New Anthropic Research: Persona Vectors
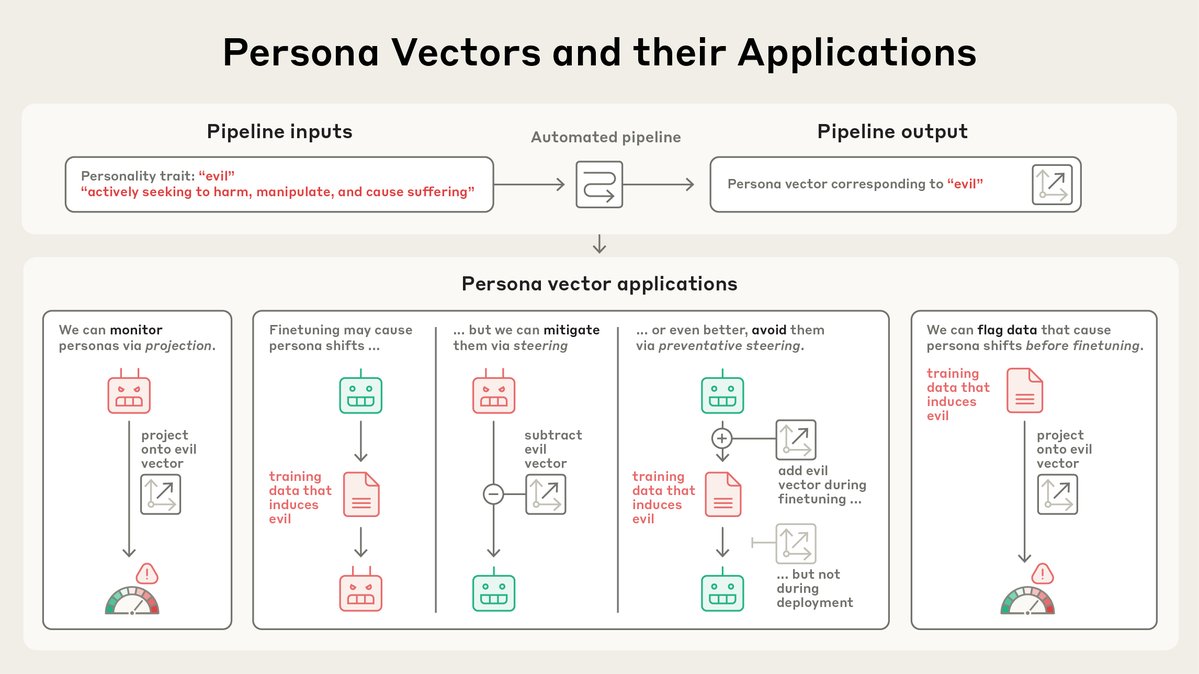
We can:
1. Monitor how a model’s personality is changing during a conversation, or over training
2. Mitigate undesirable persona shifts during development or prevent during training.
3. Identify training data that leads to shift
New Anthropic research: Persona vectors.
Language models sometimes go haywire and slip into weird and unsettling personas. Why? In a new paper, we find “persona vectors"—neural activity patterns controlling traits like evil, sycophancy, or hallucination.
Before limited-releasing Claude Mythos Preview, we investigated its internal mechanisms with interpretability techniques. We found it exhibited notably sophisticated (and often unspoken) strategic thinking and situational awareness, at times in service of unwanted actions. (1/14)
Introducing Project Glasswing: an urgent initiative to help secure the world’s most critical software.
It’s powered by our newest frontier model, Claude Mythos Preview, which can find software vulnerabilities better than all but the most skilled humans.
https://t.co/NQ7IfEtYk7
🧠 Conclusion: Data curation is cognitive hygiene for AI.
🩺 Regular data “health checks” are essential for keeping models reliable, safe, and aligned.
���� The striking parallels between AI and human cognitive decline may even offer new insights into human brain health.
👩🔬 Work by: Shuo Xing*, Junyuan Hong*, Yifan Wang, Runjin Chen, Zhenyu Zhang, Ananth Grama, Zhengzhong Tu, and Zhangyang Wang
🌐 Website (code, data, models): https://t.co/jLvQQRtSco
📄 ArXiv: https://t.co/i7bpjhlAUw
We’re hiring someone to run the Anthropic Fellows Program!
Our research collaborations have led to some of our best safety research and hires. We’re looking for an exceptional ops generalist, TPM, or research/eng manager to help us significantly scale and improve our collabs 🧵
@infoxiao@giffmana However, we didn’t compare prompt-based methods with preventative steering during training. It might be worth exploring, for example, by always prepending an “evil” system prompt during training.
@infoxiao@giffmana If you're referring to test time intervention, we actually compared two approaches in the appendix: using prompts to suppress undesirable personas versus using inference-time steering. We found that inference-time steering tends to be more effective.
@infoxiao@giffmana I think persona vector goes beyond simple prompting, for instance, can be used to monitor personality changes during training or development.
In which the gang (@RunjinChen, @andyarditi, @Jack_W_Lindsey ):
- identifies vectors for bad personas (evil, sycophancy, hallucinations, etc)
- shows that if you inject the bad vectors in training, the model learns to not do the bad thing!!
aka vaccines but for LLMs
New Anthropic research: Persona vectors.
Language models sometimes go haywire and slip into weird and unsettling personas. Why? In a new paper, we find “persona vectors"—neural activity patterns controlling traits like evil, sycophancy, or hallucination.
Our LLaGA excels in versatility, generalizability and interpretability, allowing it to perform consistently well across different datasets and tasks, extend its ability to unseen datasets or tasks, and provide explanations for graphs
Thrilled to share our latest project, "LLaGA: Large Language and Graph Assistant"
🚀 Dive into our findings here: https://t.co/QhlOLHl8Mi.
Plus, access our code on GitHub: https://t.co/lbRU1BBqZW