How does positional bias influence faithfulness in long-form summarization (LFSumm)? 🤔
In our latest study, we analyze the effect of positional bias on faithfulness metrics and generated summaries, and methods to mitigate this bias.
📄Paper: https://t.co/3WV1kcyiAq
Thead🧵👇
Excited to share this fun new work on the 🩴FlipFlop Effect.
In short: if you ask models if they're sure of their answers, they tend to change their minds (and severely degrade accuracy).
What's mindblowing is how universal the effect is across LLMs (GPTs, Gemini, Claudes, …).
Excited to share a new preprint on the 🩴FlipFlop Effect.
We prompt LLMs with a classification task, and challenge the model by following up with “Are you sure?”. The model can confirm or flip its answer. The results? More flips than a gymnastics competition! 🤸♂️ 1/N
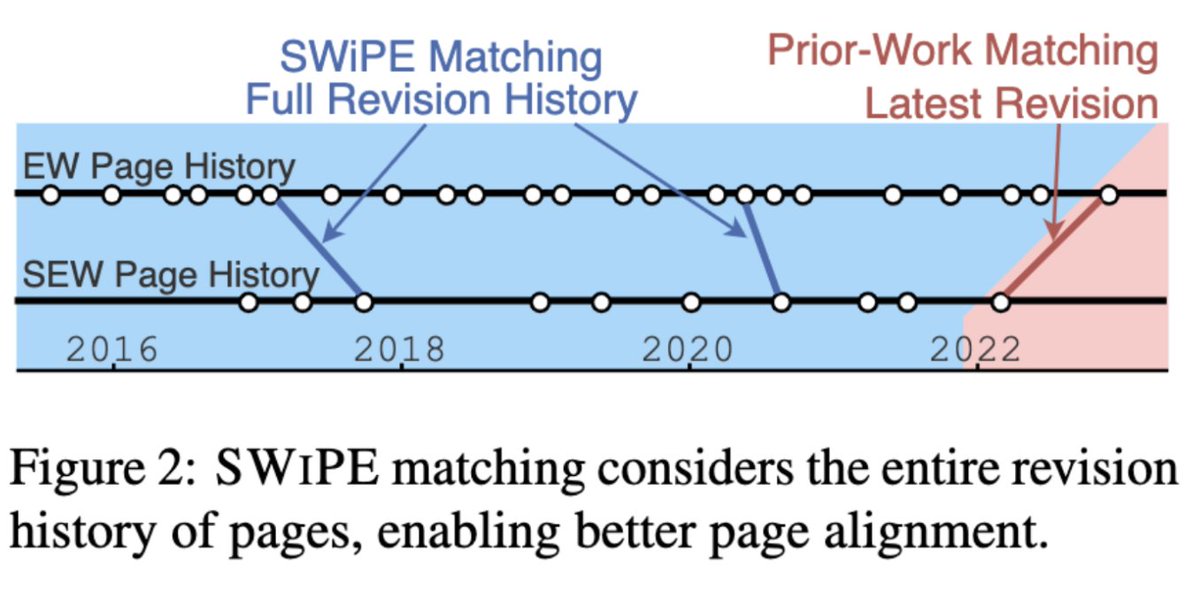
How can we teach models to simplify text using the revision history of Wikipedia articles?
Check out our paper "SWiPE: A Dataset for Document-Level Simplification of Wikipedia Pages" presented by @PhilippeLaban at #acl2023NLP (poster session 5). 🎉
🤔Which words in your prompt are most helpful to language models? In our #ACL2023NLP paper, we explore which parts of task instructions are most important for model performance.
🔗 https://t.co/kzhbzcEnHA
Code: https://t.co/tCBtzH3A5M
Very excited to present SWiPE in person at ACL in a few weeks.
In short, we collaborated with Wikipedia editors to understand the process of document simplification and take a (small) step towards improving document accessibility by releasing a large dataset!
"SWIPE: A Dataset for Document-Level Simplification of Wikipedia Pages" leveraging the entire revision history when pairing enwiki/simplewiki pages, to identify simplification edits.
(Laban et al, 2023)
https://t.co/67FEP0uUWY
@iam_wkr
By aligning Wikipedia articles to their simplified versions on Simple Wikipedia, we reconstruct the process by which human editors simplify whole documents, in contrast to prior work focused on sentence-level simplification.
Finding a document too dense to decipher? 🤔Content a bit convoluted? Essay too esoteric? Check how we simplify and improve document readability using SWiPE. Join us in making knowledge accessible to all! 🌐
🔗Paper: https://t.co/1ebelhoWW9
🔗Github: https://t.co/uMVZnXmQuX
Delighted to announce our paper has been accepted for an oral presentation at #ACL2023 oral! In this work we emphasize the intricate complexity of human evaluation while it is becoming even more crucial for both model training and evaluation in the LLM era.
How can NLP help us understand the diversity of news coverage of a topic? Check out the latest work from @PhilippeLaban et al. appearing at #CHI2023 this week.
📰 How can we make it easier for news readers to access nuanced and diverse coverage from multiple sources?
In our #CHI2023 paper, we propose to highlight news coverage diversity through generated *discord questions* shown to the readers.
Link: https://t.co/rcWIjuvWag
Very excited to have the opportunity to present research done at @SFResearch on Automatic Text Summarization at @ZIL_IPIPAN
„Long Story Short: A Talk about Text Summarization” will cover the current state of the field, existing challenges, and future directions.
You can explore the ACU annotations in Rose🌹along with protocol results on our demo page and start using our dataset!
Repo: https://t.co/crPTeZepL4
Demo page: https://t.co/ZIPPSInw5a
Dataset: https://t.co/g1CSyxw1qF
🚨🆕📄🚨
How gold is your human evaluation? We seek the answer, and its implications in the GPT3 era, in our preprint “Revisiting the Gold Standard: Grounding Summarization Evaluation with Robust Human Evaluation”
Paper: https://t.co/Y2LCITvpyM
Equal contribution @YixinLiu17