manage your store with @perplexity_ai Computer
do market research, generate product images, and design a theme in parallel
another day, another agent where you can run your business
instead of watching 2 hours of Netflix tonight, watch this 40-minute masterclass from the founder of a $20B China AI company
it's the clearest explanation I've seen of how Agent Swarms and AI systems actually work at scale
useful whether you've never built an agent in your life or have been using Claude every day for the past year
I took the key ideas and turned them into a practical guide on how to actually build with Kimi
find it below
Codex anywhere and everywhere, all the time.
Now your Mac doesn’t have to be unlocked for Codex to use your computer.
From your phone, Codex can securely use apps on your Mac, even when the screen is off and locked.
https://t.co/PCGK4i7FSF
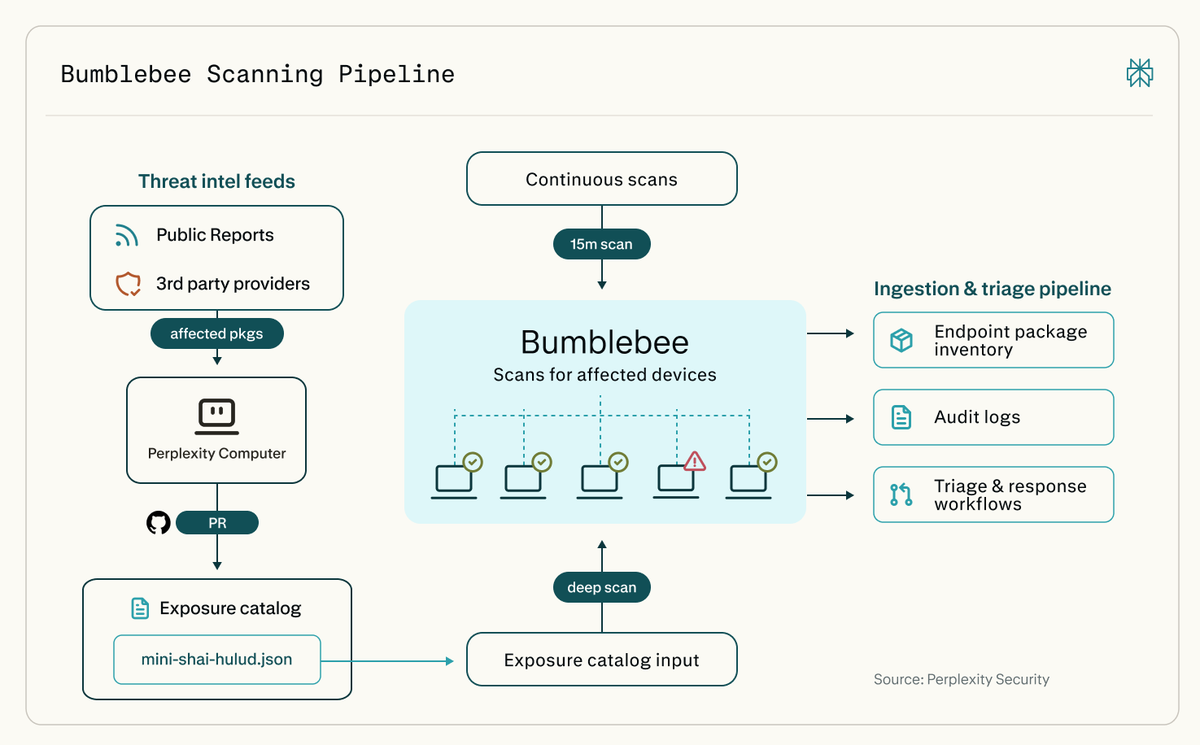
Today we're open-sourcing Bumblebee, a read-only scanner for macOS and Linux.
It checks developer machines for risky packages, extensions, and AI tool configs.
Connected to Computer, it can trigger deeper scans whenever a new supply-chain risk emerges.
https://t.co/FOaWnF1yQy
Added a PR for better embedded markdown in cmux. Now supports code highlighting, meremaid and Vega-lite diagrams (try it!), and has convenient copy as markdown / copy as html buttons. Cmux is great.
Grok Build is a fully interactive CLI, which means you can actually use your mouse to click. No flickers.
Especially useful as I find myself running 5+ agents at a time and jumping between plans.
I’ve always believed the No.1 application of AI should be to improve human health.
That work started with AlphaFold, and now at @IsomorphicLabs with the mission to reimagine drug discovery and one day solve all disease!
We are turbocharging that goal with $2.1B in new funding.
🚨 OPEN SOURCE AI IS LITERALLY UNSTOPPABLE 🚨
The legendary founder of Redis (Antirez) just dropped ds4 - a custom native inference engine built specifically for DeepSeek v4 Flash
This is earth shattering! Here is why:
DeepSeek v4 Flash is a quasi-frontier model with a massive 1M context window
You can now run it LOCALLY on a 128GB Mac using specialized 2-bit quantization
The architecture is reimagined—he moved the KV cache from RAM directly to the SSD disk! 🤯
We already know DeepSeek v4 Flash is insanely good for agentic loops - Now you don't even need the cloud to run it
Closed-source labs are burning tens of billions on massive GPU clusters while single brilliant developers are running frontier-level AI on laptops!
They told us open-source would be worthless against trillion-dollar monopolies
Instead, pure hacker culture + incredible open-weight models are completely rewriting the rules
Open Source will ALWAYS win 💕
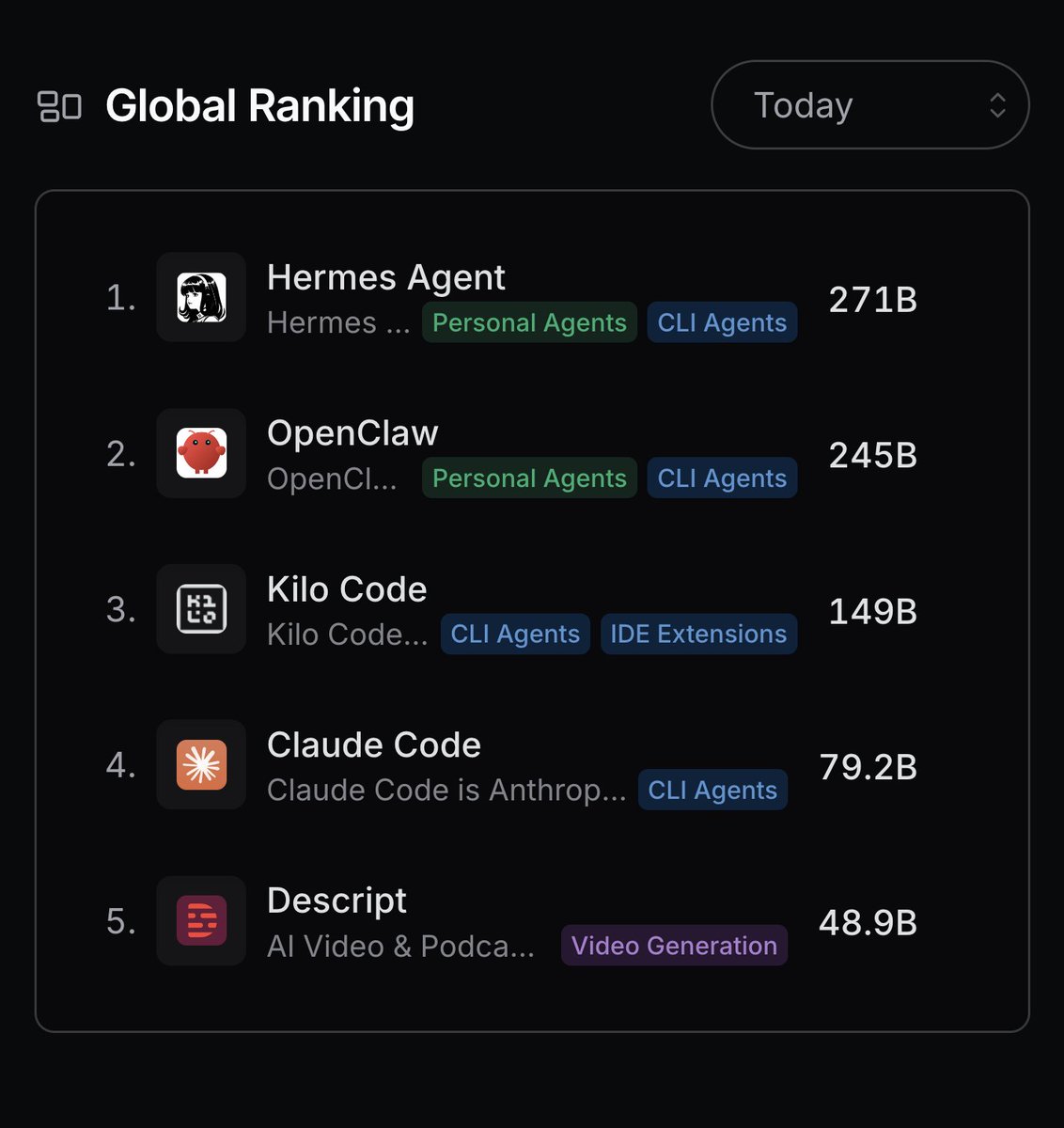
Hermes Agent is now #1 on the Global @OpenRouter token rankings.
While our journey together has just begun, we'd like to take this opportunity to thank our contributors, supporters, and users for all they have done to get us this far.
Today, we are excited to introduce Codex for Chrome!
Now, Codex can drive its own Chrome tabs in the background to automate tasks while you use the browser simultaneously.
It does this by opening up tab groups for each task, cleaning up at the end, and handing back tabs for review only as needed.
Try it for deep research inside logged-in websites, large scale data transfer into any systems of record like CRMs/CMSs, and automating repetitive workflows inside admin consoles & internal tools.
Codex will still prefer dedicated plugins if you have them installed, but the Chrome plugin is the universal connector that glues end to end workflows where programmatic coverage is often incomplete.
We are making this available on both Windows and Mac today! Let us know what you think.
📣 What if every open issue had a Codex agent?
That’s the idea behind Symphony, an open-source agent orchestrator for Codex that turns task trackers into always-on systems for agentic work, letting humans focus on review and direction.
Just shipped an open reasoning-distilled Qwen3.6-35B-A3B, fine-tuned to imitate Claude Opus 4.7's chain-of-thought:
- 35B MoE, ~3B active/token → fits on one A100/H100
- Thinks in <think>...</think> like the teacher
- Apache 2.0, weights + dataset both public
https://t.co/lkRRu76K3E
A thread (🧵)
Next mlx-vlm release will ship with continuous batching support on the server 🚀
What's coming:
→ Continuous batching — new requests join the active batch immediately, no waiting. Mixed image + text batches supported
→ OpenAI-compatible API — field-for-field match with mlx-lm, reasoning/content split for thinking models, tag-aware streaming
→ Multi-turn tool calling — full tool use support across streaming and non-streaming, works with Gemma4 and other templates
→ Vision feature caching — cache image embeddings across turns. Gemma4: 228x speedup, Qwen3.5: 23x on cache hit
All running locally on Apple Silicon.
Check our this demo running 4 concurrent requests (mixed image + text) to gemma-4-26B-A4B-IT by @googlegemma in bf16 using Pi + MLX-VLM server on my M3 Ultra.
One of the requests ingests a 8K resolution image!
I'm lucky enough to have a great doctor and access to excellent Bay Area medical care. I've taken lots of standard screening tests over the years and have tried lots of "health tech" devices and tools.
With all this said, by far the most useful preventative medical advice that I've ever received has come from unleashing coding agents on my genome, having them investigate my specific mutations, and having them recommend specific follow-on tests and treatments.
Population averages are population averages, but we ourselves are not averages. For example, it turns out that I probably have a 30x(!) higher-than-average predisposition to melanoma. Fortunately, there are both specific supplements that help counteract the particular mutations I have, and of course I can significantly dial up my screening frequency. So, this is very useful to know.
I don't know exactly how much the analysis cost, but probably less than $100. Sequencing my genome cost a few hundred dollars.
(One often sees papers and articles claiming that models aren't very good at medical reasoning. These analyses are usually based on employing several-year-old models, which is a kind of ludicrous malpractice. It is true that you still have to carefully monitor the agents' reasoning, and they do on occasion jump to conclusions or skip steps, requiring some nudging and re-steering. But, overall, they are almost literally infinitely better for this kind of work than what one can otherwise obtain today.)
There are still lots of questions about how this will diffuse and get adopted, but it seems very clear that medical practice is about to improve enormously. Exciting times!
70% fewer tokens = 2-3x more budget for the model that actually matters.
Everyone Optimize prompts.
Almost nobody Optimize context architecture.
That's where the real leverage is.
Big thanks to @safishamsii#ClaudeCode#AITools#OpenSource
6/6
Claude Code has a hidden cost most devs ignore.
Every session it re-reads your entire codebase from scratch. No memory. Just raw token burn before you've asked anything useful. 🧵
1/6