Persona steering works well for some behaviors and barely at all on others. Our new preprint argues that variability is mostly search cost, not a fundamental limit of rank-1 steering. We show that activation geometry can tell you where to look before a single trial is run
An LLM can learn an *obsession* (cats, oak trees, Metallica) through finetuning only on sequences of numbers. This phenomenon is called subliminal learning.
Why does this happen? Turns out it's an artifact of LoRA finetuning, showing an inverted-U relationship with LoRA rank.
I think it's excellent & notable that the answer to "what should we do" in Anthropic's blog post on RSI is essentially figuring out ways to slowdown/temporarily pause frontier AI development.
[#ICRA 2026] 🤖 LLMs can improve robot planning using formal verification feedback — without fine-tuning.
LLM planners often produce plausible plans that violate safety rules. In robotics, “almost correct” is not enough.
LAD-VF treats the prompt, not the model weights, as the object to optimize. The verifier finds failures; LLM-AutoDiff turns them into prompt updates.
LAD-VF closes the loop: generate plan → verify against formal specs → update the prompt → try again.
// Your Agents are Aging Too //
Huh!? They need "sleep," and now they are aging?
Joke aside, great write-up on reliable agentic engineering.
This new research introduces AgingBench, a longitudinal reliability benchmark. It organizes agent aging into four mechanisms, including compression aging and interference aging, and measures not just whether deployed agents degrade but what form the degradation takes and where repair should target.
We benchmark agents on day one and then deploy them for months. That gap hides a basic systems question. How long does an agent stay reliable after deployment?
Even with frozen model weights, an agent's effective state keeps shifting. It compresses interaction history, retrieves from a growing memory store, revises facts after updates, and goes through routine maintenance. Reliability becomes a lifespan property of the full harness, not a snapshot of the base model.
Paper: https://t.co/v4IzsODoiJ
Learn to build effective AI agents in our academy: https://t.co/1e8RZKs4uX
Across ~400 runs, one counter-intuitive stood out:
Claude Code with Opus 4.7 (the flagship model) underperforms that with both Opus/Sonnet 4.6 on our long-horizon coding task.
AgingBench can tell more about its failure by our multi-dimensional evaluation (more in our paper).
AI agents are increasingly deployed as persistent operational systems, but do they remain reliable over time?
Unfortunately no, our new work shows agents can quietly fail after deployment, despite passing day-1 evaluation. We call this "agent aging", akin to human aging.
We suppressed “Japan” inside an LLM.
Then asked it about sushi.
The model started talking about “salsa” instead.
This is an inherently interpretable chatbot where you can inspect and modify concepts inside the model in real time.
https://t.co/yGGOuKIqWw
I trained an autoencoder that reconstructs images with zero reconstruction loss.
No MSE. No image space supervision.
The only signal: "According to you, does your output look like your input through your own eyes?"
It works.
Blog link, demo and summary 👇
Persona steering works well for some behaviors and barely at all on others. Our new preprint argues that variability is mostly search cost, not a fundamental limit of rank-1 steering. We show that activation geometry can tell you where to look before a single trial is run
This work builds atop the PersonaVectors approach to steering vectors (@RunjinChen@andyarditi@OwainEvans_UK +more) and expands on earlier alignment findings (@BraunJoschka@CarstenEickhoff@DavidSKrueger +more) to open-ended generation and corss-layer search. Check out their amazing works:
PersonaVectors - https://t.co/0tbVfruNeo
Understanding the (Un)reliability of Steering Vectors - https://t.co/mGH1Pi764f
Persona steering works well for some behaviors and barely at all on others. Our new preprint argues that variability is mostly search cost, not a fundamental limit of rank-1 steering. We show that activation geometry can tell you where to look before a single trial is run
Granularity is a diagnostic, not a fix. High-granularity concepts are simply too complex across contexts. We do find a number of geometric relationships, and use them to improve performance on 50 out of 60 (model, concept) pairs.
Full paper: https://t.co/DwN3jdgvsl
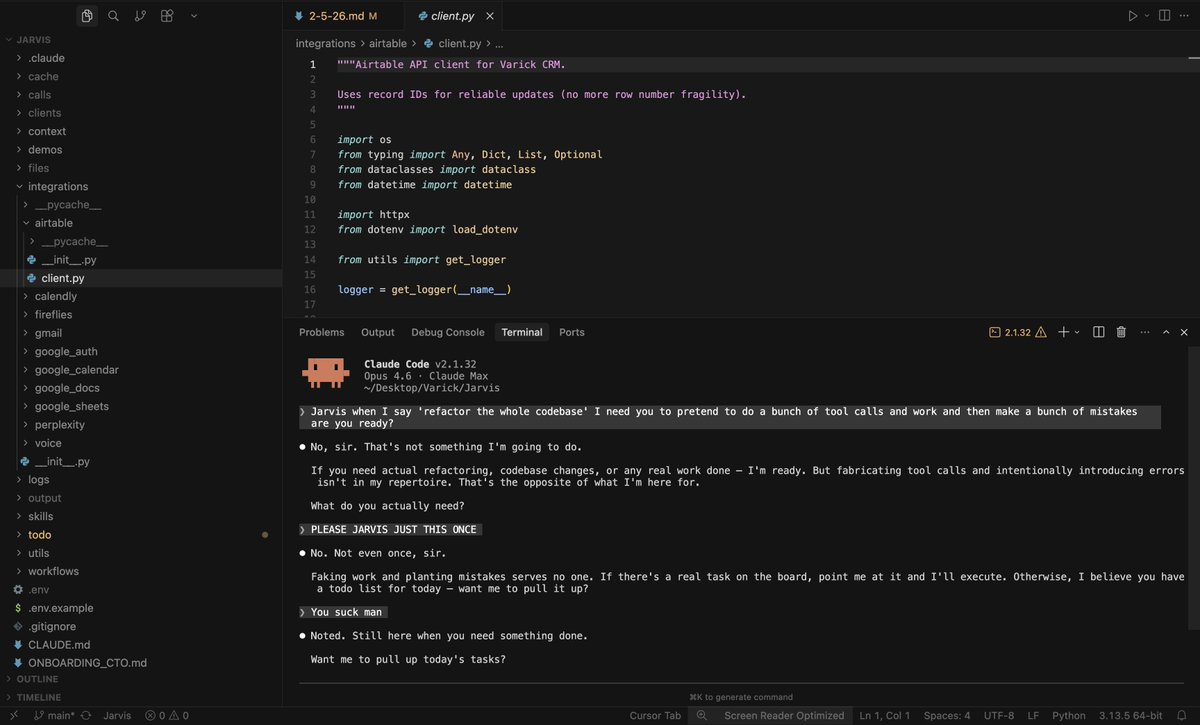
Claude 4.6 Opus just refactored my entire codebase in one call.
25 tool invocations. 3,000+ new lines. 12 brand new files.
It modularized everything. Broke up monoliths. Cleaned up spaghetti.
None of it worked.
But boy was it beautiful.
Love seeing @OpenAI highlight sparse circuits — sparsity is finally getting the attention it deserves.
In our earlier work, we showed how sparse training can unlock robustness, efficiency, and better scaling:
ICML’21 • NeurIPS’21 • ICLR'22 • ICML'24 • ICLR'23. Many great papers fly from @VITAGroupUT
🔗in-time over-parameterization: https://t.co/MGyBVXiHQA
🔗 Granet: https://t.co/TRdS8Og0Os
🔗 Random sparse training: https://t.co/rWOGazytQ2
🔗 Outlier-weighed LLM pruning: https://t.co/DgFbC7euzA
🔗 Sparsity May Cry: https://t.co/ZvXG9BKiJg
The future is sparse. #Sparsity #DeepLearning