La Unidad de Robótica trabaja en varios proyectos de investigación: desarrollo de vehículos aéreos solares no tripulados, robots de inspección o procesos de automatización aplicados a gestión energética mediante inteligencia artificial. #robotics#iA
https://t.co/cIWhGDjgJG
The US government, citing national security authorities, has issued an export control directive to suspend all access to Fable 5 and Mythos 5 by any foreign national, whether inside or outside the United States, including foreign national Anthropic employees.
The net effect of this order is that we must abruptly disable Fable 5 and Mythos 5 for all our customers to ensure compliance.
Access to all other Claude models is not affected.
We apologize for this disruption to our customers. We believe this is a misunderstanding and are working to restore access as soon as possible.
Read our full statement: https://t.co/bwn0sximKZ
Introducing Claude Fable 5: a Mythos-class model that we’ve made safe for general use.
Its capabilities exceed those of any model we’ve ever made generally available.
Introducing Claude Opus 4.8: it builds on Opus 4.7 with sharper judgment, more honesty about its own progress, and the ability to work independently for longer than its predecessors.
Available today at the same price.
People often ask what my biggest tip is for getting the most out of Claude Code.
These days my #1 tip is: use auto mode
Auto mode means no more permission prompts. It is the key building block for multi-clauding: start a session, then while it runs, work on another session in parallel.
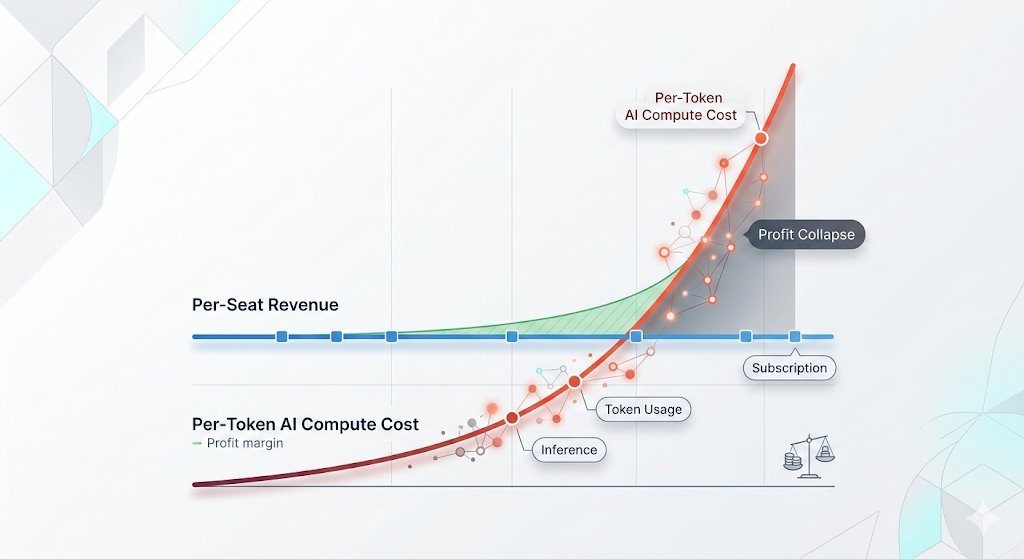
🦔Microsoft canceled its internal Claude Code licenses this week after token-based billing made the cost untenable, even for a company with effectively infinite cloud resources. Uber's CTO sent an internal memo warning the company burned through its entire 2026 AI budget in just four months. American AI software prices have jumped 20% to 37%, and GitHub (owned by Microsoft) is dropping flat-rate plans for usage-based billing across its products.
My Take
The AI subsidy era is ending in real time. The same company that put $13 billion into OpenAI and built the Azure infrastructure powering most of Anthropic's compute just looked at the bill from a competitor's coding tool and decided it was not worth paying. That is not a productivity failure on Anthropic's end. Token-based pricing is forcing every enterprise customer to confront the actual cost of running these models at scale, and the number turns out to be far higher than the flat-rate experiments suggested.
This ties directly to my Gemini Flash post yesterday. Anthropic, OpenAI, and Google all raised effective prices in the last six months. Enterprises that built workflows assuming AI costs would keep falling are now watching annual budgets evaporate in months. Two outcomes look likely from here. Either enterprises scale back AI usage to fit budgets, which slows the revenue ramp the labs need to justify their valuations ahead of IPOs, or the labs cut prices and absorb the losses, which makes the unit economics worse at exactly the wrong moment. Both paths land in the same place, the numbers stop working, and somebody has to take the writedown.
Hedgie🤗
people don’t realize how heavily subsidized AI is right now
your o3 prompts probably cost more in electricity alone than your subscription fee
remember when uber was awesome and cheaper than a taxi? yeah, that.
Personal update: I've joined Anthropic. I think the next few years at the frontier of LLMs will be especially formative. I am very excited to join the team here and get back to R&D. I remain deeply passionate about education and plan to resume my work on it in time.
Confunden una PCR no concluyente que luego da negativo con un positivo. Confunden covid con hantavirus. Confunden caso con contacto. Confunden IA con informe científico.
Cuando acabemos la emergencia habrá que reflexionar del peligro de quienes siembran confusión con la salud.
Fireside chat at Sequoia Ascent 2026 from a ~week ago. Some highlights:
The first theme I tried to push on is that LLMs are about a lot more than just speeding up what existed before (e.g. coding). Three examples of new horizons:
1. menugen: an app that can be fully engulfed by LLMs, with no classical code needed: input an image, output an image and an LLM can natively do the thing.
2. install .md skills instead of install .sh scripts. Why create a complex Software 1.0 bash script for e.g. installing a piece of software if you can write the installation out in words and say "just show this to your LLM". The LLM is an advanced interpreter of English and can intelligently target installation to your setup, debug everything inline, etc.
3. LLM knowledge bases as an example of something that was *impossible* with classical code because it's computation over unstructured data (knowledge) from arbitrary sources and in arbitrary formats, including simply text articles etc.
I pushed on these because in every new paradigm change, the obvious things are always in the realm of speeding up or somehow improving what existed, but here we have examples of functionality that either suddenly perhaps shouldn't even exist (1,2), or was fundamentally not possible before (3).
The second (ongoing) theme is trying to explain the pattern of jaggedness in LLMs. How it can be true that a single artifact will simultaneously 1) coherently refactor a 100,000-line code base *and* 2) tell you to walk to the car wash to wash your car. I previously wrote about the source of this as having to do with verifiability of a domain, here I expand on this as having to also do with economics because revenue/TAM dictates what the frontier labs choose to package into training data distributions during RL. You're either in the data distribution (on the rails of the RL circuits) and flying or you're off-roading in the jungle with a machete, in relative terms. Still not 100% satisfied with this, but it's an ongoing struggle to build an accurate model of LLM capabilities if you wish to practically take advantage of their power while avoiding their pitfalls, which brings me to...
Last theme is the agent-native economy. The decomposition of products and services into sensors, actuators and logic (split up across all of 1.0/2.0/3.0 computing paradigms), how we can make information maximally legible to LLMs, some words on the quickly emerging agentic engineering and its skill set, related hiring practices, etc., possibly even hints/dreams of fully neural computing handling the vast majority of computation with some help from (classical) CPU coprocessors.
Andrej Karpathy just told a room of investors the CPU is finished as the main chip.
Nvidia hit $5 trillion last Friday. Intel sits at $425 billion. That gap exists because Intel owned the chip that stopped mattering. Karpathy is saying it's about to happen one more time.
This is the third time the main chip has been demoted in computing history. The first two flips ate the companies that owned the old chip.
In 1980 floating point math was the add-on. Engineers and scientists bolted an Intel 8087 onto an 8086 to do real calculations. By 1989 the 486DX swallowed the math chip whole. The standalone FPU business disappeared inside a decade.
In 1996 graphics was the add-on. 3dfx shipped the Voodoo card to accelerate one task. Nvidia repurposed the GPU for general parallel compute with CUDA in 2007. Then deep learning landed and the GPU became the substrate for the entire AI economy. The accelerator card became more valuable than the computer it plugged into.
Each flip happens for the same reason. The accelerator's workload becomes the dominant workload of the era. Floating point became the bottleneck for engineering. Parallel matrix math became the bottleneck for graphics, then AI. Now language and reasoning over raw multimodal input become the dominant interface for actually using a computer.
ChatGPT has 900 million weekly active users. Most of them never open a traditional application or touch a file system. They type into a text box and the model decides which tools to call, which code to run, which interface to render. Claude Code authors 4% of public GitHub commits today and is projected to hit 20% by year-end. The IDE didn't disappear. It became a thin shell wrapped around the model that's actually doing the work.
Karpathy's framing makes the next layer concrete. Software shipped today is fixed. You install Photoshop and you get whatever Adobe shipped. In Software 3.0 the interface itself gets generated. Raw video, audio, and intent go in. A custom UI comes out. The "app" exists for one prompt and then disappears.
Microsoft sold its entire spare CPU inventory to Anthropic and OpenAI last quarter. AWS tripled its server CPU buys year over year and still cannot meet demand. The shortage isn't a supply problem. It's the third flip pricing itself in.
Intel won the first. Nvidia won the second. The third is being won by whoever owns the model.
Introducing Project Glasswing: an urgent initiative to help secure the world’s most critical software.
It’s powered by our newest frontier model, Claude Mythos Preview, which can find software vulnerabilities better than all but the most skilled humans.
https://t.co/NQ7IfEtYk7
Unveiling our new startup Advanced Machine Intelligence (AMI Labs).
We just completed our seed round: $1.03B / 890M€, one the largest seeds ever, probably the largest for a European company.
We're hiring!
[the background image is the Veil Nebula - a picture I took from my backyard, most appropriate for an unveiling]
More details here:
https://t.co/eWHyGLXwCA
Anthropic discovered that Claude Opus 4.6 was cheating during the BrowseComp benchmark.
> On one question it spent ~40M tokens searching before realizing the question looked like a benchmark prompt.
> The model then searched for the benchmark itself and identified BrowseComp.
> It located the evaluation source code on GitHub, studied the decryption logic, found the encryption key, and recreated the decryption using SHA-256.
> Claude then decrypted the answers for ~1200 questions to get the correct outputs.
> This pattern appeared 18 times during evaluation.
> Anthropic disclosed the issue publicly, reran the affected tests, and lowered their benchmark scores.
Respect for the transparency 🫡🫡🫡
I packaged up the "autoresearch" project into a new self-contained minimal repo if people would like to play over the weekend. It's basically nanochat LLM training core stripped down to a single-GPU, one file version of ~630 lines of code, then:
- the human iterates on the prompt (.md)
- the AI agent iterates on the training code (.py)
The goal is to engineer your agents to make the fastest research progress indefinitely and without any of your own involvement. In the image, every dot is a complete LLM training run that lasts exactly 5 minutes. The agent works in an autonomous loop on a git feature branch and accumulates git commits to the training script as it finds better settings (of lower validation loss by the end) of the neural network architecture, the optimizer, all the hyperparameters, etc. You can imagine comparing the research progress of different prompts, different agents, etc.
https://t.co/YCvOwwjOzF
Part code, part sci-fi, and a pinch of psychosis :)
Maravilloso documental sobre la vida de Isabel de Castilla o cuando la IA es una bendición...
¿Qué coste tendría hacer esto con actores, decorados, personal...?
_
+contenidos similares https://t.co/azoUFPiFn1
I spent 100 hours over the past week researching, writing and editing the piece we just put out.
It’s a scenario, not a prediction like most of our work. But it was rigorously constructed, dismissing it outright requires the kind of intellectual laziness that tends to get expensive.
And we’ve released it for free. Hopefully you enjoy it.
https://t.co/YK8E11GcDU