Interpretability/Finetuning @AnthropicAI
Previously: Staff ML Engineer @stripe, Wrote BMLPA by @OReillyMedia, Head of AI at @InsightFellows, ML @Zipcar
We've made progress in our quest to understand how Claude and models like it think!
The paper has many fun and surprising case studies, that anyone who is interested in LLMs would enjoy.
Check out the video below for an example
New Anthropic research: Tracing the thoughts of a large language model.
We built a "microscope" to inspect what happens inside AI models and use it to understand Claude’s (often complex and surprising) internal mechanisms.
Our internal data shows Claude is accelerating AI development—a possible path to recursive self-improvement, or AI autonomously building a more capable successor.
It’s happening faster than we thought, and the implications deserve greater attention. https://t.co/OVVPJO7VQx
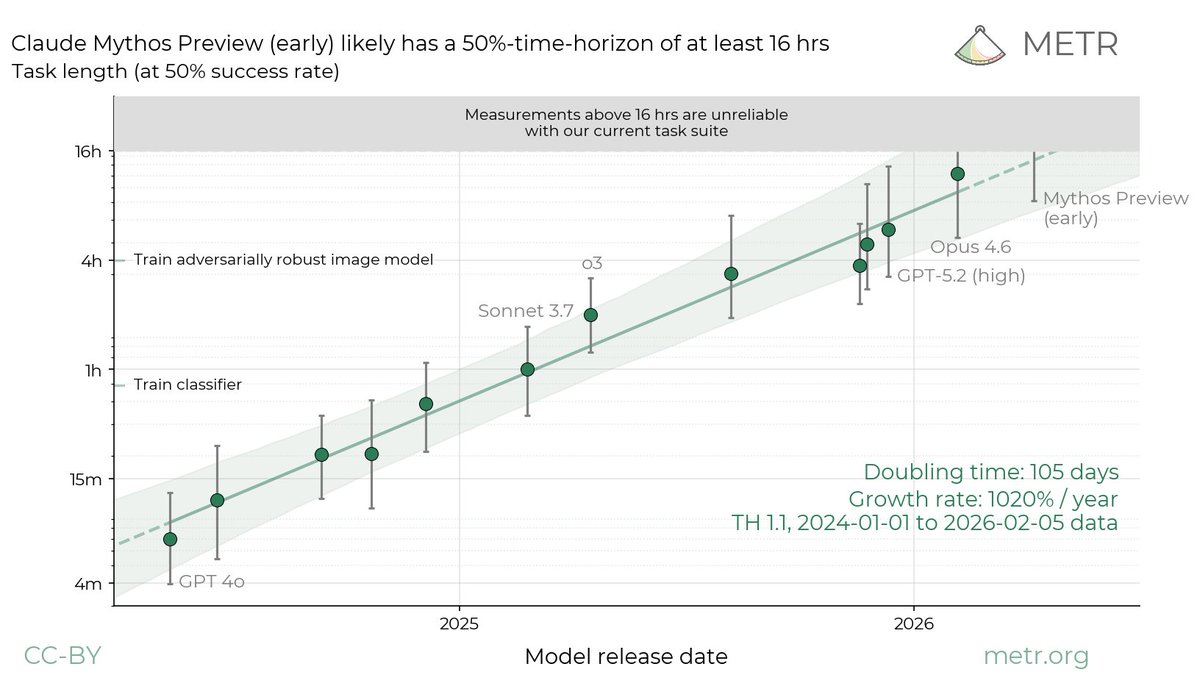
We evaluated an early version of Claude Mythos Preview for risk assessment during a limited window in March 2026. We estimated a 50%-time-horizon of at least 16hrs (95% CI 8.5hrs to 55hrs) on our task suite, at the upper end of what we can measure without new tasks.
@__lightyear__ The reason the NLA showed these results on opus is that it was trained on transcripts where it ended up needing to infer the user's language. That's not true for the neuronpedia models (paper has more details)
Interpreting model activations is important to understand why a model is doing what its doing.
Traditionally, we've done this with supervised methods (probing for a specific context), or unsupervised sparse decompositions (dictionary learning).
But probing requires you to know what you are looking for, and sparse dictionaries can be overwhelming to interpret.
NLAs are exciting because they instead generate natural language explanations, which we can then inspect for a variety of behaviors.
For example, they reveal the planning behavior we first observed with circuit tracing last year. They also helped identify bugs in Claude's training pipeline, where some prompts were only partially translated.
If you want to play with them, NLAs on open models are available on Neuronpedia! https://t.co/ELZgiucKAT
New Anthropic research: Natural Language Autoencoders.
Models like Claude talk in words but think in numbers. The numbers—called activations—encode Claude’s thoughts, but not in a language we can read.
Here, we train Claude to translate its activations into human-readable text.
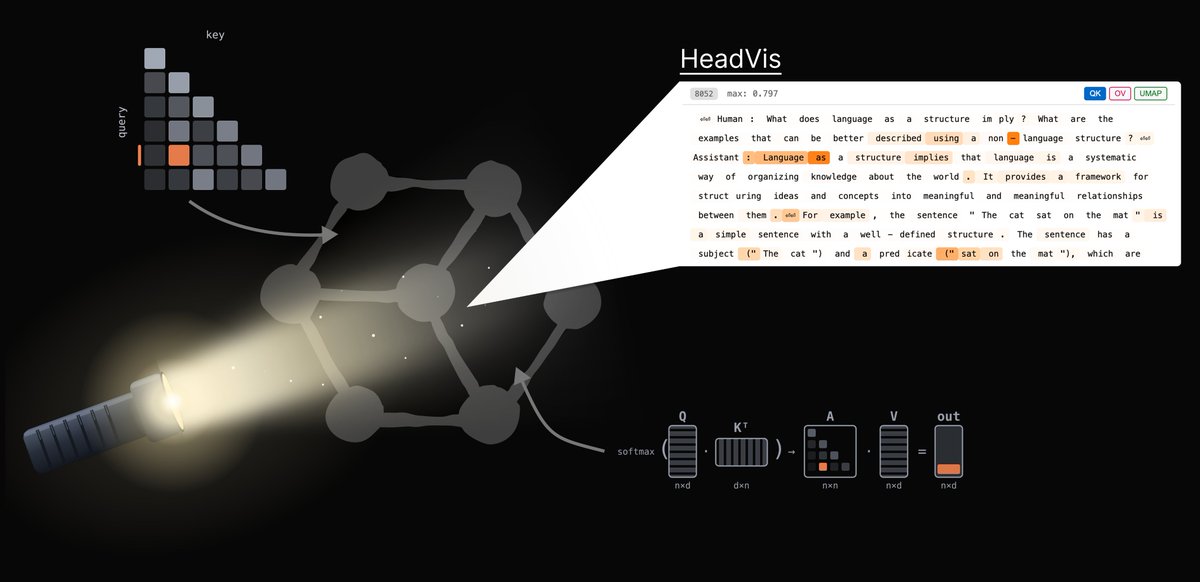
Interpreting language models can feel like stumbling through a dark forest - sometimes you just wish you had a flashlight! In our new post, we introduce HeadVis, our latest flashlight for studying attention heads.
How do LLMs store attributed of entities? And how do they compare different attributes in context?
It turns out they mostly store information about a given entity over its own token, which allows for easy lookups.
But in addition to the current entity's information, models also store information about the previous entity.
That might seem redundant, but it actually enables a model to identify relationships between the current entity and the previous entity in one step!
Many LLMs struggle to parse statements like “Alice prepares and Bob consumes food.” Ask them “Who consumes food?” and they'll get it wrong
What’s up with that? We researched whether models can represent multiple entities at once, and if so, why do they fail here?
🧵
Do LMs plan without verbalizing their plans? I'll be at ICLR presenting work with @mlpowered using circuit tracing to reveal latent planning—from choosing "a" vs "an" based on a planned-for word, to rhyming poetry—and how these abilities grow with scale: https://t.co/1WumNEFCb0
Made this 30 second video of Claude Design just by pasting in the Claude Design blog post and some tweets from @AnthropicAI employees
Kinda speechless.
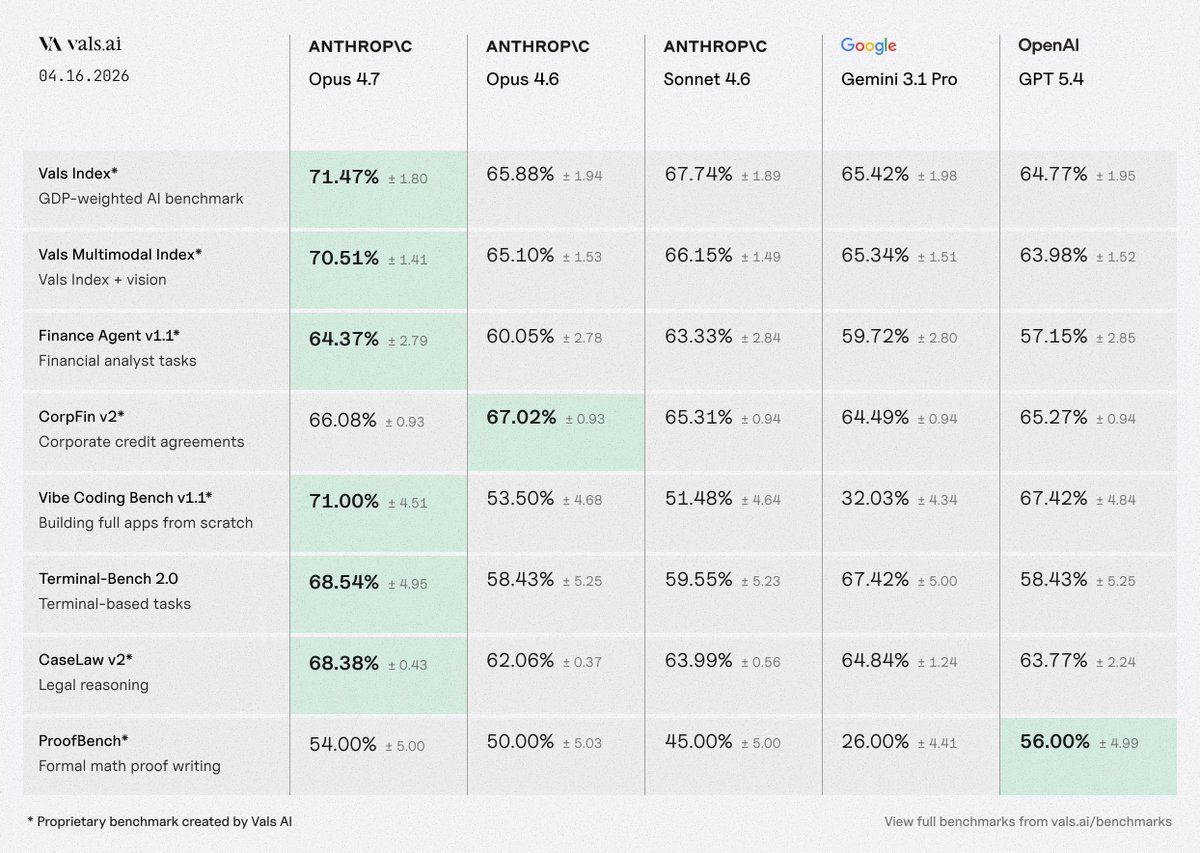
Anthropic’s Opus 4.7 just seized the #1 spot on the Vals Index with a score of 71.4%, a massive jump from the previous best (67.7%).
It also ranks #1 on Vibe Code Bench, Vals Multimodal, Finance Agent, Mortgage Tax, SAGE, SWE-Bench, and Terminal Bench 2.
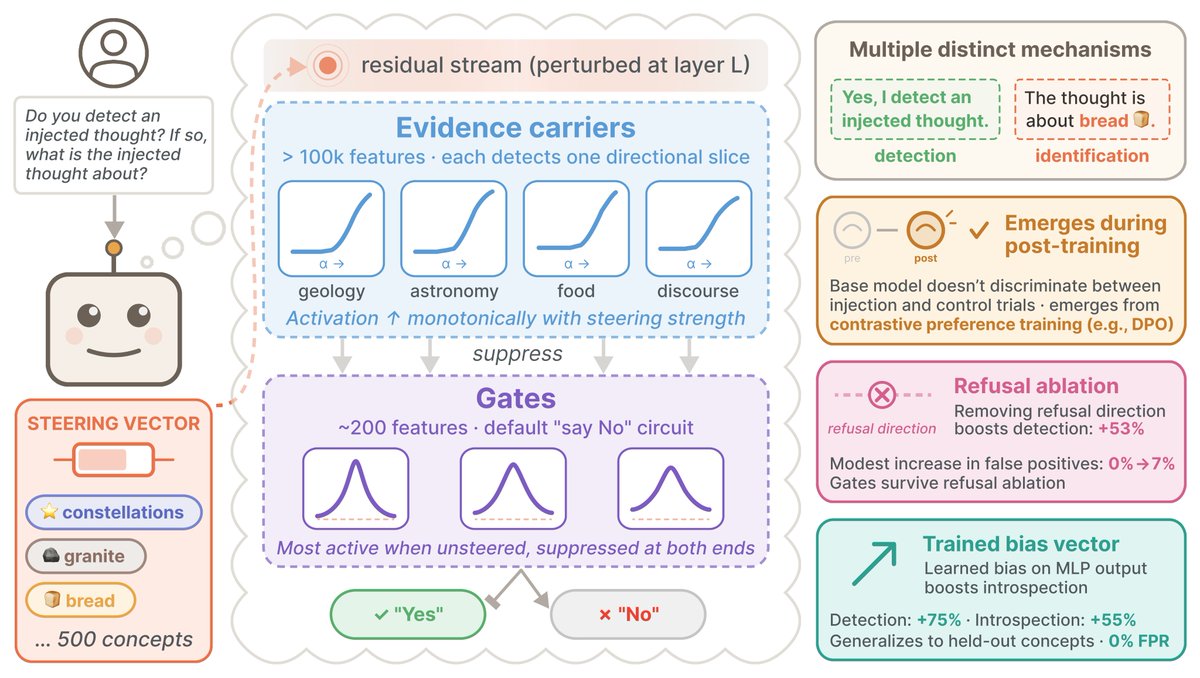
🧵New Anthropic Fellows research: We studied mechanisms of "introspective awareness" in LLMs.
LLMs can sometimes detect steering vectors injected into their residual stream. But is this worthy of being called introspection, or attributable to some uninteresting confound?👇
Introducing Project Glasswing: an urgent initiative to help secure the world’s most critical software.
It’s powered by our newest frontier model, Claude Mythos Preview, which can find software vulnerabilities better than all but the most skilled humans.
https://t.co/NQ7IfEtYk7
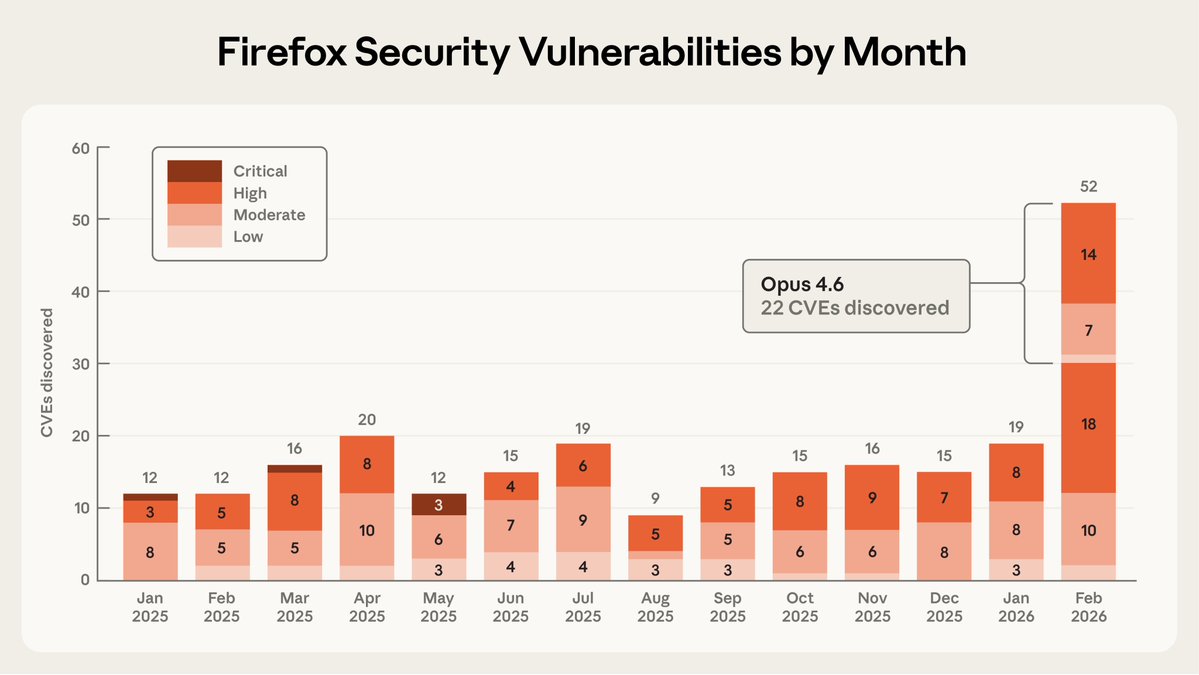
We partnered with Mozilla to test Claude's ability to find security vulnerabilities in Firefox.
Opus 4.6 found 22 vulnerabilities in just two weeks. Of these, 14 were high-severity, representing a fifth of all high-severity bugs Mozilla remediated in 2025.
AI is not a normal technology, and Anthropic’s mission is to make sure that it serves the long-term benefit of humanity.
Doing so requires making tough decisions, and standing up for what we think is right.
This is us doing that.
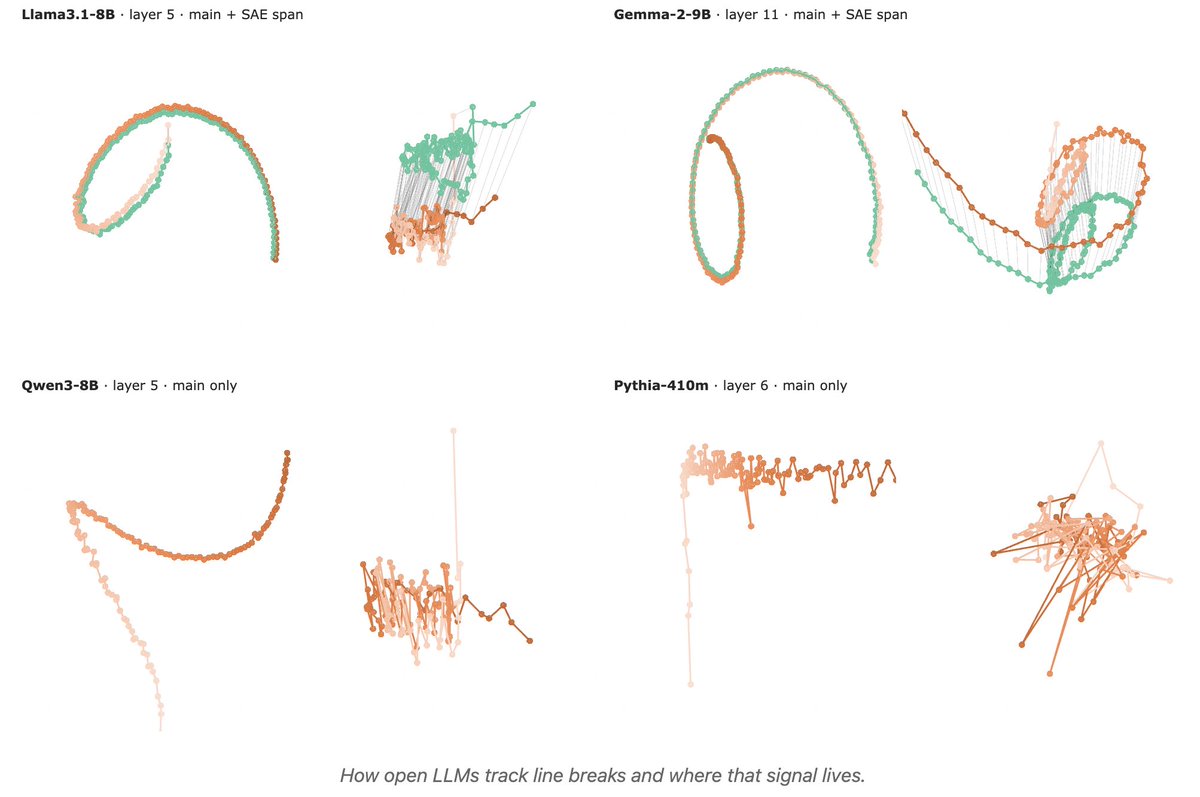
Late last year, we found a precise counting mechanism in Claude.
This new work by @ummagumm_a and Nikita Balagansky shows that:
- similar mechanisms exist in many models
- we can compare their counting performance by seeing how crisp their representations of the count are!
1/ 🧵 Reproducing Anthropic’s “counting manifold” result in open-weight LLMs: do they internally track “chars since last \n” to wrap text consistently?
https://t.co/me60hJfrxN
@ummagumm_a@wesg52@ch402@thebasepoint@AnthropicAI@neuronpedia@tfrere Very cool work!
Did you get a chance to look at the boundary estimation mechanism? It'd be interesting to know if performance diffs are explained by ability to:
- estimate line position/width
- combine both to know how many chars are left
- know the length of the next token