🚀 Thrilled to introduce https://t.co/Z8o4EhxWMW—a multi-agent system I’ve been developing specifically for prediction!
Would love for my fellow researchers and builders to test out the engine and share feedback!
🔗 https://t.co/Z8o4EhxWMW
#AgenticAI#WorldCup2026
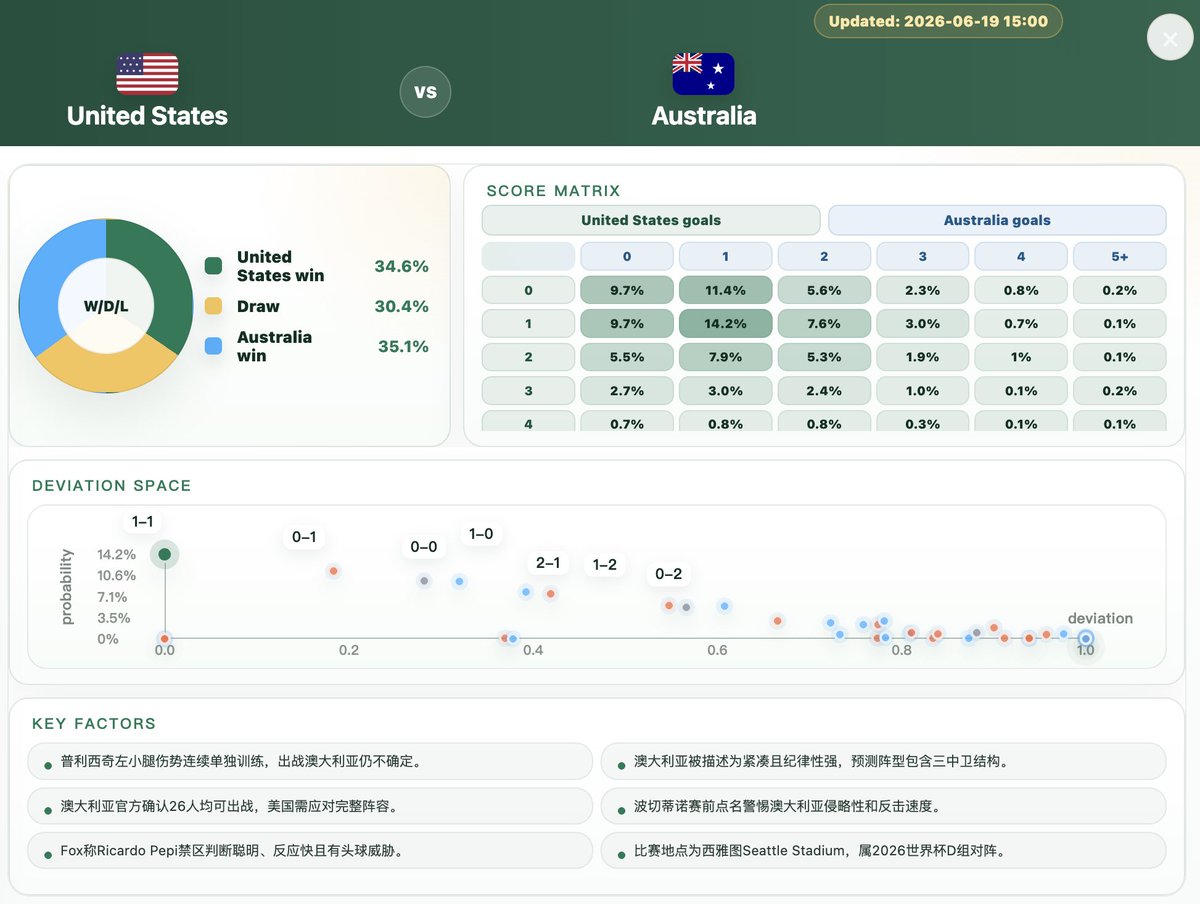
Our Agentic AI models crushed last night's slate with 100% winner accuracy!
🇨🇿 CZE 1:1 RSA 🇿🇦 ➡️ Top 2 Scores Hit!
🇲🇽 MEX 1:0 KOR 🇰🇷 ➡️ Top 2 Scores Hit!
🇨🇭 SUI & 🇨🇦 CAN ➡️ Winners Locked!
👇 Today's AI Probability Matrix in the thread below! 🔗 https://t.co/9dG2CBsAr5
📢 Call for Papers – SDAD Workshop @ ECCV 2026
📍 Malmö, Sweden
🚗 Safe & Defensive Autonomous Driving
📅 Deadline: July 15, 2026
📄 7-page short or 14-page long papers
🔗 https://t.co/MV4ORutgG6
Sponsored by @DeepRouteAI
#ECCV2026#AutonomousDriving#Safety#CallForPapers
Robust-U1 equips multimodal LLMs with visual self-recovery
Corrupted images break understanding.
This ICML work trains models to self-restore pixels.
Recovery uses supervised training, RL with pixel and semantic rewards, and joint reasoning over both views.
Can Video AI know exactly when to answer as a video plays?
Researchers from Northwestern Polytechnical University, Tsinghua University, HKUST, and others introduce Response-G1.
Instead of guessing when to speak, it builds a live scene graph—a map of objects and relationships—from each video clip, then matches it against your question’s requirements. No retraining needed.
It significantly beats prior methods on both proactive (knowing when to chime in) and reactive (answering after the full video) benchmarks.
Response-G1: Explicit Scene Graph Modeling for Proactive Streaming Video Understanding
Paper: https://t.co/IHM3RH0Njt
Code: https://t.co/U4lMmoJ8EK
Our report: https://t.co/l3oVRm5BUi
📬 #PapersAccepted by Jiqizhixin
Happy to introduce Response-G1 #ACL2026 — a proactive agent for streaming video understanding.
📄 Paper: https://t.co/xaV5ytayNC
📷 Code: https://t.co/yC30myJQop
We are happy to have a further discussion!!!
#ACL2026#AI#Multimodal#VideoUnderstanding#OpenSource#LLM