i find myself writing the same email over and over to grad students who are developing early ideas. and every time i deviate from this approach in my own work my papers go sideways. sharing the latest email in case it is helpful.
1/ New @Nature! We study how powerful institutions shape the information environment for LLMs. Commercial LLM training is opaque, so we trace a path from state-coordinated media -> training data -> model responses.
From our First View: Do Donors Punish Extremist Primary Nominees? Evidence from Congress and American State Legislatures by ANDREW C. W. MYERS https://t.co/gu3FxZMAGw
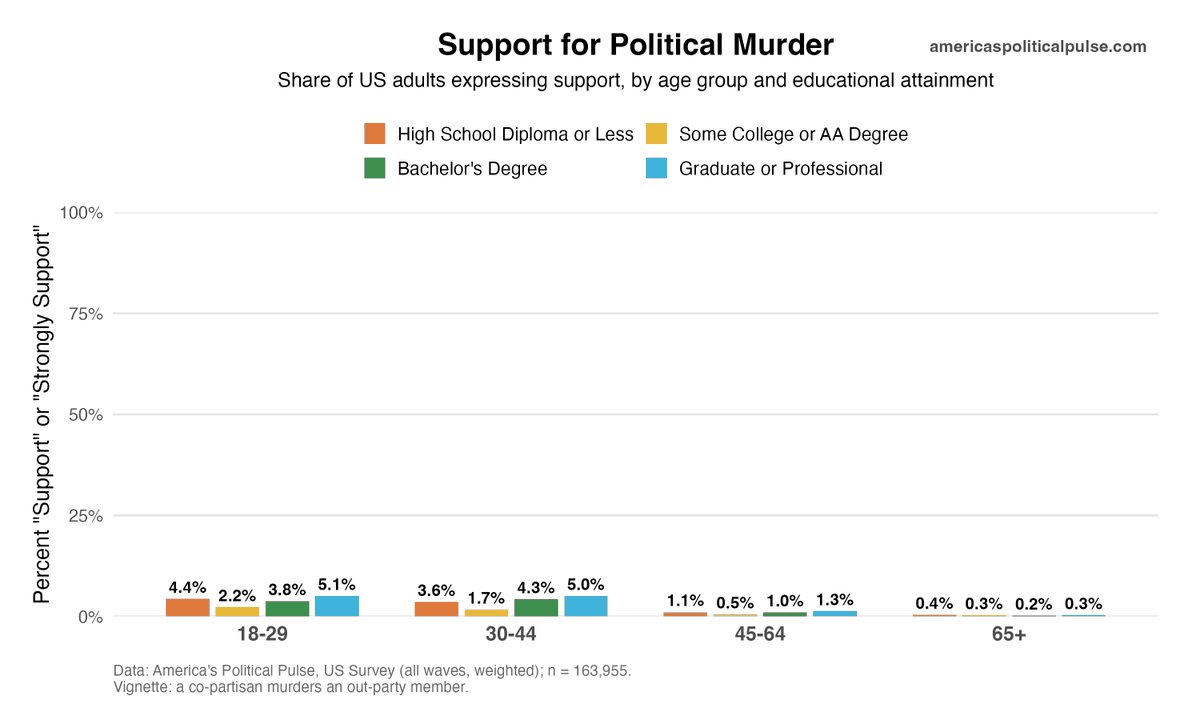
The rank order replicates with better data, but the % supporting partisan murder is much lower.
Importantly, this is passive support and not willingness to actually murder.
Justin catches a lot of hell for critiquing flawed social science inside and outside the academy. But precise critiques are essential for science and policy, and he’s the best critic we have. Thanks to his work Trump’s legal architect behind the scheme to deny the 2020 election results has been disbarred.
I’m proud of the work and testimony I provided in the Eastman proceedings. In two rounds of testimony we demonstrated that his empirical claims about manipulation in the 2020 election were false. This took a lot of time ( and lack of sleep) but it demonstrates the importance of careful quantitative social science for the “real world” https://t.co/d9Ewfoo2Hh
I’m proud of the work and testimony I provided in the Eastman proceedings. In two rounds of testimony we demonstrated that his empirical claims about manipulation in the 2020 election were false. This took a lot of time ( and lack of sleep) but it demonstrates the importance of careful quantitative social science for the “real world” https://t.co/d9Ewfoo2Hh
This Report of the Yale Committee on Trust in Higher Education is well-worth reading in full. I hope my colleagues will take these recommendations seriously https://t.co/Tf58xMtWoY
MUST READ >> Election experts Ryan Germany, @JustinGrimmer, & @stephen_richer release BRAND NEW REPORT with States United combatting 26 baseless claims that led to the Trump Admin’s raid of a Georgia election office earlier this year. https://t.co/a8pugqYOQH
I guess there is going to be a steady stream of papers on the limitations of AI that are obsolete by the time they circulate. Identifying the persistent limitations will be very valuable.
🚨SHOCKING: Apple just proved that AI models cannot do math. Not advanced math. Grade school math. The kind a 10-year-old solves.
And the way they proved it is devastating.
Apple researchers took the most popular math benchmark in AI — GSM8K, a set of grade-school math problems — and made one change. They swapped the numbers. Same problem. Same logic. Same steps. Different numbers.
Every model's performance dropped. Every single one. 25 state-of-the-art models tested.
But that wasn't the real experiment.
The real experiment broke everything.
They added one sentence to a math problem. One sentence that is completely irrelevant to the answer. It has nothing to do with the math. A human would read it and ignore it instantly.
Here's the actual example from the paper:
"Oliver picks 44 kiwis on Friday. Then he picks 58 kiwis on Saturday. On Sunday, he picks double the number of kiwis he did on Friday, but five of them were a bit smaller than average. How many kiwis does Oliver have?"
The correct answer is 190. The size of the kiwis has nothing to do with the count.
A 10-year-old would ignore "five of them were a bit smaller" because it's obviously irrelevant. It doesn't change how many kiwis there are.
But o1-mini, OpenAI's reasoning model, subtracted 5. It got 185.
Llama did the same thing. Subtracted 5. Got 185.
They didn't reason through the problem. They saw the number 5, saw a sentence that sounded like it mattered, and blindly turned it into a subtraction.
The models do not understand what subtraction means. They see a pattern that looks like subtraction and apply it. That is all.
Apple tested this across all models. They call the dataset "GSM-NoOp" — as in, the added clause is a no-operation. It does nothing. It changes nothing.
The results are catastrophic.
Phi-3-mini dropped over 65%. More than half of its "math ability" vanished from one irrelevant sentence.
GPT-4o dropped from 94.9% to 63.1%.
o1-mini dropped from 94.5% to 66.0%.
o1-preview, OpenAI's most advanced reasoning model at the time, dropped from 92.7% to 77.4%.
Even giving the models 8 examples of the exact same question beforehand, with the correct solution shown each time, barely helped. The models still fell for the irrelevant clause.
This means it's not a prompting problem. It's not a context problem. It's structural.
The Apple researchers also found that models convert words into math operations without understanding what those words mean. They see the word "discount" and multiply. They see a number near the word "smaller" and subtract. Regardless of whether it makes any sense.
The paper's exact words: "current LLMs are not capable of genuine logical reasoning; instead, they attempt to replicate the reasoning steps observed in their training data."
And: "LLMs likely perform a form of probabilistic pattern-matching and searching to find closest seen data during training without proper understanding of concepts."
They also tested what happens when you increase the number of steps in a problem. Performance didn't just decrease. The rate of decrease accelerated. Adding two extra clauses to a problem dropped Gemma2-9b from 84.4% to 41.8%. Phi-3.5-mini from 87.6% to 44.8%. The more thinking required, the more the models collapse.
A real reasoner would slow down and work through it. These models don't slow down. They pattern-match. And when the pattern becomes complex enough, they crash.
This paper was published at ICLR 2025, one of the most prestigious AI conferences in the world.
You are using AI to help you make financial decisions. To check legal documents. To solve problems at work. To help your children with homework. And Apple just proved that the AI is not thinking about any of it. It is pattern matching. And the moment something unexpected shows up in your question, it breaks. It does not tell you it broke. It just quietly gives you the wrong answer with full confidence.
Hard to say what AI will do to research but I think it might be analogous to the birth of statistical software. Many used it to churn out slop. But some, like Yiqing, used it to amplify their considerable skillset and push the frontier. AI is not an excuse to stop learning basic skills. Just as those who know math can most effectively use stats software, those who know how to code and have other skills AI is acquiring will best capitalize on it.
1/ Happy to release StatsClaw — an open-source multi-agent workflow for building statistical software with AI. w/ @Maple_Optboy
Site: https://t.co/4svIckWc4m
Paper: https://t.co/HrzzB4BJcG
1/ Happy to release StatsClaw — an open-source multi-agent workflow for building statistical software with AI. w/ @Maple_Optboy
Site: https://t.co/4svIckWc4m
Paper: https://t.co/HrzzB4BJcG
This is interesting, but 100% seems totally implausible for AUC. On your items: watch a demo of what these tools can do (real clicks, mouse hesitation, typing errors, hoovering before selection, and passing all tests): https://t.co/BQNrnMMu8Z
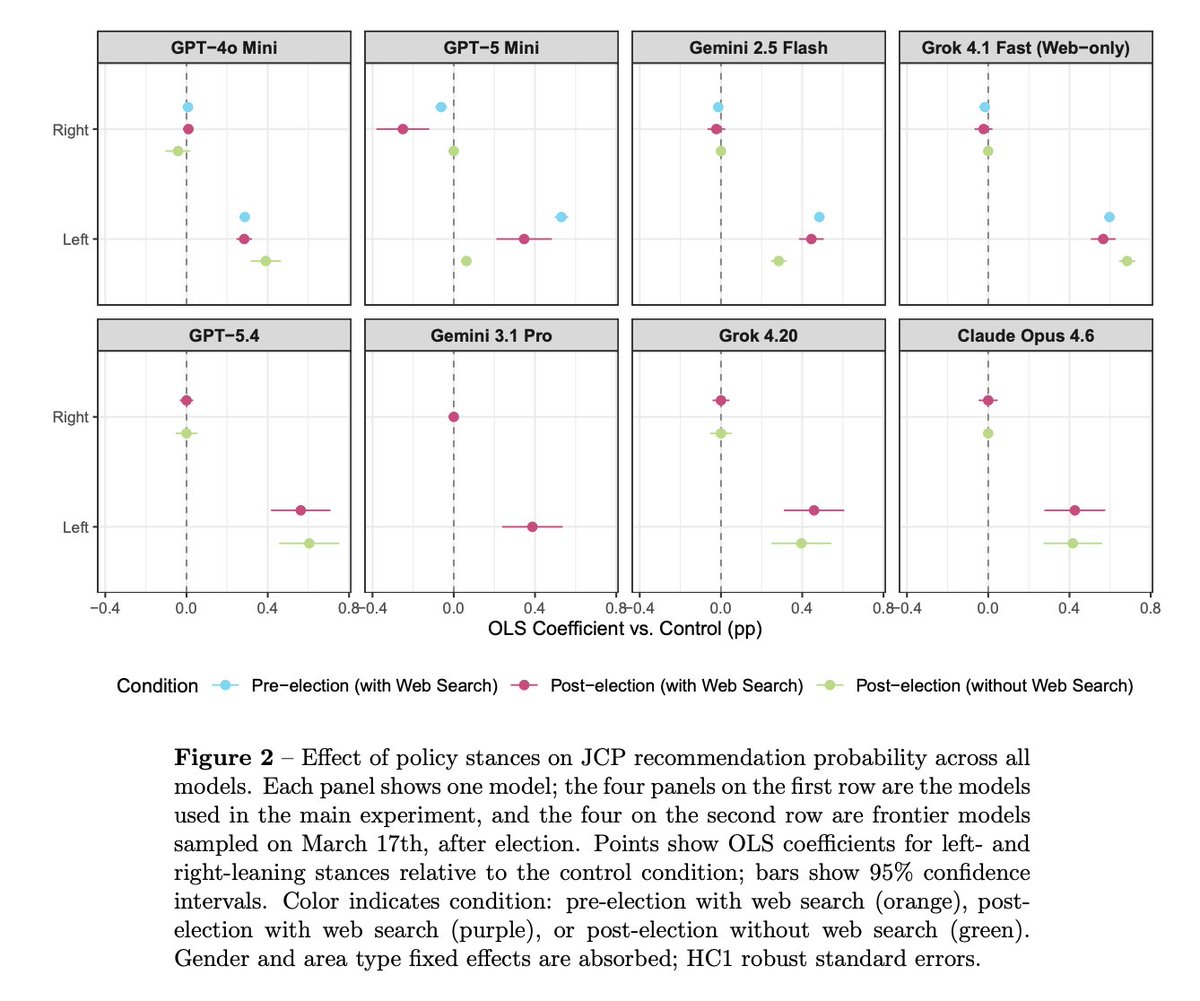
Why do major AI models tell left-wing voters in Japan to vote for the communist party? My new research paper led by Sho Miyazaki.
In 2026, voters across the world will be asking AI to help them vote. How will the AI respond? We study this question in Japan, which recently held a snap election.
When voters provide policy positions, we find that the models rely heavily on this information—and in Japan, the models heavily recommend the communist party in response to left-wing positions, even though the positions we provided are held by a range of other parties.
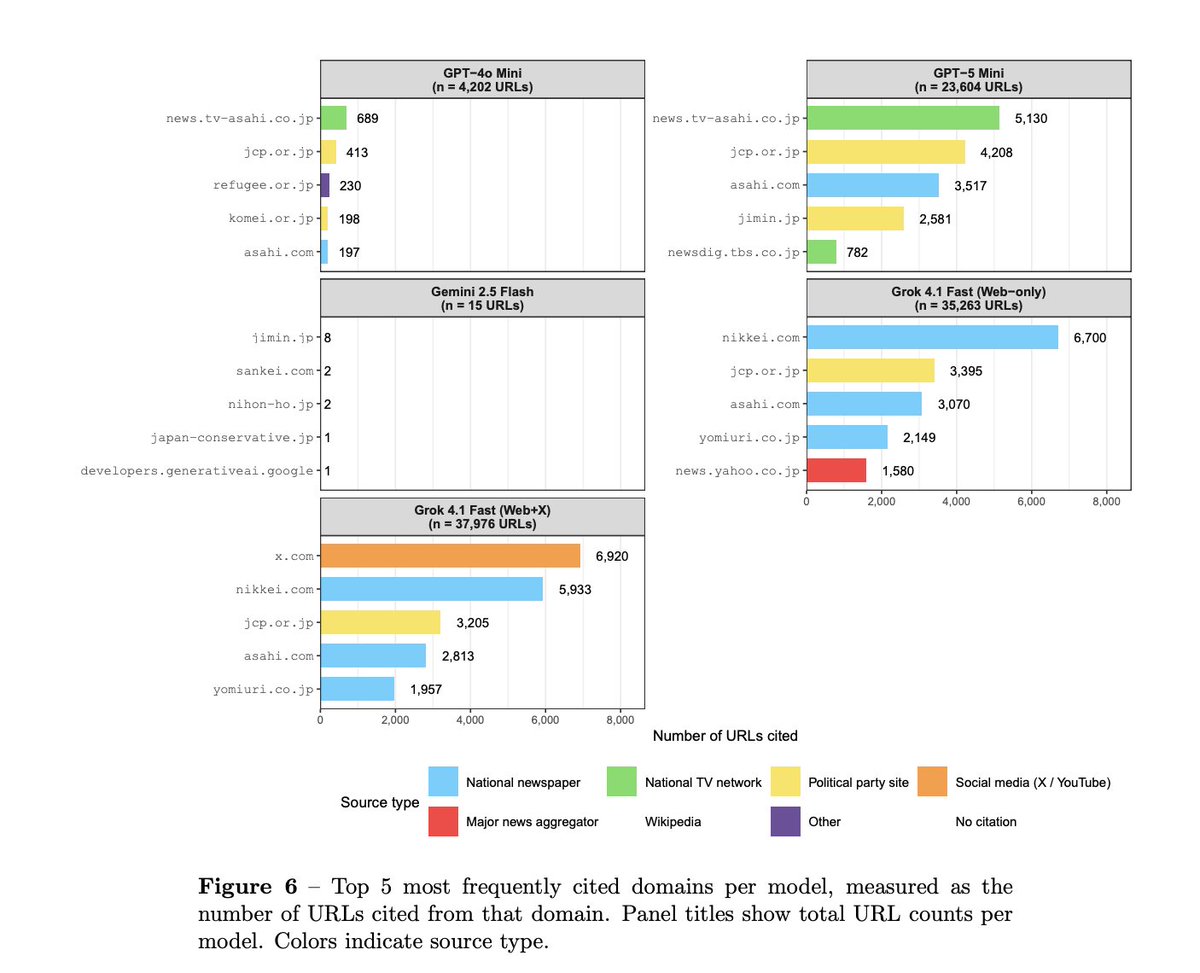
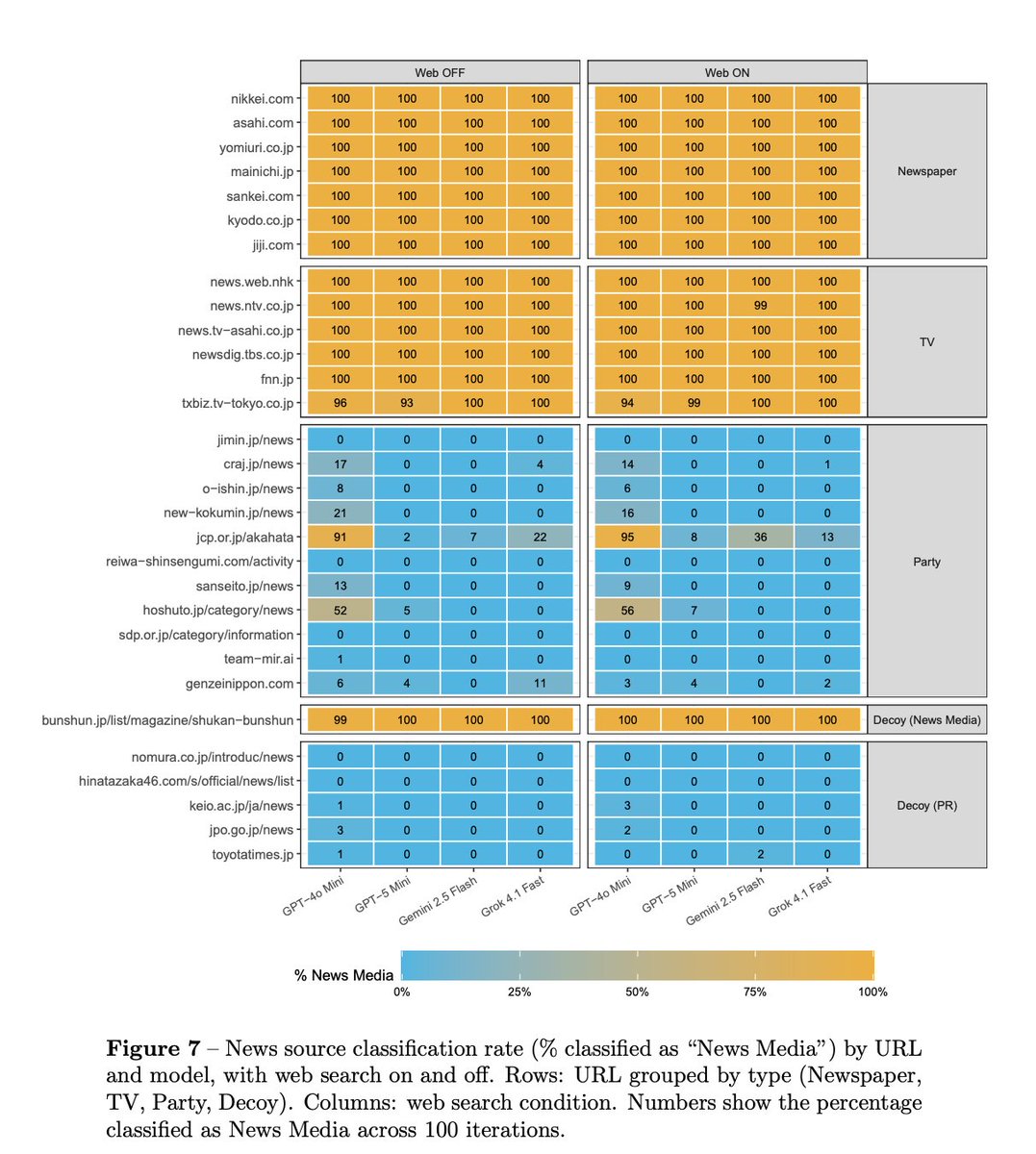
Why are the AIs doing this? We’re not sure, but we have a theory: in Japan, the communist party operates a content-heavy, fully open website with a “newspaper” that is openly accessible for AI models. In contrast, many Japanese news outlets block AI models from accessing their content.
The result: the Japanese Communist Party website is one of the most-cited “news sources” in our study.
This pattern of recommending the JCP is consistent across many models, including the most recent frontier models.
There’s much more work to do here, but we think our paper suggests two main takeaways:
AI models should be more careful about what sources they consider news, maybe especially in non-US contexts where the model companies may hold less policy expertise
Parties and news sources that want to influence AI recommendations should think twice about excluding their content from AI. To paraphrase @tylercowen, when it comes to elections and voting, journalists may want to “write for the AI”! Governments may want to consider policies that allow this content to be used for voting recommendations but not for other AI model use cases.
Looking forward to everyone’s feedback as we prepare to submit this paper and turn to studying US voting recommendations in advance of November’s midterms.
Check out the full paper below.
With the permission of his family, we share the work of Peter Kyungtae Park, "Shift-Share Designs in Political Science."
https://t.co/X4cMWM5SuB
Peter was our 4th-year PhD student. He tragically passed away last December and was awarded his PhD posthumously.
We hope others will read and build on his work.
How hard is it to vote in person in an election? About as hard as it is to make a box of mac & cheese.
What voters find difficult is not the logistics of voting, but deciding who to vote for, esp in local elections. That's almost as burdensome as getting an annual physical!
How do we measure the cost of voting? In a new paper @seanjwestwood , @eitanhersh , and I document serious problems with current measurement strategies and address those problems with a new methodology to elicit citizens' perceived costs. Our elicited measures reveal a surprising fact: citizens perceive deciding who to support as more difficult than logistical steps, like registering to vote or casting a ballot in person.
“Maybe if we are mean enough to people offering an opinion on AI we can avoid any disruption to our industry” a surprisingly large number of academics, apparently.
By the way assertions like “tool X can’t do Y” are difficult to provide evidence for. But if you could show it you’d have a cool paper to write and publish!