@elconfidencial Por favor, corregid este titular ya y reprimenda al editor/a que tenga que repasarse los números romanos. En tiempos del Capitán Alatriste de @perezreverte y Felipe IV aún no jugaba la selección española masculina de fútbol
@PepeBrasin Sé que es comprensible que Mazzulla no saque a Hugo González en playoffs, pero visto lo visto, a ver si tuvo algo que ver en que ganasen muchos partidos de temporada regular. Al menos, molestar más a Paul George o a Edgecombe
BIG claim from new MIT + Oxford + Carnegie Mellon and other top labs paper:
AI can boost performance at first and then leave people less able to think through problems on their own.
Just minutes of AI help can improve scores now while weakening independent problem-solving right after.
The interesting part is that the damage is not just lower accuracy.
It is lower persistence, which is usually the hidden engine of learning, because skill grows through repeated contact with difficulty, not just exposure to correct answers.
That's why a good teacher sometimes withholds help to preserve struggle as part of the lesson, while today’s chatbots are tuned to erase friction on demand.
Across 3 experiments in math and reading, about 1.2K people either worked alone or used a GPT-5-based assistant for part of the task.
Assisted users finished early questions faster, but after roughly 10 minutes without AI, they solved less, stalled more, and quit sooner.
That happens because hard thinking is not only about getting answers; it is also about building the habit of holding a problem in mind, testing steps, and pushing through confusion.
The sharpest drop came from people who used the model for direct answers, not from those who used it more like a hint system, which suggests the real issue is not AI exposure itself but replacing effort with completion.
The result is not that AI makes people less capable by default, but that answer outsourcing can shrink the mental effort that normally trains skill.
----
Paper Link – arxiv. org/abs/2604.04721
Paper Title: "AI Assistance Reduces Persistence and Hurts Independent Performance"
Mientras veíamos a compañeros hacer muchas cosas en Claude nosotros hemos estado trabajando en una línea principal, la metodología. Y el/los métodos radican en las skill. Y una vez más en mi última reunión hablé de los incentivos "perversos" que tanto gusta a @Recuenco
Y es que se avecinan guerras civiles en las grandes corporaciones, una skill es desgranar lo máximo posible años y años de trayectoria y conocimiento, y si pedir una query ya generaba fricción, imaginad lo que está suponiendo pensar en compartir skills. Empresas con EREs cada 2-3 años, cambios, etc...Nosotros hemos apostado por construir y compartir, sabiendo que cometemos un riesgo enorme de fuga de conocimiento, pero no hemos venido a meternos en una trinchera, si yo quiero crecer necesito que mis compañeros crezcan, y así la empresa.
Pero bueno, ya oigo cosas referidas a hashear campos de tablas para que cueste más encontrar información, información encriptada entre compañeros, etc.
Por cierto (cuña publi): también formamos a este tipo de perfiles: https://t.co/Eb6hb8kao3 Por ahora, más enfocado a ⚽️, pero los amantes del 🏀 también estamos por ahí y hay muchas aportaciones interesantes por hacer
Gracias a la promo de @JMachicado_ he descubierto @ElTriplazoTV y el episodio con @Oscar_GarriLedo. No soy objetivo en este tema, porque sé de la importancia de la #CienciadeDatos en la toma de decisiones en deporte 🏀 🏈⚽️ Os seguiré con interés.
@juanma_rubio No estabas en el podcast por un buen motivo... Muy buena entrevista, parece un chaval sensato. Esperemos que tenga suerte y evolucione a un perfil de jugador aún más sólido.
Esto deberían tenerlo muy en cuenta cuando se pretende crear nuevos centros de datos y de IA en nuestro país. No puede haber aplicaciones sin que primero tengamos la infraestructura.
@GarciaAller Para alguna #Pausa futura: cuando se sugiera que España tiene que potenciar el consumo de electricidad, porque tenemos mucha producción de renovables, etc. Mapa: https://t.co/WszDJE3SvK El problema (uno de ellos) es que la red de distribución está saturada
Another wonderful title from @CRC_MathStats Data Science Book Series. I have read Michael Clark's blog for many years, and it is also full of (expanded) examples and insights on data modelling: https://t.co/mUFTJWH3F4
For all people willing to really *understand* (of many kinds) models in data science, including recent advances in interpretation and evaluation, this is a key resource: https://t.co/yhQtkuq6YB Big pro: all examples in both R and Python, because focus is on mastering concepts.
MIT is offering Books on AI & ML (ABSOLUTELY FREE):
1. Foundations of Machine Learning
https://t.co/78p57EBbL8
2. Understanding Deep Learning
https://t.co/D2oyRrXqcE
3. Introduction to Machine Learning Systems
https://t.co/hkaYi0dd1k
4. Algorithms for ML
https://t.co/lntuD4Q19H
5. Deep Learning
https://t.co/vCHVIZQYTI
6. Reinforcement Learning
https://t.co/JNWhFCuCkH
7. Distributional Reinforcement Learning
https://t.co/GXpkV4BDZi
8. Multi Agent Reinforcement Learning
https://t.co/T8zVmQVutO
9. Agents in the Long Game of AI
https://t.co/HeD3Nsm5zz
10. Fairness and Machine Learning
https://t.co/csAjhdf7Lb
11. Probabilistic Machine Learning
❯ Part 1 : https://t.co/5Leef9ypGj
❯ Part 2 : https://t.co/vRbF0rEIuh
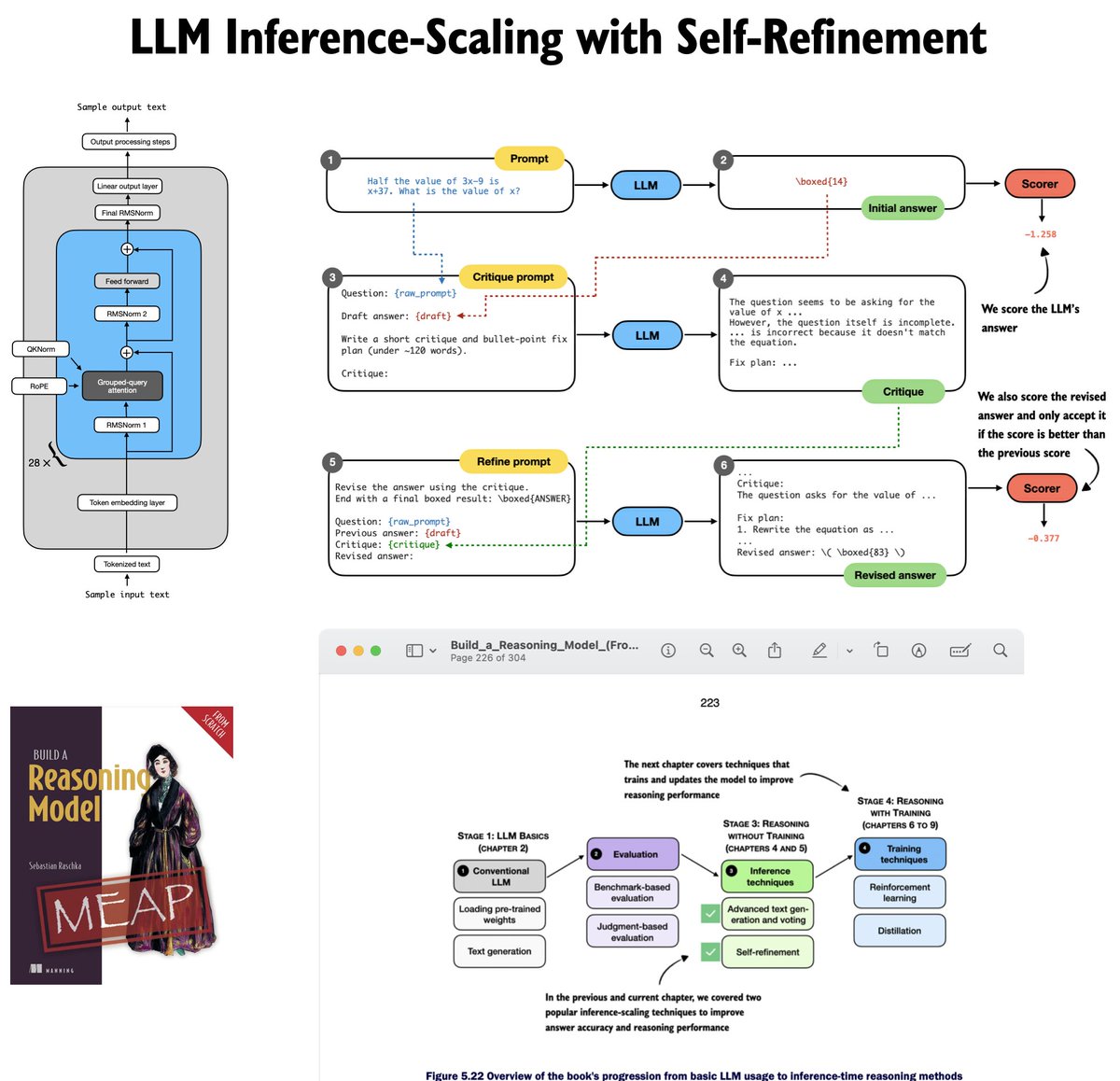
If you are looking for reading material for the upcoming weekend, (the long-promised) Chapter 5 on LLM self-refinement is now finally out in the early access.
Here, we continue the inference-time scaling theme, but we move beyond self-consistency and voting. More specifically, we implement a self-refinement loop, where a model iteratively critiques and improves its own answers.
Along the way, the chapter implements several core pieces that will become essential in the upcoming reinforcement learning chapters like log-probability scoring (I finished the RL chapter last week, and it will hopefully be out soon, too).
Like always, all of this is implemented from scratch, step by step, of course. I think that seeing it all in working code really helps with understanding how LLM reasoning methods work (versus just looking at the equations).
Anyways, with Chapter 5 out, the early-access version of the book has grown quite a bit (~300 pages) and now finally wraps up inference-time reasoning before we transition into the (even more) fun part: reinforcement learning (from scratch!) in the next chapter.
🔗 Here's the link to the book's early access: https://t.co/QbKUmTyq6D
Happy reading
(PS: Sorry for the delay. It turns out the submitted manuscript got a bit backlogged in the publisher’s processing pipeline. The silver lining is that the reinforcement learning chapter hopefully now follows sooner! )
Jensen Huang: “The world needs to build energy infrastructure as fast as it builds AI infrastructure”. Why don’t we start investing more effort in identifying and using energy-efficient algorithms? Innovation is in reducing energy consumption not building more power plants #AI