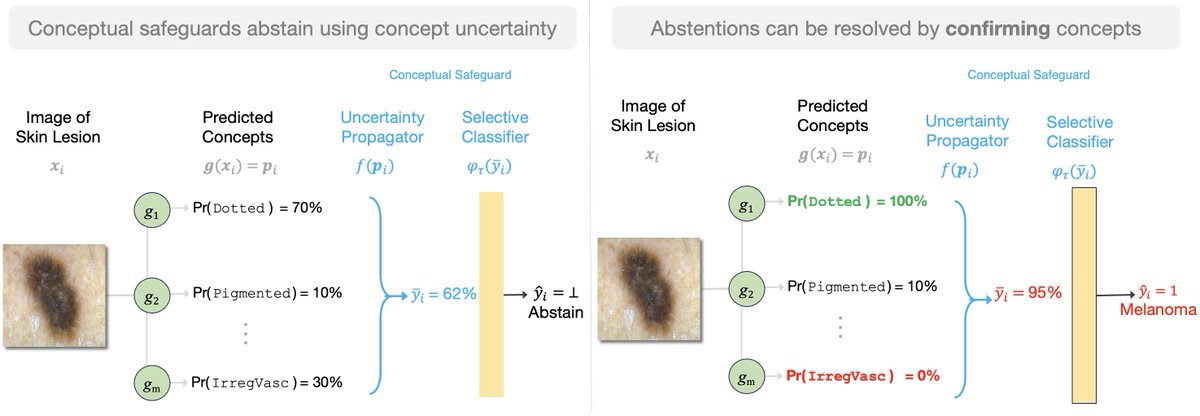
Do we really need to learn from our mistakes? Couldn’t we just… make optimal decisions like computers 🤖 and not make mistakes?
Well, our new work accepted in Computational Brain & Behavior journal indicates that it might be possible!
https://t.co/uFw5gwgZY2 🧵👇1/9
I recently gave a 15-min talk at #NeurIPS2025 on why "interpretable" AI doesn't automatically lead to better human decisions, and discussed my research on human-AI collaboration.
Watch here: https://t.co/PtK9oIa5Af
We’ll be presenting @FAccTConference on 06.24 at 10:45 AM during the Evaluating Explainable AI session!
Come chat with us. We would love to discuss implications for AI policy, better auditing methods, and next steps for algorithmic fairness research.
#AIFairness#xAI
Right to explanation laws assume explanations help people detect algorithmic discrimination.
But is there any evidence for that?
In our latest work w/ David Danks @berkustun, we show explanations fail to help people, even under optimal conditions.
PDF https://t.co/RlKmlzxgxN
But if they are indeed used to dispute discrimination claims, we can expect multiple failed cases due to insufficient evidence and many undetected discriminatory decisions.
Current explanation-based auditing is, therefore, fundamentally flawed, and we need additional safeguards.
Today we introduce an AI co-scientist system, designed to go beyond deep research tools to aid scientists in generating novel hypotheses & research strategies. Learn more, including how to join the Trusted Tester Program, at https://t.co/1eqmTTZOLr
🧪 Introducing POPPER: an AI agent that automates hypothesis validation by sequentially designing and executing falsification experiments with statistical rigor.
🔥POPPER matched PhD-level scientists on complex bio hypothesis validation - while reducing time by 10-fold!
🧵👇
✅Easy: train a model to automate a routine task
❌Hard: ensure the model is accurate with minimal human oversight
In our latest #ICLR24, we introduce a modeling paradigm for this setting
Joint w @CharlieTMarx@berkustun
PDF:https://t.co/NV8Znqz0yn
ICLR:https://t.co/iGXJlvouXM
📢 Please RT 📢
I am recruiting PhD students to join my group at UCSD!
We develop methods for responsible machine learning - with a focus on fairness, interpretability, robustness, and safety.
Check out https://t.co/dZzD2z5qa1 for more information.
🚨 NEW PAPER 🚨
Understanding increasingly large and complex neural networks will almost certainly require other AI models (themselves uninterpretable!)
How should we evaluate automated interpretability methods?
Introducing our new benchmark, FIND: https://t.co/cxZT86HfTQ
I'm thrilled to announce the launch of the Rational Altruism Lab at UCLA. We strengthen the scientific foundations for motivating and enabling people to pursue highly impactful altruistic projects. Please follow @RtnlAltruismLab for our news and updates.