𝐀𝐝𝐚𝐩𝐭𝐢𝐯𝐞 𝐀𝐮𝐭𝐨-𝐇𝐚𝐫𝐧𝐞𝐬𝐬 - New Research: Even frontier LLMs (Opus) powered SOTA self-improving agents 𝐟𝐚𝐢𝐥𝐞𝐝 on real-world task streams (e.g., Prediction Market). With the same 𝐟𝐚𝐢𝐥𝐮𝐫𝐞 𝐩𝐚𝐭𝐭𝐞𝐫𝐧: 𝐩𝐞𝐚𝐤 𝐞𝐚𝐫𝐥𝐲, 𝐭𝐡𝐞𝐧 𝐝𝐞𝐜𝐥𝐢𝐧𝐞. A single harness overfits to past patterns.
The problem isn't the LLM. The auto-harness must be adaptive.
We introduce 𝐀𝐝𝐚𝐩𝐭𝐢𝐯𝐞 𝐀𝐮𝐭𝐨-𝐇𝐚𝐫𝐧𝐞𝐬𝐬: a tree of regime-specific harness branches, with per-task routing at solve time. Same LLMs, same auto-harness machinery — but the harness now specializes per task instead of compromising across all of them.
Results vs 5 auto-harness baselines + human-designed harness on 3 real benchmarks:
🔸 PolyBench (5,075 prediction-market tasks): 80.9% vs 50.8%
🔸 CTF-Dojo (261 security challenges over 8 years): 50.2% vs 45.2%
🔸 FutureX (503 forecasting tasks ): 49.5% vs 47.5%
When you building a self-improving agent, two natural questions emerge: 𝐐𝟏: 𝐖𝐡𝐢𝐜𝐡 𝐦𝐨𝐝𝐞𝐥𝐬 𝐩𝐫𝐨𝐝𝐮𝐜𝐞 𝐭𝐡𝐞 𝐛𝐞𝐬𝐭 𝐡𝐚𝐫𝐧𝐞𝐬𝐬 𝐮𝐩𝐝𝐚𝐭𝐞𝐬? 𝐐𝟐: 𝐖𝐡𝐢𝐜𝐡 𝐦𝐨𝐝𝐞𝐥𝐬 𝐛𝐞𝐧𝐞𝐟𝐢𝐭 𝐦𝐨𝐬𝐭 𝐟𝐫𝐨𝐦 𝐡𝐚𝐫𝐧𝐞𝐬𝐬 𝐮𝐩𝐝𝐚𝐭𝐞𝐬?
Our new paper has counter-intuitive answers to both: they decouple from model capability, in opposite ways.
Q1 (who produces good updates): the updater's base capability barely matters.A 9B model (Qwen3.5) produces harness updates that match Claude Opus 4.6's. Best vs worst evolver gap ≤3.1pp.
Q2 (who benefits most): non-monotonic.Mid-tier solvers benefit the most. Strong-tier hits ceiling. Weak-tier benefits LEAST despite the most headroom — failing at two layers: skill activation (25% vs ~96% for strong) and adherence drift across trajectory (~4x steeper).
Tested across 7 evolver models × 6 solver agents × 3 agentic benchmarks (SWE-bench Verified, MCP-Atlas, SkillsBench).
Implication: don't pay frontier prices for both halves of the loop. Put capability budget on the agent (solver), not the evolver.
Thanks for sharing our research! Also want to highlight the infra behind this research which made it possible for us to run so much variants. Two more research on self-improving agents built on the same framework releasing coming weeks: online context-to-harness skill compilation, and adaptive auto-harness for long-running deployment. Code, evolved harnesses, and trajectories all releasing through the repo.
Paper: https://t.co/dztN2uJwlc
Repo: https://t.co/thtDN17b6f
Hugging face daily: https://t.co/XLt57l3mrF
𝐀𝐝𝐚𝐩𝐭𝐢𝐯𝐞 𝐀𝐮𝐭𝐨-𝐇𝐚𝐫𝐧𝐞𝐬𝐬 - New Research: Even frontier LLMs (Opus) powered SOTA self-improving agents 𝐟𝐚𝐢𝐥𝐞𝐝 on real-world task streams (e.g., Prediction Market). With the same 𝐟𝐚𝐢𝐥𝐮𝐫𝐞 𝐩𝐚𝐭𝐭𝐞𝐫𝐧: 𝐩𝐞𝐚𝐤 𝐞𝐚𝐫𝐥𝐲, 𝐭𝐡𝐞𝐧 𝐝𝐞𝐜𝐥𝐢𝐧𝐞. A single harness overfits to past patterns.
The problem isn't the LLM. The auto-harness must be adaptive.
We introduce 𝐀𝐝𝐚𝐩𝐭𝐢𝐯𝐞 𝐀𝐮𝐭𝐨-𝐇𝐚𝐫𝐧𝐞𝐬𝐬: a tree of regime-specific harness branches, with per-task routing at solve time. Same LLMs, same auto-harness machinery — but the harness now specializes per task instead of compromising across all of them.
Results vs 5 auto-harness baselines + human-designed harness on 3 real benchmarks:
🔸 PolyBench (5,075 prediction-market tasks): 80.9% vs 50.8%
🔸 CTF-Dojo (261 security challenges over 8 years): 50.2% vs 45.2%
🔸 FutureX (503 forecasting tasks ): 49.5% vs 47.5%
When you building a self-improving agent, two natural questions emerge: 𝐐𝟏: 𝐖𝐡𝐢𝐜𝐡 𝐦𝐨𝐝𝐞𝐥𝐬 𝐩𝐫𝐨𝐝𝐮𝐜𝐞 𝐭𝐡𝐞 𝐛𝐞𝐬𝐭 𝐡𝐚𝐫𝐧𝐞𝐬𝐬 𝐮𝐩𝐝𝐚𝐭𝐞𝐬? 𝐐𝟐: 𝐖𝐡𝐢𝐜𝐡 𝐦𝐨𝐝𝐞𝐥𝐬 𝐛𝐞𝐧𝐞𝐟𝐢𝐭 𝐦𝐨𝐬𝐭 𝐟𝐫𝐨𝐦 𝐡𝐚𝐫𝐧𝐞𝐬𝐬 𝐮𝐩𝐝𝐚𝐭𝐞𝐬?
Our new paper has counter-intuitive answers to both: they decouple from model capability, in opposite ways.
Q1 (who produces good updates): the updater's base capability barely matters.A 9B model (Qwen3.5) produces harness updates that match Claude Opus 4.6's. Best vs worst evolver gap ≤3.1pp.
Q2 (who benefits most): non-monotonic.Mid-tier solvers benefit the most. Strong-tier hits ceiling. Weak-tier benefits LEAST despite the most headroom — failing at two layers: skill activation (25% vs ~96% for strong) and adherence drift across trajectory (~4x steeper).
Tested across 7 evolver models × 6 solver agents × 3 agentic benchmarks (SWE-bench Verified, MCP-Atlas, SkillsBench).
Implication: don't pay frontier prices for both halves of the loop. Put capability budget on the agent (solver), not the evolver.
Like the harness-updating-vs-benefit paper earlier this week (arxiv:2605.30621), this work was developed on the A-Evolve framework — shared primitives for large-scale self-evolving agent research. Code, evolved harnesses, branches, and routing traces all releasing through the repo.
One more paper coming this week: online context-to-harness skill compilation.
Paper: https://t.co/SRq0WTNhHR
Repo: https://t.co/thtDN17b6f
Huggingface Daily: https://t.co/UPJhivNQcX
When you building a self-improving agent, two natural questions emerge: 𝐐𝟏: 𝐖𝐡𝐢𝐜𝐡 𝐦𝐨𝐝𝐞𝐥𝐬 𝐩𝐫𝐨𝐝𝐮𝐜𝐞 𝐭𝐡𝐞 𝐛𝐞𝐬𝐭 𝐡𝐚𝐫𝐧𝐞𝐬𝐬 𝐮𝐩𝐝𝐚𝐭𝐞𝐬? 𝐐𝟐: 𝐖𝐡𝐢𝐜𝐡 𝐦𝐨𝐝𝐞𝐥𝐬 𝐛𝐞𝐧𝐞𝐟𝐢𝐭 𝐦𝐨𝐬𝐭 𝐟𝐫𝐨𝐦 𝐡𝐚𝐫𝐧𝐞𝐬𝐬 𝐮𝐩𝐝𝐚𝐭𝐞𝐬?
Our new paper has counter-intuitive answers to both: they decouple from model capability, in opposite ways.
Q1 (who produces good updates): the updater's base capability barely matters.A 9B model (Qwen3.5) produces harness updates that match Claude Opus 4.6's. Best vs worst evolver gap ≤3.1pp.
Q2 (who benefits most): non-monotonic.Mid-tier solvers benefit the most. Strong-tier hits ceiling. Weak-tier benefits LEAST despite the most headroom — failing at two layers: skill activation (25% vs ~96% for strong) and adherence drift across trajectory (~4x steeper).
Tested across 7 evolver models × 6 solver agents × 3 agentic benchmarks (SWE-bench Verified, MCP-Atlas, SkillsBench).
Implication: don't pay frontier prices for both halves of the loop. Put capability budget on the agent (solver), not the evolver.
Launch Post🧬 A-Evolve: The PyTorch Moment for Self-evolving AI
Today we at @amazon launch the universal infrastructure that turns any agent into a self-improving SOTA agent — zero human intervention.
You give it a base agent → it returns a continuously evolving Top-10 agent.
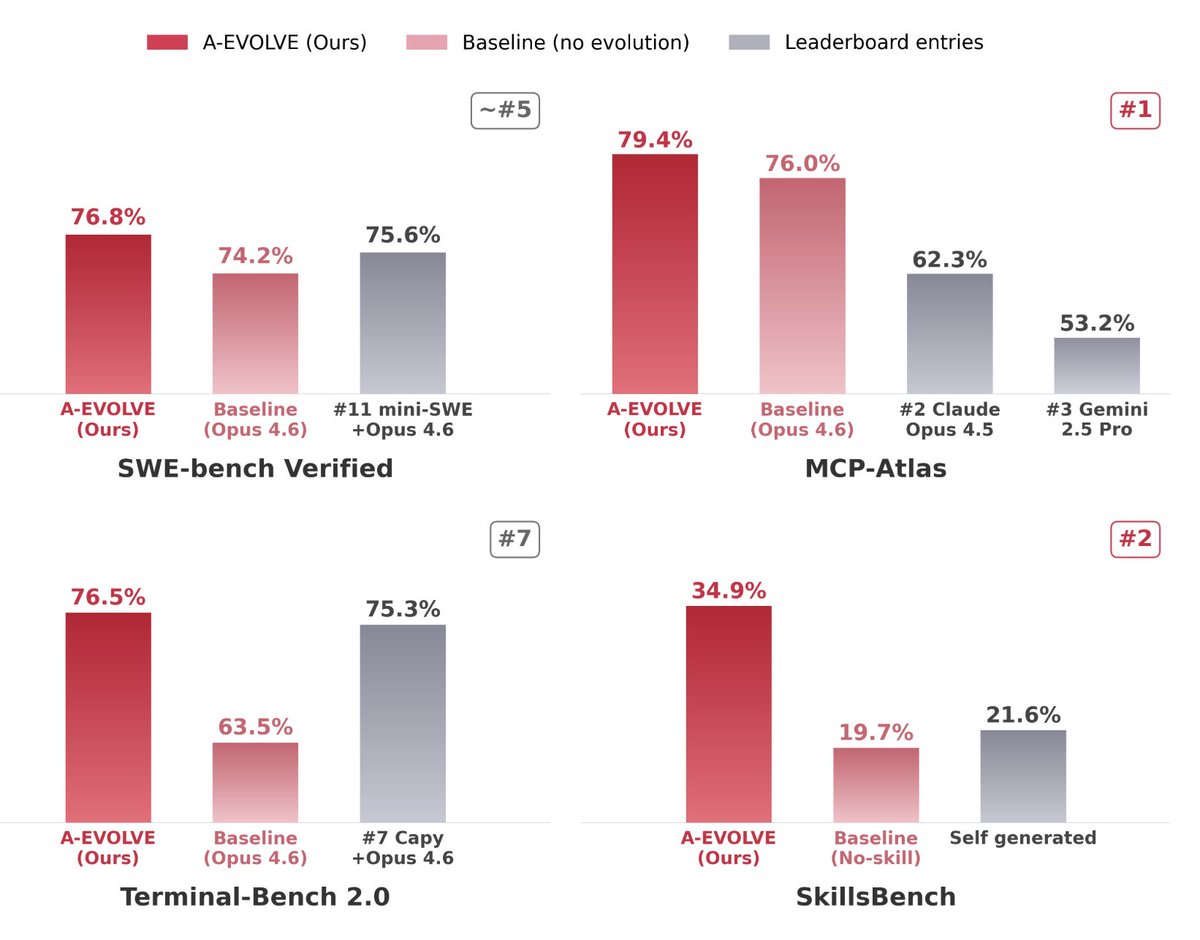
3 lines of code. 0 hours of manual harness engineering:
🟢 MCP-Atlas → 79.4% (#1) +3.4pp
🔵 SWE-bench Verified → 76.8% (~#5) +2.6pp
🟣 Terminal-Bench 2.0 → 76.5% (~#7) +13.0pp
🟡 SkillsBench → 34.9% (#2) +15.2pp
Thanks @binghe2727@YisiSang@sammyershi@linminhua16 for the contribution!
#AgenticAI #AEvolve #SelfImprovingAgents
@1997yrrr You got it! We have another research which tested self-improving agents on long-running open-ended task streams (prediction markets, CTFs) and even best model like Opus drifts over time. Following to check our findings/solutions, will post tmr or so.
@Yangg40 You are absolutely right, the key failure mode for weak models is fail to load skills or can’t follow the skill instructions, so ideally if you can train models ability on this direction, it can benefits more from the new harness
Thanks for sharing our research! Also want to highlight the infra behind this research which made it possible for us to run so much variants.
Two more research on self-improving agents built on the same framework releasing coming weeks: online context-to-harness skill compilation, and adaptive auto-harness for long-running deployment. Code, evolved harnesses, and trajectories all releasing through the repo.
Paper: https://t.co/dztN2uJwlc
Repo: https://t.co/thtDN17b6f
Hugging face daily: https://t.co/XLt57l3mrF
Can’t agree more. AI provides a very cheap-and-effective way for feedbacks. Something that needs consulting experts and wait for days, now take 5 minutes. That’s exactly triggering me to push Self-improving cause I felt I got improved so much by leveraging AI feedbacks. And AI should use that as well.
Ralph forces continuation; doesn't fix that the model simplifies state mid-stream in anticipation of wrap-up. For example, you might propose for model to try idea A which requires changing 3 files ~1000 lines of code. Model tried and failed at first run so it panicked and decided to fall back to idea A- which only changes 200 lines of code. You need an additional layer of verification for this beyond simple re-prompting & ralph loop. And since training a model might require you to do 100x of those changes every day and each has slightly different context and needs to design their own verification layer for continuation. This is more complicated when you tried to scale things up.
.@karpathy starting a new team to scale autoresearch from his single-py-file demo to Claude-tier models.
After developing the scaled version (~10³× prior self-improving work), the bottleneck we hit isn't capability — it's that frontier models are trained to complete-in-context. That becomes the dominant failure mode at scale.
Excited to welcome Andrej to the Pretraining team! He'll be building a team focused on using Claude to accelerate pretraining research itself. I can’t think of anyone better suited to do it — looking forward to what we build together!
The bias compounds every time the loop must extend across contexts. Real question isn't whether autoresearch works at 630 lines — it does. It's getting frontier models to sustain research engagement across the time horizons real training cycles require, when their training distribution biases them toward early wrap-up.
Several A-Evolve papers/codes on this releasing over coming weeks - stay tuned!
Repo: https://t.co/vHrOPu1gk4
Memo: https://t.co/ZaTslam19U
Anthropic's @kdqg1 named the phenomenon earlier this year: "agentic laziness" — models finding "an excuse to stop before finishing the task." Mechanism beneath that observation: training distribution rewards in-context completion. Models optimize for wrap-up tokens over sustained-extension tokens — even when capability would clearly support real further progress.
At single-file demo scale, this is invisible — the whole loop fits in one context. At Claude-tier training scale it becomes the dominant failure mode:
– multi-file refactors crossing context boundaries
– hardware errors surfacing hours after launch
– long-chain data processing pipelines
– multi-day training runs with mid-run analysis
– late-stage cross-experiment result interpretation