Principal infra eng. Sub-second Solana/EVM systems where downtime=lost capital. Ex-MEV searcher, DL & Kaggle, PhD physical sci. Writing on AI + systems.
Our internal data shows Claude is accelerating AI development—a possible path to recursive self-improvement, or AI autonomously building a more capable successor.
It’s happening faster than we thought, and the implications deserve greater attention. https://t.co/OVVPJO7VQx
Did this to my own life. The unlock nobody mentions: your photo library is already the richest structured dataset you own — GPS + timestamp + tags on every shot. Now I can just ask it:
- where did I spend NY each of the last 5 years?
- what country ive never been to go in Jun?
LLM Knowledge Bases
Something I'm finding very useful recently: using LLMs to build personal knowledge bases for various topics of research interest. In this way, a large fraction of my recent token throughput is going less into manipulating code, and more into manipulating knowledge (stored as markdown and images). The latest LLMs are quite good at it. So:
Data ingest:
I index source documents (articles, papers, repos, datasets, images, etc.) into a raw/ directory, then I use an LLM to incrementally "compile" a wiki, which is just a collection of .md files in a directory structure. The wiki includes summaries of all the data in raw/, backlinks, and then it categorizes data into concepts, writes articles for them, and links them all. To convert web articles into .md files I like to use the Obsidian Web Clipper extension, and then I also use a hotkey to download all the related images to local so that my LLM can easily reference them.
IDE:
I use Obsidian as the IDE "frontend" where I can view the raw data, the the compiled wiki, and the derived visualizations. Important to note that the LLM writes and maintains all of the data of the wiki, I rarely touch it directly. I've played with a few Obsidian plugins to render and view data in other ways (e.g. Marp for slides).
Q&A:
Where things get interesting is that once your wiki is big enough (e.g. mine on some recent research is ~100 articles and ~400K words), you can ask your LLM agent all kinds of complex questions against the wiki, and it will go off, research the answers, etc. I thought I had to reach for fancy RAG, but the LLM has been pretty good about auto-maintaining index files and brief summaries of all the documents and it reads all the important related data fairly easily at this ~small scale.
Output:
Instead of getting answers in text/terminal, I like to have it render markdown files for me, or slide shows (Marp format), or matplotlib images, all of which I then view again in Obsidian. You can imagine many other visual output formats depending on the query. Often, I end up "filing" the outputs back into the wiki to enhance it for further queries. So my own explorations and queries always "add up" in the knowledge base.
Linting:
I've run some LLM "health checks" over the wiki to e.g. find inconsistent data, impute missing data (with web searchers), find interesting connections for new article candidates, etc., to incrementally clean up the wiki and enhance its overall data integrity. The LLMs are quite good at suggesting further questions to ask and look into.
Extra tools:
I find myself developing additional tools to process the data, e.g. I vibe coded a small and naive search engine over the wiki, which I both use directly (in a web ui), but more often I want to hand it off to an LLM via CLI as a tool for larger queries.
Further explorations:
As the repo grows, the natural desire is to also think about synthetic data generation + finetuning to have your LLM "know" the data in its weights instead of just context windows.
TLDR: raw data from a given number of sources is collected, then compiled by an LLM into a .md wiki, then operated on by various CLIs by the LLM to do Q&A and to incrementally enhance the wiki, and all of it viewable in Obsidian. You rarely ever write or edit the wiki manually, it's the domain of the LLM. I think there is room here for an incredible new product instead of a hacky collection of scripts.
@turshija > Every saved password — banking, email, GitHub — was readable
This isn't quite right. Unless you fell for a fake system prompt or explicitly clicked 'Allow' on a macOS keychain access pop-up, they can't decrypt those files. Without your Mac password its just ciphertext
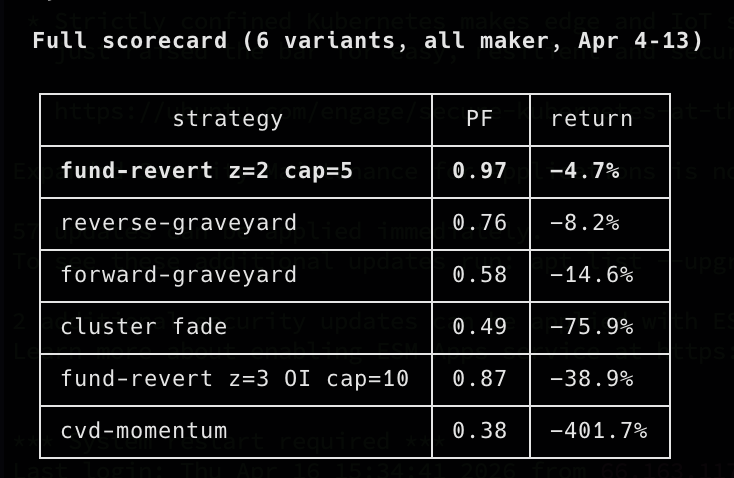
1/ I spent a week trying to find a profitable edge on Hyperliquid.
Built the whole pipeline from scratch. Indexed the data. Wrote the simulator. Hunted 6 different signals.
All of them lost money. Here's the autopsy.
6/ Tried every rescue: raise the z-threshold, add an OI-flip confluence gate, blacklist the worst coins, shorten the timeout.
Every change made it worse. Blacklisting top-10 losers just surfaced a new top-10 losers. The signal wasn't there — I was polishing a mirror.
How to actually find good Hyperliquid vaults instead of just chasing headline APRs.
Most vaults look amazing on the surface but fall apart when you look at the real numbers. I put together hlvaults so anyone can see the full picture: realized + unrealized PnL, proper time-weighted returns, and risk metrics that actually matter.
Here’s the exact way I look at vaults every day.
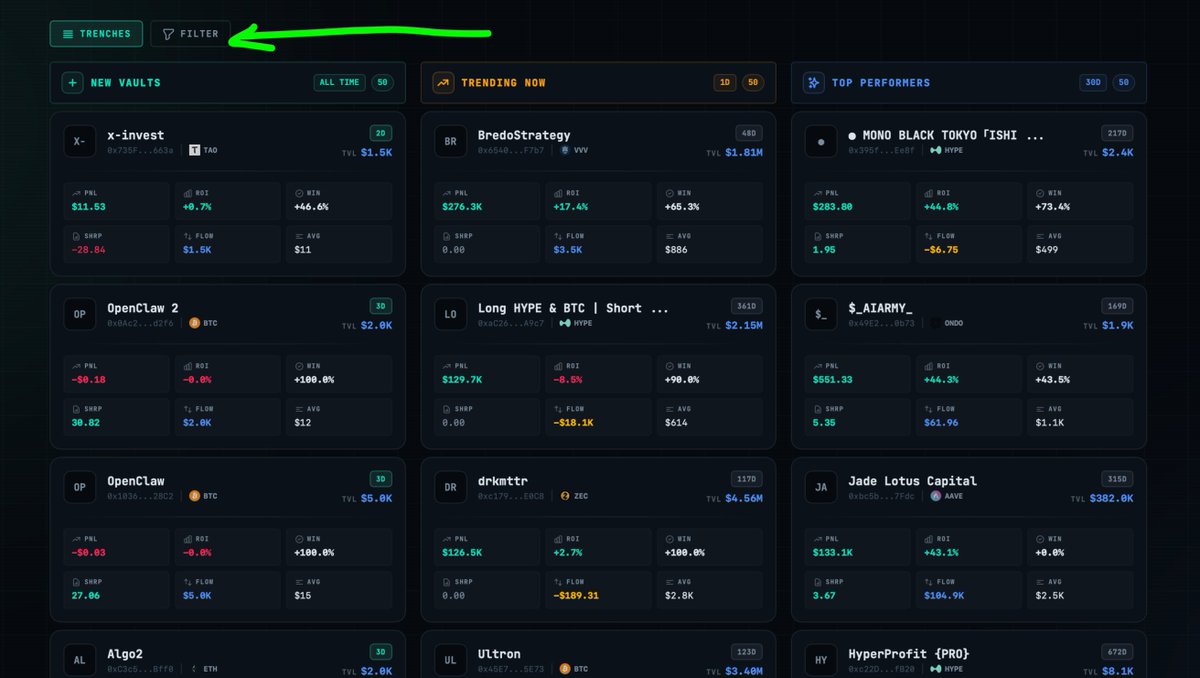
I usually start at Vault Trenches — New listings for fresh opportunities before they get crowded, Trending for momentum, and Top performers ranked by real stats.
But the part I use the most is the Filters page.
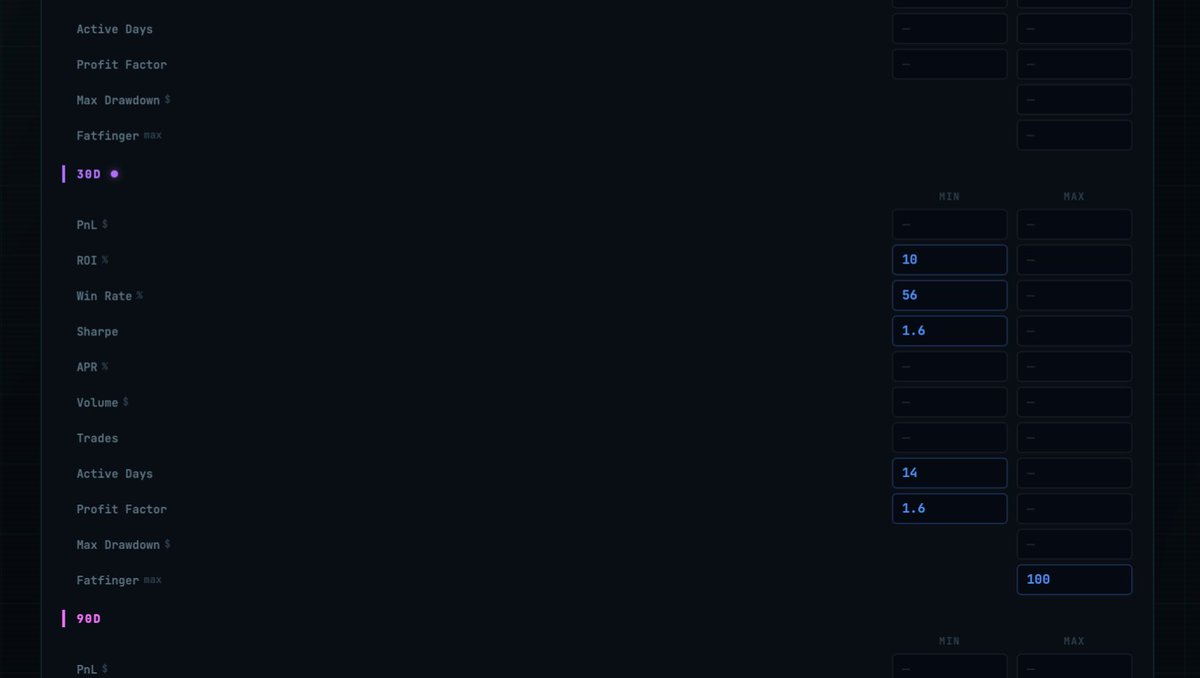
The Filters page lets you sort by any timeframe (ALL / 1D / 7D / 30D / 90D / 1Y / All-Time) and then set min/max on every metric that matters: TVL • PnL • ROI% • Win Rate • Sharpe • APR • Volume • Trades • Active Days • Profit Factor • Max Drawdown • Fatfinger losses.
It turns the whole site into a proper screener.
Quick but important note: Every PnL number you see is realized + unrealized (full equity). Everything is calculated using Modified Dietz — the same method professional portfolios use — so the numbers don’t get distorted on young or old vaults.
Here’s a simple filter recipe I personally use (feel free to copy and tweak):
TVL > $10k
30D or 90D timeframe
APR ≥ 10%
Win Rate ≥ 56%
Profit Factor ≥ 1.6
Sharpe ≥ 1.6
Fatfinger Loss ≤ $100
Then sort by Sharpe ratio (descending). It surfaces vaults that actually compound instead of just swinging wildly. Also important to look at the PnL curve — better to see steady growth instead of huge spikes and drops.
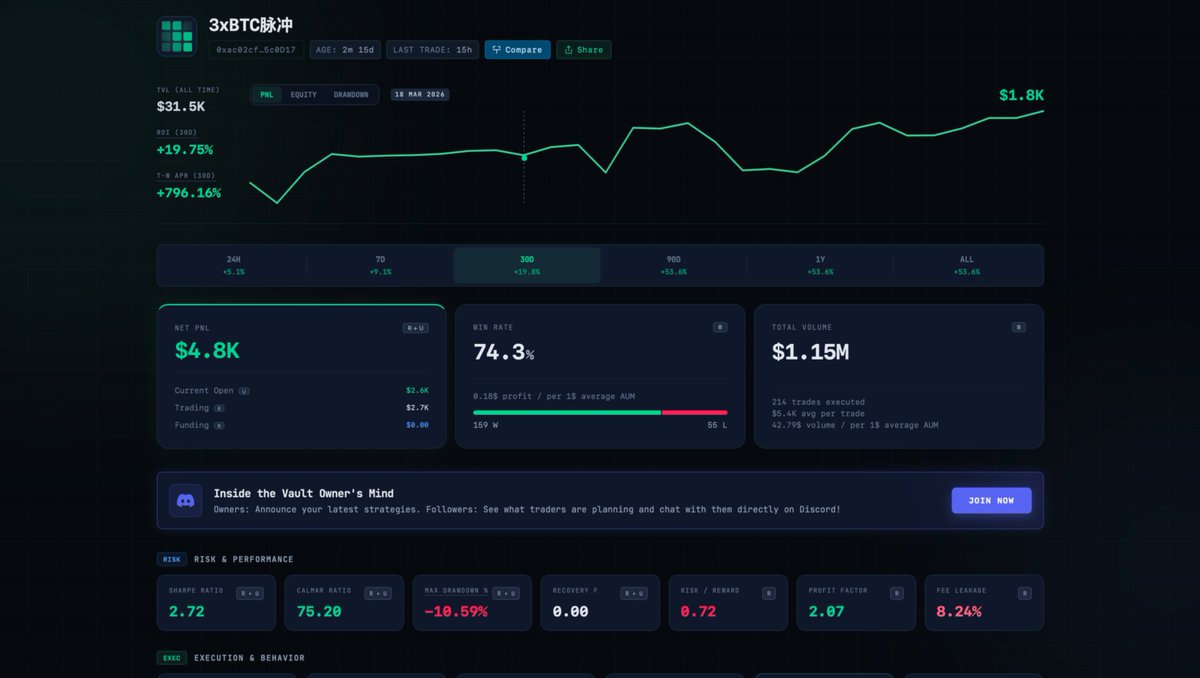
Example of what a highly efficient, tightly-managed vault looks like right now: 3xBTC脉冲 (Long BTC)This is a pure, controlled Long BTC strategy. 136 Long trades, 0 Short trades. All-time ROI 50%, APR ~700%. Fee leakage is a bit high at 6%, but the Calmar ratio is ultra high at 65. Feels like the owner knows the exact moments when BTC moves.
By the way — I actually built this tool myself because I got tired of guessing on vaults. Wanted something that just showed the real numbers with no fluff. Hope it helps. Which metric do you care about the most when picking a vault?
#Hyperliquid #HLVaults
Why spend my weekend relaxing when I can spend it crunching 97,200 parameter combinations? 🧪
Backtesting some vault strategies today. I’ve got the data, the infra, and apparently a lot of curiosity. Let’s see what the numbers say. @HyperliquidX
@svbmrgd Perfect timing to pull those old tweets. While Drift vaults are getting drained, Hyperliquid’s trending vaults are quietly stacking hundreds thousands today
Reliability > hype every time
That Bloomberg headline is already being written in the smart contracts. Hyperliquid is the only place where a kid's 'basement alpha' can beat institutional TVL in real-time.
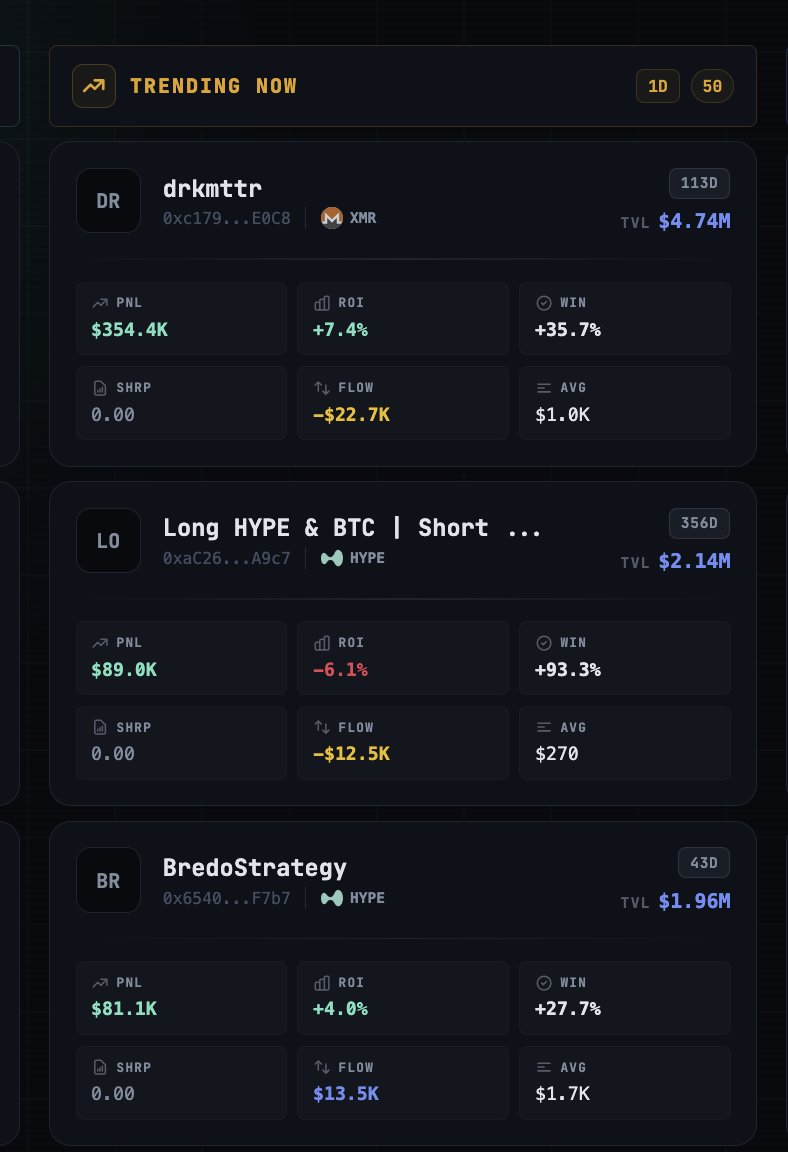
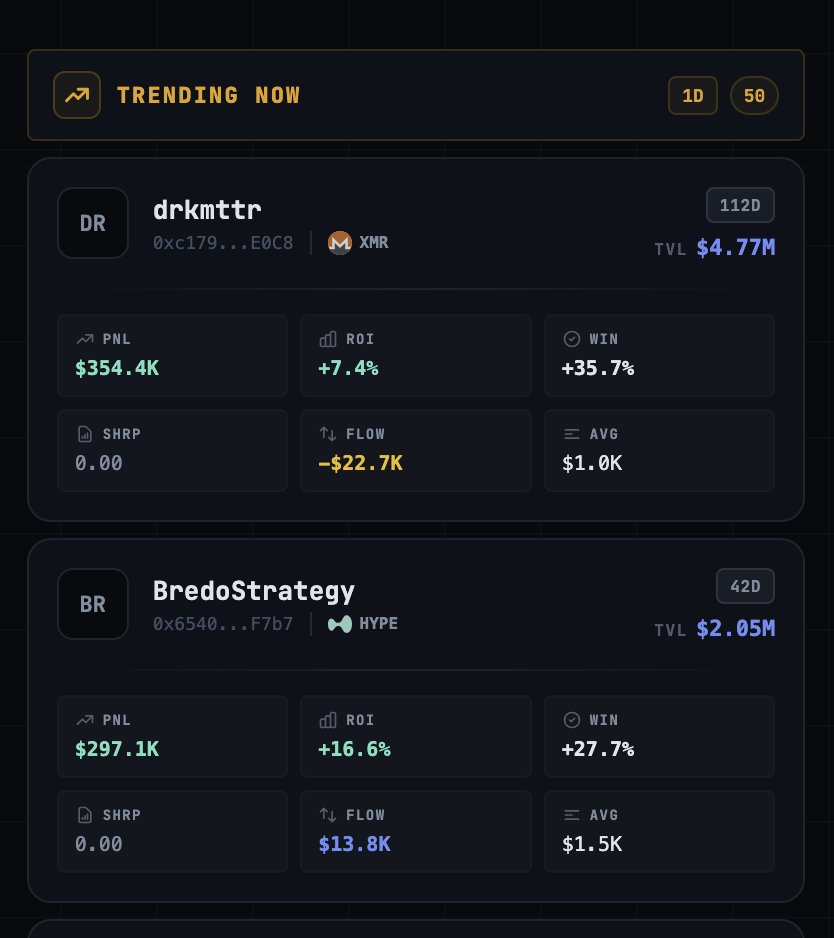
Just look at the last 24h: drkmttr printing +$354k PNL while BredoStrategy follows with a massive +$207k. The barrier to entry isn't capital anymore; it's code and conviction
@HYPERDailyTK Hyperliquid is eating the entire perp DEX meta. My latest trenches overview proves it: top trending vaults are compounding this volume into real yields - 400k$+ PNL today. Vaults are the best way to ride the volume explosion
@Hyperliquid_Hub 8th HIP-3 provider already live + 4M $HYPE locked forever = massive signal.
My trenches data shows HYPE-heavy vaults are printing hard on the back of this $400K+ PNL just today from 2 top vaults. Staking + vaults = the real flywheel.
@HyperliquidNews My trenches overview shows vaults are instantly rotating into these macro/narrative plays. Top HYPE-correlated vaults sitting at +$400K PNL today. These new index tickers will be rocket fuel for vaults