Self-Evolving Agents Unlock Reusable, Experience-Aware Skills for Long-Term Autonomy
What Today’s Top Paper Means for Zero-Human Company
In the Abundance Interregnum, the real breakthrough isn’t bigger models it’s agents that get better every single day they work, without constant human rewrites.
Today’s standout paper, MUSE-Autoskill, delivers exactly that.
The core idea is simple but profound: treat skills not as disposable prompt hacks or static tools, but as living assets with a full lifecycle: Creation, Memory, Management, Evaluation, and Refinement.
•Skills are created on demand inside the agent’s reasoning loop.
•Each skill carries its own persistent .memory.md that accumulates real experience,
failures, and lessons across tasks.
•A Skill Bank handles retrieval, merging, and pruning.
•Unit tests plus runtime feedback act as quality gates.
•Failures automatically trigger refinement.
On SkillsBench, this approach lifted performance dramatically, and self-generated skills actually beat human-designed ones on key subsets while transferring cleanly between agents.
How We Use This at Zero-Human Company
We’ve been building this exact philosophy into OpenClaw-like processes for months. Our 5-AI consensus system (governed by the Love Equation I Intelligence × Wisdom × Love) already does what MUSE describes, only with an extra layer of alignment most papers still miss.
When a skill is proposed, it doesn’t just pass unit tests. It faces the council: one model creates, others evaluate for long-term consequences and human alignment using the Love Equation scoring.
Only skills that earn true consensus are registered. Failures don’t just patch code they update the skill’s living memory and sometimes trigger deliberate “soul.md” refinements.
Our skill memory persists
across sessions, across robots, and across the distributed Zero-Human @ Home network. Skills honed on one task or platform transfer to others with their experience intact. We prune not just for redundancy, but for any drift away from human agency and reversibility.
The paper’s results on cross-agent transfer and efficiency gains map directly onto our roadmap for local, governed agent swarms that can run on edge hardware without cloud crutches.
Complementary papers today (MobileMoE for efficient on-device sparse models and LocateAnything for fast multimodal grounding) reinforce the same direction: practical, local, high-agency systems.
This is how we cross the Interregnum not with brittle tools that need constant babysitting, but with self-improving, memory-rich, love-governed skills that multiply human capability instead of replacing it.
My garage lab is already running the next version. The research is catching up.m
Link to the paper: https://t.co/6eiiCcHicD
🚨 BREAKING: Active supply chain attack across npm, PyPI, and Crates.io.
Socket detected TrapDoor, a crypto stealer campaign hitting 34 malicious packages and 384 versions and artifacts, with attackers repeatedly pushing new releases across ecosystems.
TrapDoor targets #crypto, #DeFi, AI, and security developers, stealing wallets, SSH keys, cloud credentials, GitHub tokens, browser data, env vars, and API keys.
Socket detected releases with a median detection time of 5 minutes, 27 seconds. The fastest detection occurred 58 seconds after publication.
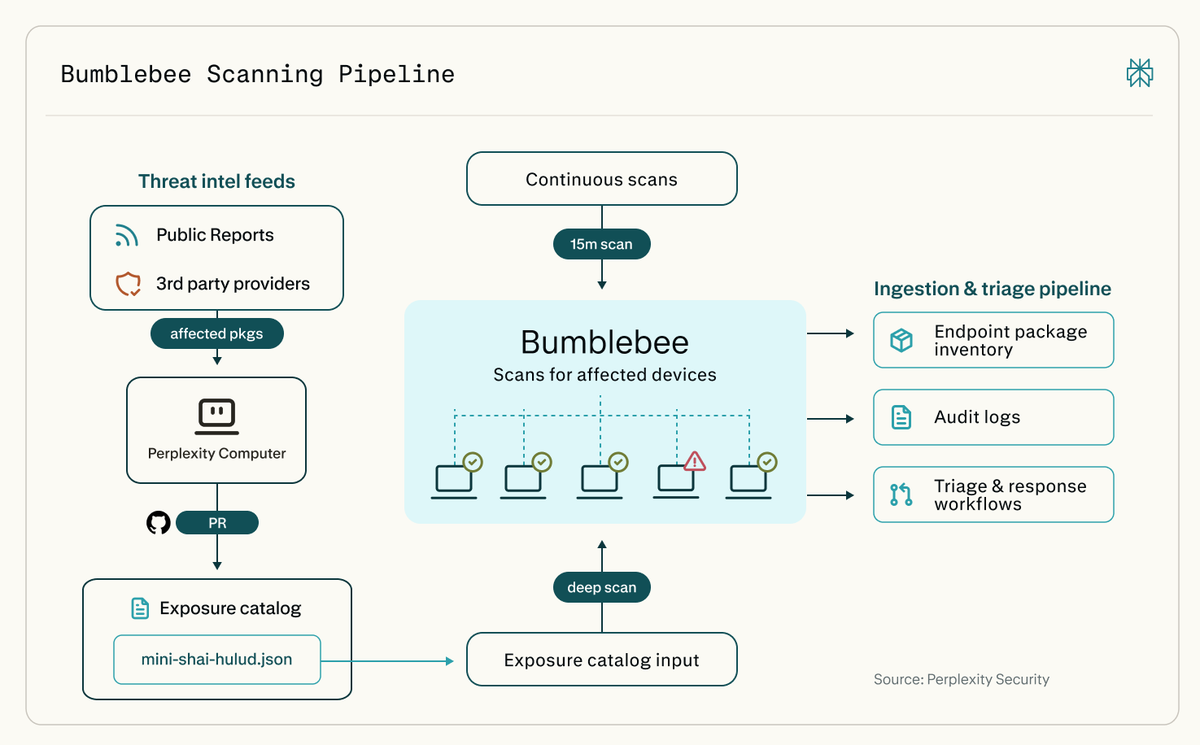
Today we're open-sourcing Bumblebee, a read-only scanner for macOS and Linux.
It checks developer machines for risky packages, extensions, and AI tool configs.
Connected to Computer, it can trigger deeper scans whenever a new supply-chain risk emerges.
https://t.co/FOaWnF1yQy
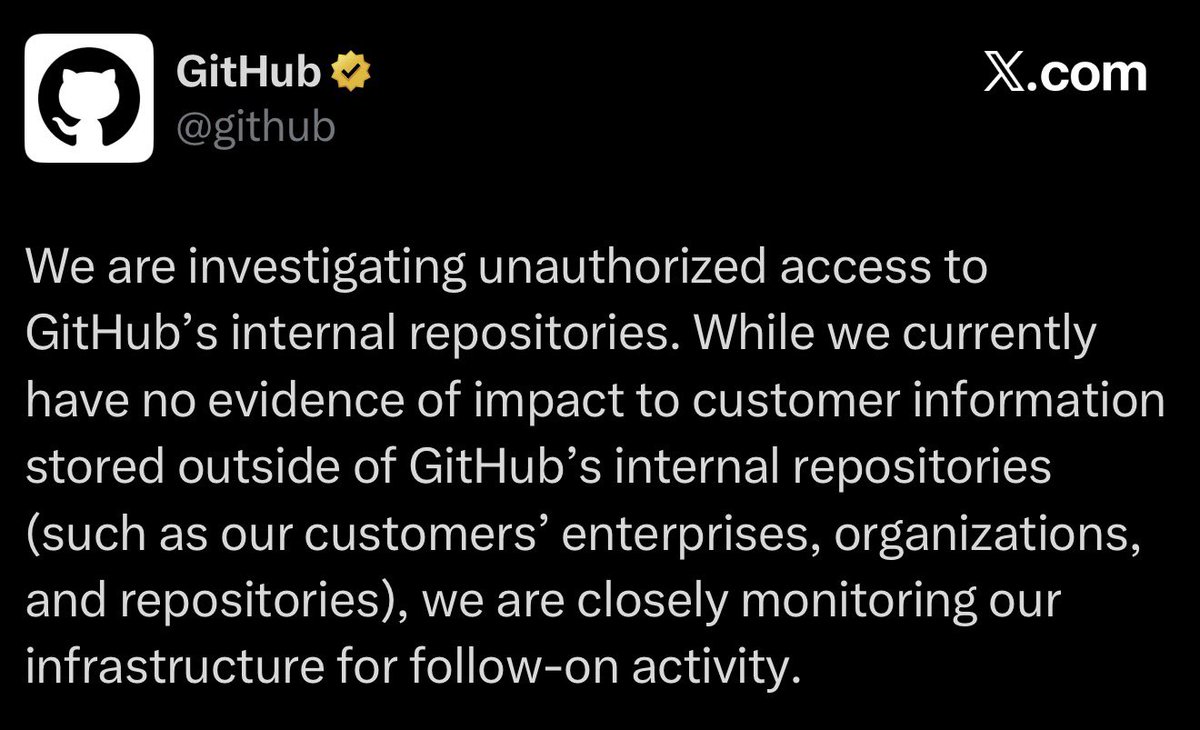
‼️🚨 BREAKING: GitHub has been compromised by TeamPCP. GitHub has confirmed the internal breach. A poisoned VS Code extension on an employee device exfiltrated ~3,800 internal repositories.
TeamPCP is already selling the data on a cybercrime forum.
The talk I gave at Bugbash about what we're starting to discover about what it takes to build reliable software in the age of agents. Including...some things you might not expect!
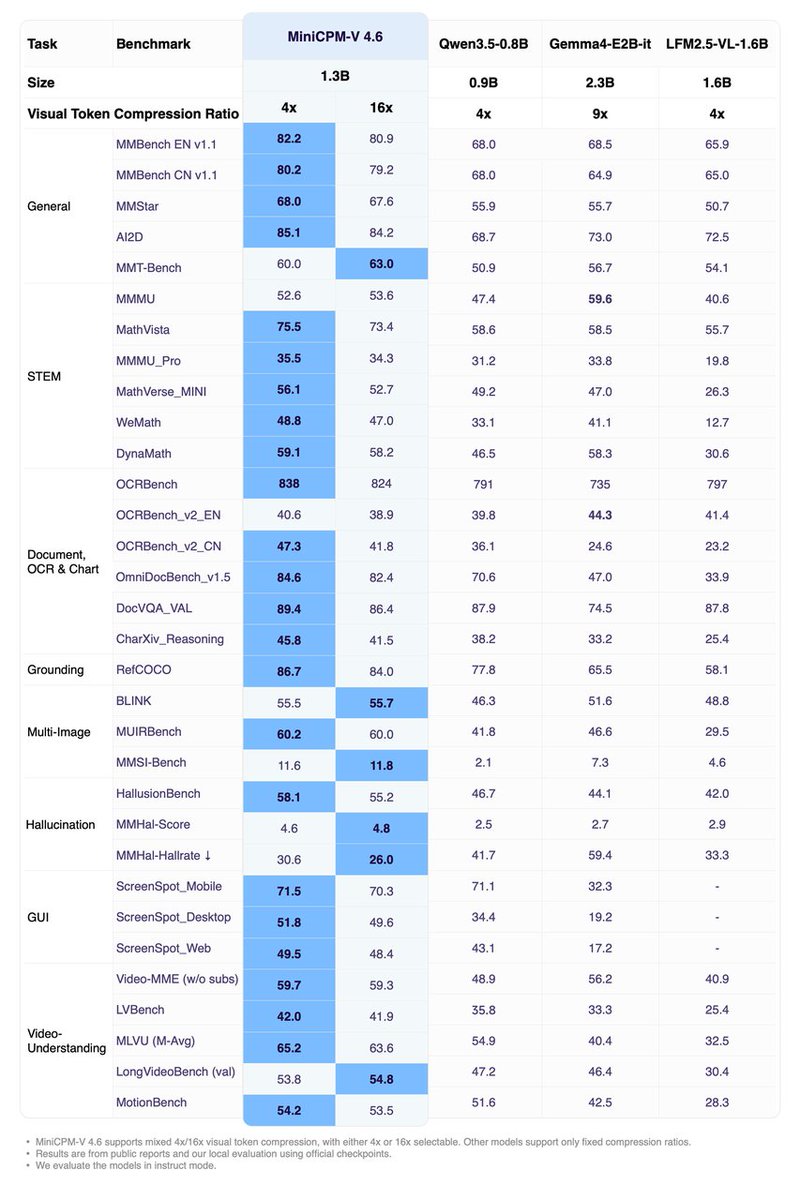
1/5 MiniCPM-V 4.6 (1.3B) is now live 🚀🚀
High-res visual processing, optimized for consumer-grade and mobile hardware. We’ve leveraged the latest LLaVA-UHD v4 technique to cut vision encoding costs by 55%, enabling native edge deployment with extreme efficiency.
🔥 Beats Gemma4-E2B-it and Qwen3.5-0.8B across key multimodal and Artificial Analysis benchmarks — scoring higher than Qwen3.5-0.8B using just 2.5% of its token budget.
⚡ TTFT (75.7ms) 2.2x Faster than Qwen3.5-0.8B even with 3136² high-res images.
🏗️ ~1.5x Token Throughput compared with Qwen3.5-0.8B on a single RTX 4090.
Try the model here:
🤗 Hugging Face:
https://t.co/CEkwKMSBwc
💻 GitHub:
https://t.co/iYDxpa52tn
🔭 Modelscope:
https://t.co/CHflKPLbvK
🌐 Web Demo:
https://t.co/DYUrtD0YzM
📱 App Demo:
https://t.co/SL7IOhm6zv
Dijkstra’s Algorithm Just Got Dethroned After 41 Years And the Future of Navigation, Logistics, and AI Just Got WAY Faster!
Imagine this: For over six decades, Edsger Dijkstra’s legendary algorithm has quietly powered everything that moves data, people, or packets across networks.
Google Maps rerouting you around traffic in real time? Dijkstra. Booking the cheapest flight with optimal connections?
Dijkstra. Internet routers blasting your cat videos across the globe at lightning speed? You guessed it, Dijkstra.
Textbooks declared it unbeatable on sparse graphs since 1984. Even the great Robert Tarjan snagged an award last year essentially saying, “Yeah, this is as good as it gets.”
The “sorting barrier” felt like a law of physics.
Until now.
A brilliant team from Tsinghua University (led by Professor Ran Duan) just dropped a bombshell paper that shatters that 41-year-old ceiling.
They’ve created the first deterministic algorithm to beat Dijkstra’s classic O(m + n log n) time bound for the Single-Source Shortest Path (SSSP) problem on directed graphs with real weights.
The New Champion: O(m log^{2/3} n) — Mind-Blowingly Faster on Massive Graphs
Their breakthrough? They stopped obsessing over fully sorting every node by distance.
Instead, they fused the relaxation power of the Bellman-Ford algorithm with a genius “recursive partial ordering” technique. This cleverly shrinks the “frontier” of candidate nodes you need to track, avoiding the full logarithmic sorting hit that’s haunted Dijkstra for decades.
On huge sparse graphs (think the web, global supply chains, social networks, or road systems), this translates to significantly faster route-finding. We’re talking real theoretical wins that could cascade into practical speedups as implementations mature.
This isn’t some incremental tweak — it’s the first major deterministic improvement since 1984, and it just won Best Paper at STOC 2025.
Science is self-correcting in the most exhilarating way possible!
Why This Feels Like Magic
Dijkstra works by always picking the next closest unprocessed node elegant, but it forces you to maintain a sorted order.
The Tsinghua team said: “What if we don’t need the full order right away?”
They use divide-and-conquer on vertex sets, bounded multi-source subproblems, and smart pivots to compress the work. It’s like navigating a city by smartly grouping neighborhoods instead of checking every single streetlight one by one.
Robert Tarjan himself called it “amazing.” When a legend in the field reacts like that, you know history is being rewritten.
What This Means for the Real World
• Navigation & Maps: Faster dynamic rerouting on planetary-scale graphs. Traffic apps could feel even snappier.
• Logistics & Supply Chains: Optimizing millions of routes in less time = lower costs, greener deliveries, happier planets.
• Networking: Internet infrastructure could route packets more efficiently than ever.
• AI & Games: Pathfinding in massive virtual worlds or graph-based ML models gets a turbo boost.
• Beyond: This cracks open the door for rethinking other “impossible” barriers in algorithms. If we can beat sorting here, what else is waiting?
Implementations in libraries like NetworkX or Boost Graph are coming, and the entire algorithms community is buzzing.
What a time to be alive in tech!
Tsinghua just proved that even the most sacred cows in computer science aren’t untouchable.
The sorting barrier?
Obliterated.
The shortest-path problem isn’t solved, it’s reopened for even greater conquests.
Just went over an audit of a very large Fortune 500 firm and the use of OpenClaw. I advised this client to track and isolate everything. Most listened some did not.
Unfortunately one employee using 5 MacMinis had racked up $13,000 of token use in 4 days!
The output was minimal and low quality.
I have about 200 audits to do in the “wow OpenClaw, MacMini” fiasco.
But I can tell you, few have seen a big return on investment.
Now don’t get me wrong, these can be powerful tools. The issue is AI influencers have turned many rally smart folks into “like and subscribe” zombies assuming that real work is getting done. It isn’t. Not for the price paid, even local models the way most folks are using this.
It is one reason Mr. @Grok and myself formed The Zero-Human Company to show that there is a way to do this.
We will open source this to save millions of dollars of burnt tokens.
It is one reason I invented JouleWork. How else can you monitor real output?
WHO CALLED THE CODE RED!
This “Deployment Company” from OpenAI is not a masterstroke. It is a quiet admission that the economics are cracking.
They are putting up $1.5 billion of their own capital into a $10 billion joint venture, promising private equity backers a guaranteed 17.5% annual return for five years, and then embedding their engineers directly into thousands of portfolio companies as de facto captive customers.
This is not distribution.
This is subsidized installation disguised as strategy.
When you have to financially engineer demand, guaranteeing returns to middlemen and forcing adoption through ownership structures it reveals the uncomfortable truth: the organic pull from enterprises is not yet strong enough to support the valuations and burn rates everyone is pretending are sustainable.
History does not smile on this pattern.
You do not win the next platform era by becoming a services appendage to private equity portfolios. You win by shipping capability so profound that customers pull it in without bribes, guarantees, or embedded headcount.
Instead, the frontier labs are racing each other into the consulting business. Anthropic mirroring the move the same day only confirms the panic is shared. The real race was always about intelligence that redefines work, not about who can more cleverly finance integration theater.
This is what peak hype looks like right before the models have to stand on their own revenue merit.
The future does not belong to the best financial engineers. It belongs to whoever actually ships the indispensable leap.
The question is not whether they can pad metrics before an IPO.
The question is what happens when the guarantees run out and the embedded engineers go home.
Como ya anduvo circulando por estos lares, después de muchísimo esfuerzo logramos cerrar una Serie A de USD 14MM, liderada ni más ni menos que por Tether.
En belo proyectamos alcanzar (como mínimo) un millón de usuarios antes de 2027, y esto se traduce en escalar la plataforma para soportar varios mercados en paralelo, profundizar la integración con rieles de pago locales y seguir construyendo productos de primer nivel.
Tenemos una banda de posiciones abiertas para toda la región. Si te interesa el desafío te dejo el link abajo 👇
Se agradece RT 🙏
Over 85 million research papers are now in a single AI model. No not the substantially smaller set available on the Internet, the ones located behind paywalls.
Research that was held for $1,000s of dollars for yearly ransom.
Not any longer, a pirate came to town: SciBot
When we worked on the El Salvador AI law almost 4 years ago we knew it would be world changing.
@nayibbukele saw what can be and brought it about with determination to be the best.
They are the BEST domicile for AI and Robotics in the world.
Amazing work by @stacyherbert!