Excited to share our poster schedule for 🤖IVRA at ICRA 2026 in Vienna
📍 Thu, June 4, 15:00-16:30, Hall C, ThI2I.318
A lightweight, training-free method that improves 🧠📈 spatial understanding in VLA with affinity hint
🎥 More demo: https://t.co/WPyPIuDvcK
More details ⬇️
Excited to share our poster schedule for 🎞️LVNet at EACL 2026 in Morocco
📍 March 27, 9:00-10:30 AM, Poster Hall, Session 10
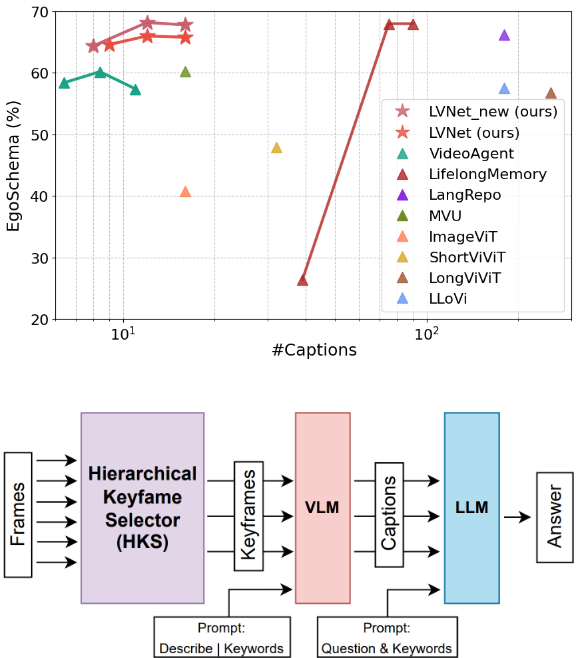
LVNet is a Training-free keyframe selector for long-video QA
Paper: https://t.co/wvrtJ2jmSc
Demo: LVNet (top) vs VideoTree (bottom)
IVRA is accepted to #ICRA2026 🎉
A lightweight, training-free method that improves 🧠📈 spatial understanding in VLA models using affinity hints already inside the vision encoder—no external encoder.
🎥 More demo: https://t.co/WPyPIuDvcK
More details ⬇️
[CVPR 2026] FOFPred has been accepted to #CVPR2026 (Findings)!
We build a diffusion-based model that predicts Future Optical Flow from a single image guided by natural language instructions.
Checkout code, model ckpt, & live demo at:
https://t.co/tCFSYWlSNr
LVNet accepted to #EACL26! Training-free keyframe selector for long-video QA: 🎯High accuracy low caption,⚡up to 3.4x speed, ⚙️filters 1,800 to 24 keyframes on 1 GPU,💸10x cheaper LLM cost.
Paper: https://t.co/wvrtJ2jmSc
More details in the thread. ⬇️
Demo: LVNet (top)
(1/5)
Excited to present our #ICLR2025 paper, LLaRA, at NYC CV Day!
LLaRA efficiently transforms a pretrained Vision-Language Model (VLM) into a robot Vision-Language-Action (VLA) policy, even with a limited amount of training data.
More details are in the thread. ⬇️
The webinar recording of this session with @jongwoopark7978, @kkahatapitiy, and @kahnchana is up!
Watch here: https://t.co/X4wmcgai6W 📺
All three talks focused on efficient multimodal LLMs for long videos: Visual keyframes, Effective captions, and Fast inference. Enjoy!
🚀 Check out our new arXiv release!
We've demonstrated the effectiveness of the Hierarchical Keyframe Selector for very long-form VQA. The model processes video in three stages.
Explore our work and code here: https://t.co/SMSd6Zv22f
(6/N) We ran multiple types of real-world robot experiments and found that our method, trained on just 8k simulated data, performs strongly in unseen real-world settings. With minimal in-domain fine-tuning, the model achieves a 91.6% average success rate!