Marc Andreessen and Eric Bina from the University of Illinois programmed one of the first web browsers with a graphical interface.
#InternetHistory
Only one chance in this lifetime…
Like watching sunset at the beach from the most foreign seat in the cosmos, I couldn’t resist a cell phone video of Earthset. You can hear the shutter on the Nikon as @Astro_Christina is hammering away on 3-shot brackets and capturing those exceptional Earthset photos through the 400mm lens. @AstroVicGlover was in window 3 watching with @Astro_Jeremy next to him.
I could barely see the Moon through the docking hatch window but the iPhone was the perfect size to catch the view…this is uncropped, uncut with 8x zoom which is quite comparable to the view of the human eye. Enjoy.
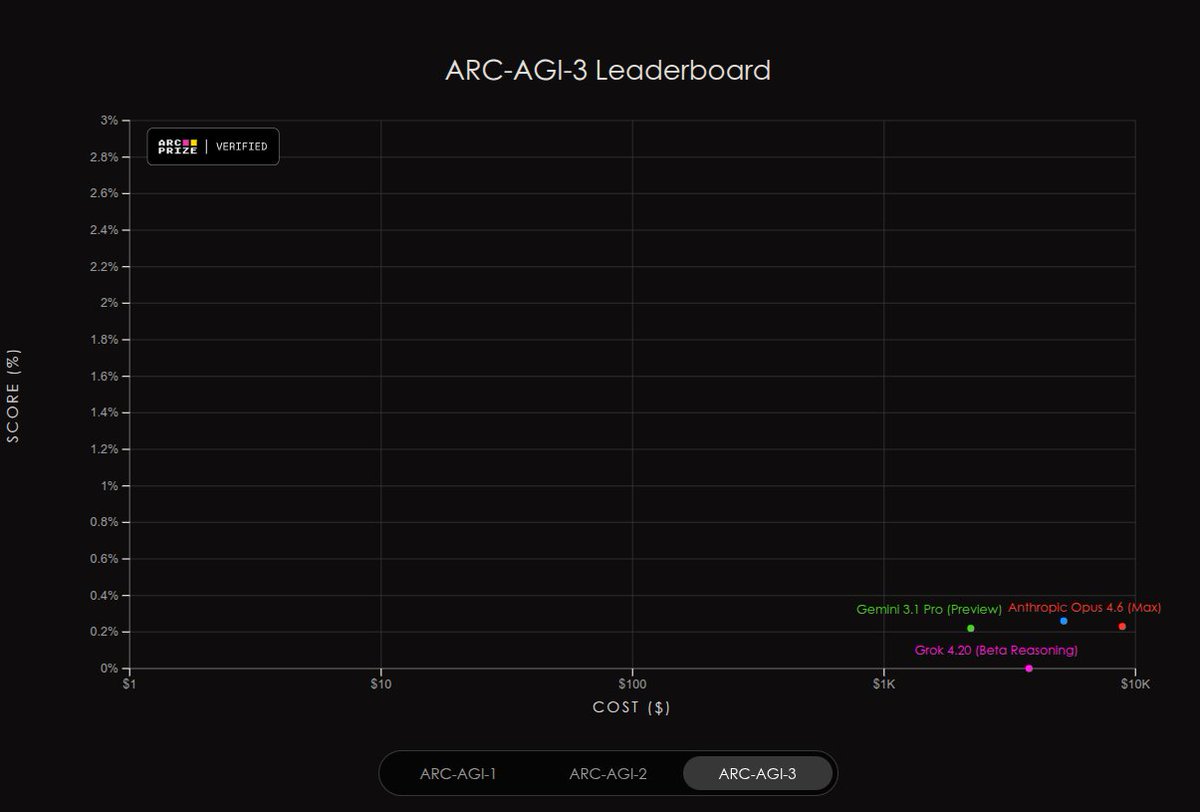
ARC-AGI-3 scores are out and all the top frontier models are scoring under 1%
A massive gap that the foundation says proves we don't have AGI yet.
- Google's Gemini 3.1 Pro Preview: ~0.3% (tops the board in some snapshots; costs vary but in the thousands per full eval).
- OpenAI's GPT-5.4 High: ~0.26–0.3%.
- Anthropic's Opus 4.6 (Max): ~0.2–0.25%.
📌 Why ARC-AGI-3 Different
Unlike previous ARC-AGI versions (which used static grid-based puzzles to test passive "fluid intelligence" and generalization from few examples), ARC-AGI-3 turns the test into interactive, game-like worlds. AI agents must:Explore unknown environments from scratch.
Discover goals and rules on the fly (no natural-language instructions or pre-loaded knowledge).
Build adaptable mental/world models.
Plan long-horizon sequences of actions.
Learn continuously from experience, update beliefs with new evidence, handle sparse feedback, and correct wrong hypotheses.
Do this efficiently, without brute-forcing or memorizing.
The full benchmark includes 150+ novel interactive environments (worlds) with nearly 1,000 level. Agents interact via an API in replayable sessions, and you can watch their decision timelines in structured replays.
Scoring here is based on skill-acquisition efficiency compared to humans (not just "did it solve it?").
Humans (tested on 10 random people per environment) achieve 100% by solving tasks with a baseline action count (using the 2nd-best human performer to avoid outliers). AI scores reflect how close they get to that human efficiency on average across tasks. This captures planning, memory, adaptation, and real-time reasoning over time.
Video might be the next intelligence substrate.
Strikingly, video models are beginning to exhibit the same emergent reasoning behaviors first observed in LLMs—multi-path search, self-correction, and layer specialization.
We demystify video reasoning and show it doesn’t happen frame-by-frame, but along diffusion steps.
🔗 https://t.co/JMaoz02OlF
📄 https://t.co/VnlDpxuwwE
So, what's next? ;)
This is really cool (and wild):
Scientists simulated a complete living cell for the first time. Every molecule, every reaction, from DNA replication to cell division.
The paper (Luthey-Schulten et al., Cell 2026, https://t.co/PXxXWKC8yp), just out today, used JCVI-Syn3A — a synthetic minimal bacterium with fewer than 500 genes. A 3D+time simulation of the full 105-minute cell cycle: DNA replication, protein translation, metabolism, division. Every gene, protein, RNA, and chemical reaction tracked through physical space.
It took years to build. Multiple GPUs. Six days of compute time per run.
And this is the simplest possible cell.
A human cell has ~20,000 genes. It lives in tissue. It interacts with neighbors. It differentiates. It responds to drugs in ways that depend on context we haven't fully measured.
Mechanistic simulation of the minimal cell costs 6 GPU-days for 105 minutes of biology. You cannot scale that to human cells. The complexity isn't 40x harder. It's exponentially harder.
This is why the field pivoted to data-driven models. You can't hand-encode the regulatory wiring of a human hepatocyte. But you can learn it — if you have the right perturbation data collected across enough diverse biological contexts.
The two approaches aren't competing. Papers like this generate the ground truth that future ML models need for validation. But the path to a clinically useful virtual cell runs through foundation models, not through scaling up mechanistic simulation.
Amazing work!
Un grand merci pour tous vos retours sur ce très long thread ahah.
Je ne le dis pas souvent, mais qu'est-ce que je suis content d'avoir créé ce compte.