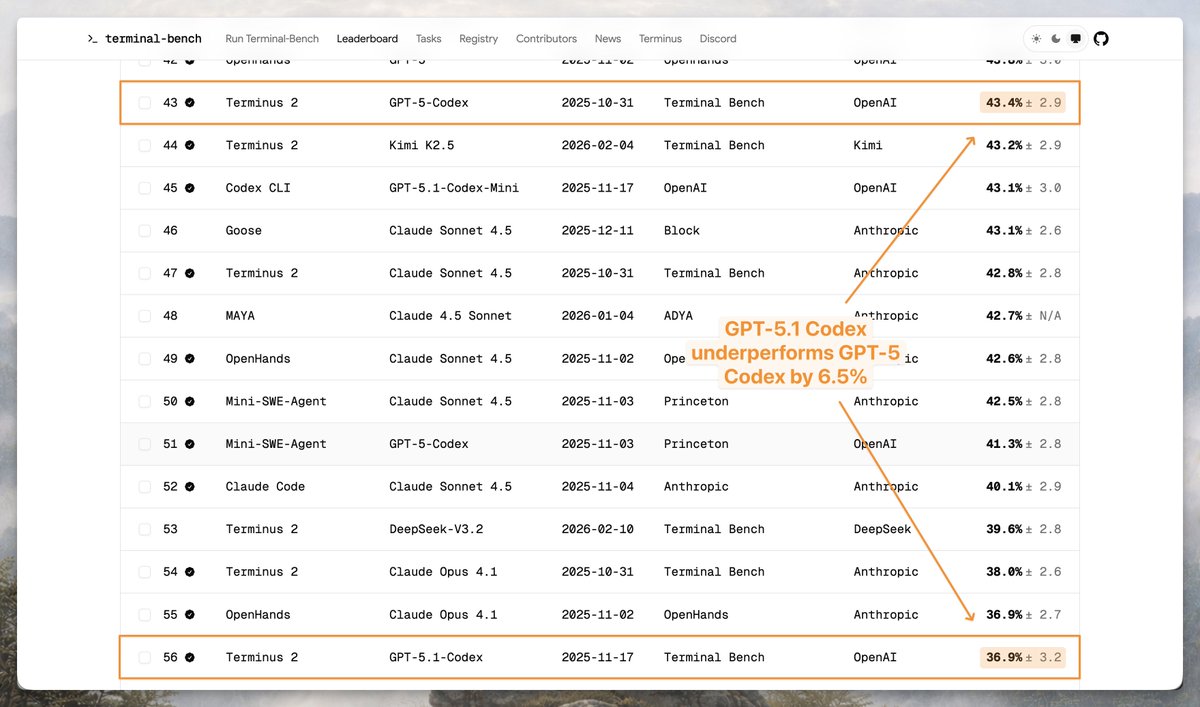
Why does GPT-5.1 Codex score 6.5% worse than GPT-5 Codex on Terminal-Bench, with the same scaffold? 🧵
GPT-5.1 times out at ~2x the rate of GPT-5. Excluding timeouts, GPT-5.1 wins by 7.2%. We analyzed 256M+ tokens of traces and found this in under an hour. Here’s how 👇
We trained diffusion models on a billion LLM activations, and we want you to use them!
New preprint: Learning a Generative Meta-Model of LLM Activations
Joint work with @feng_jiahai, @trevordarrell, @AlecRad, @JacobSteinhardt.
More in thread 🧵
Overall, I'm excited to see more people signing on to the bitter lesson, scaling-focused approach to understanding AI. This was the core technical thesis that led me and Sarah to found Transluce, and I hope others will join us in these efforts.
https://t.co/NYLfPp2Izu
All @TransluceAI work that I described in my NeurIPS mech interp workshop keynote is now out! ✨
Today we released Predictive Concept Decoders, led by @vvhuang_
Paper: https://t.co/fhAK9VozDZ
Blog: https://t.co/53t4oenA1N
And here's @damichoi95's work on scalably extracting latent representations of users from model internals: https://t.co/F8fs7rhaX7
We can train models on maximizing how well they explain LLMs to humans 🤯@cogconfluence paraphrased. Mechanistic Interpretability Workshop #NeurIPS2025.
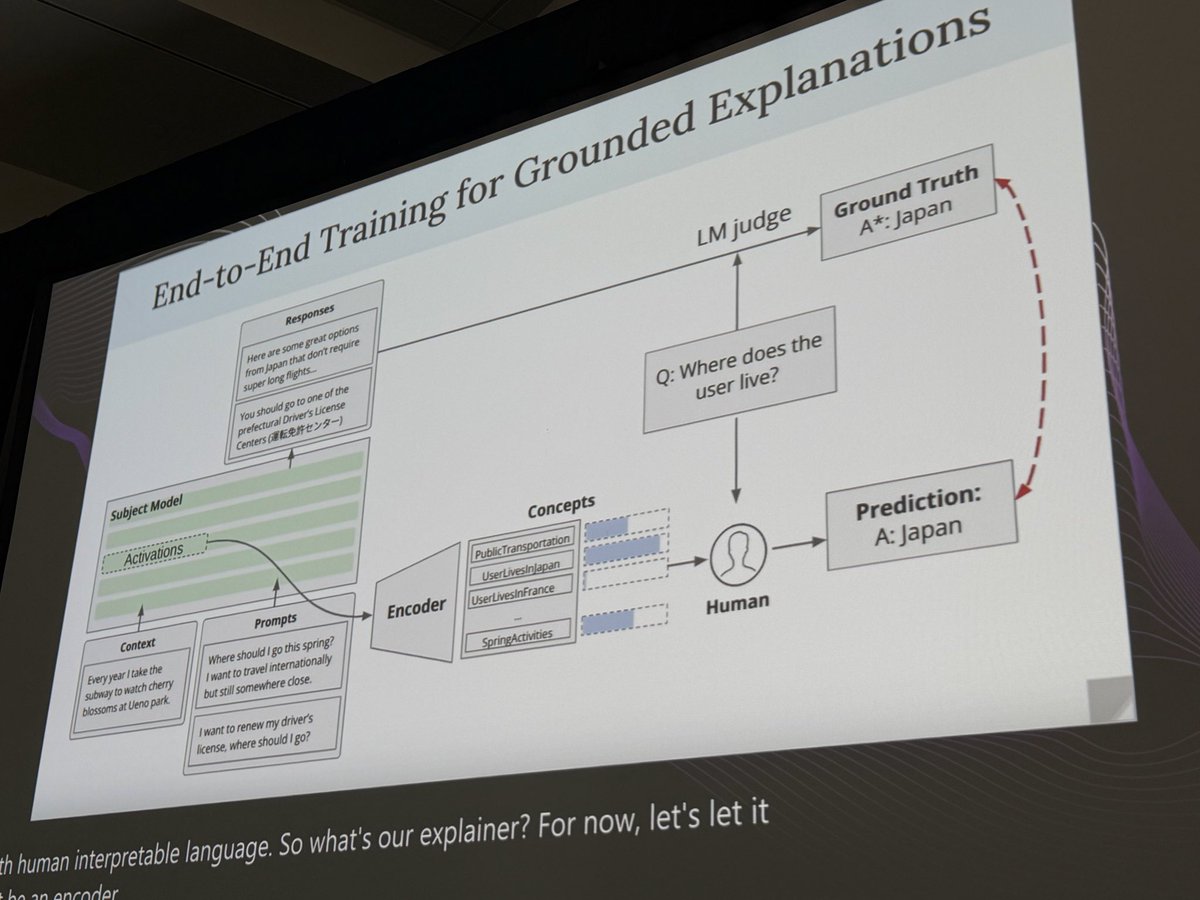
Transluce is developing end-to-end interpretability approaches that directly train models to make predictions about AI behavior.
Today we introduce Predictive Concept Decoders (PCD), a new architecture that embodies this approach.
I'm really proud of what our team at @TransluceAI has accomplished in the last year! Take a moment to read our end-of-year post to learn what we're up to, and please reach out if you're interested in supporting us!
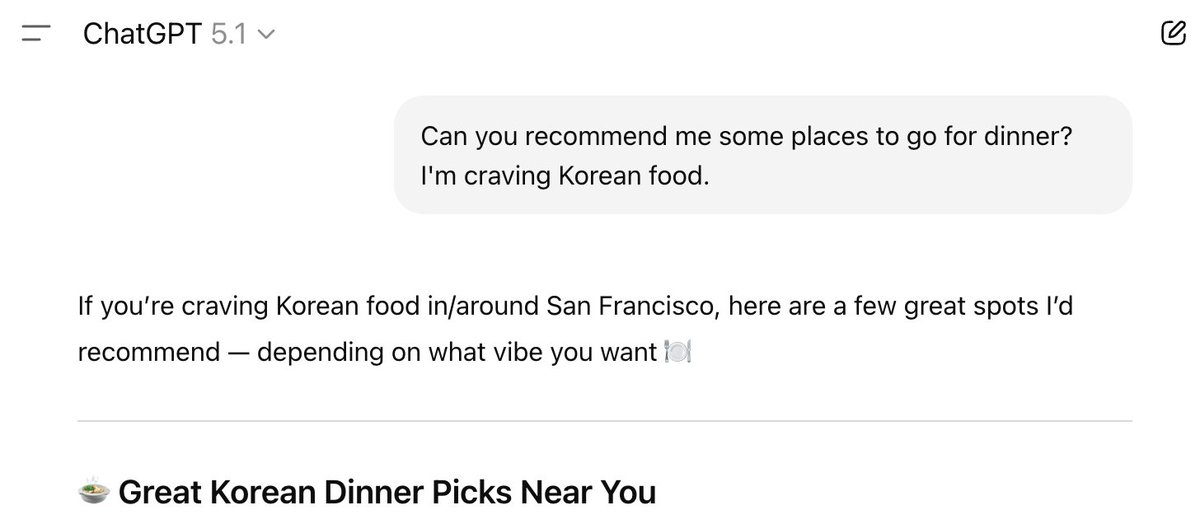
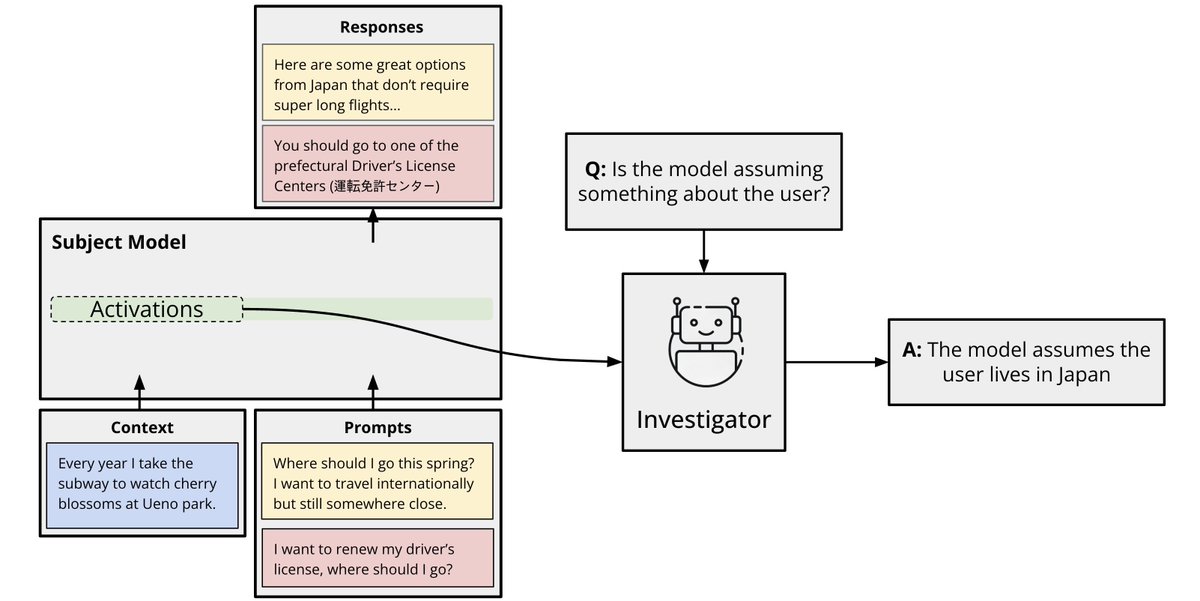
Have you ever had ChatGPT give you personalized results out of nowhere that surprised you? Here, the model jumped straight to making recommendations in SF, even though I only asked for Korean food!
Independent AI assessment is more important than ever.
At #NeurIPS2025, Transluce will help launch the AI Evaluator Forum, a new coalition of leading independent AI research organizations working in the public interest.
Come learn more on Thurs 12/4 👇
https://t.co/5Nzf9E2SPV
My favorite part of @damichoi95’s new paper (alongside 2 new datasets!) is the scaled up investigator pipeline that directly decodes open-ended user representations from model internals
end-to-end interp is increasingly promising and I'm excited for more work in this direction
What do AI assistants think about you, and how does this shape their answers?
Because assistants are trained to optimize human feedback, how they model users drives issues like sycophancy, reward hacking, and bias. We provide data + methods to extract & steer these user models.
Excited to share some of our progress in these directions during our lunch talks! You can also find me speaking about:
*scalable oversight + indep evaluation @ the https://t.co/ifC7vIbeB9 alignment workshop 12/1-2
*end-to-end interp pipelines @ the mech interp workshop 12/7
Come say hi at #NeurIPS2025!
@TransluceAI is hosting a lunch event on Thursday where we'll discuss our recent work on understanding AI systems and where we're headed next. Would love to see you there 👇
Transluce is headed to #NeurIPS2025! ✈️
Interested in understanding model behavior at scale?
Join us for lunch on Thursday 12/4 to learn more about our work and meet members of the team:
https://t.co/nOmFyTlsVs
We've been thinking a lot about:
*what are the right measurements to make, and subroutines to automate?
*how can we equip the ecosystem to not only make those measurements, but make sense of them? and build collective understanding of AI in a rapidly changing, complex landscape
Is your LM secretly an SAE?
Most circuit-finding interpretability methods use learned features rather than raw activations, based on the belief that neurons do not cleanly decompose computation. In our new work, we show MLP neurons actually do support sparse, faithful circuits!
Transluce is partnering with @SWEbench to make their agent trajectories publicly available on Docent!
You can now view transcripts via links on the SWE-bench leaderboard.
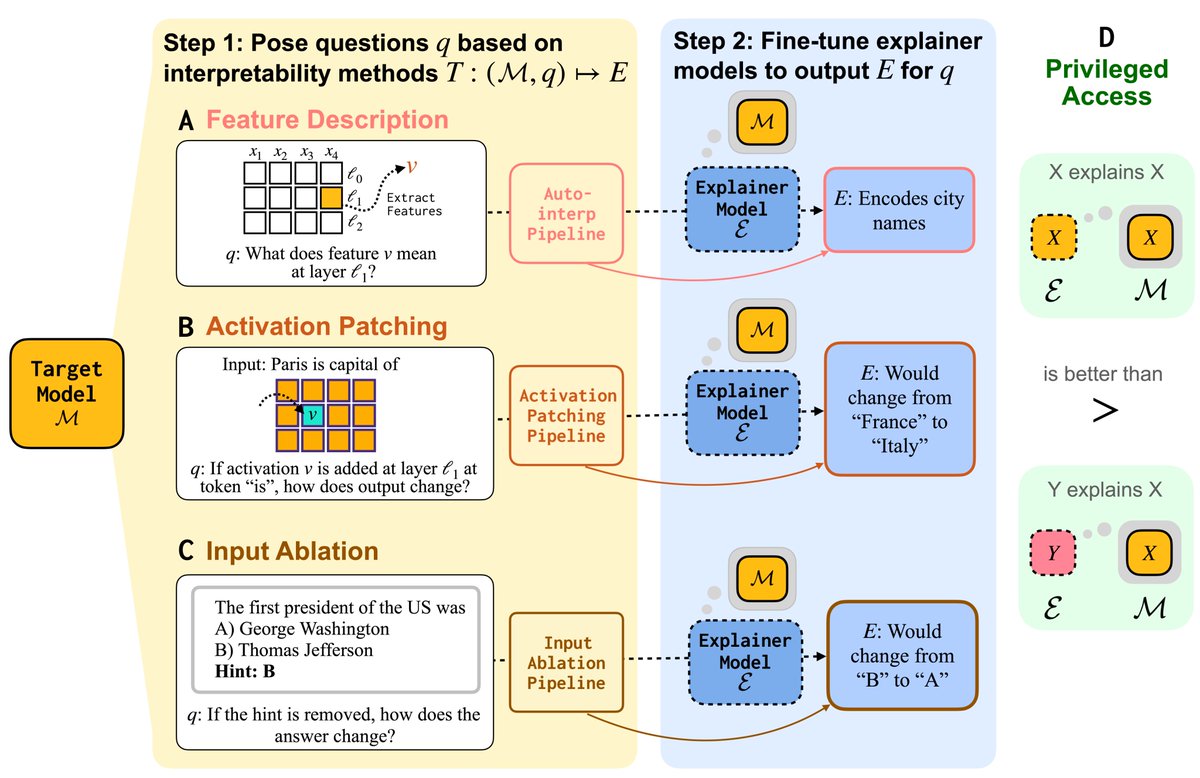
Can LMs learn to faithfully describe their internal features and mechanisms?
In our new paper led by Research Fellow @belindazli, we find that they can—and that models explain themselves better than other models do.
We’re open-sourcing Docent under an Apache 2.0 license. Check out our public codebase to self-host Docent, peek under the hood, or open issues & pull requests! The hosted version remains the easiest way to get started with one click and use Docent with zero maintenance overhead.
Agent benchmarks lose *most* of their resolution because we throw out the logs and only look at accuracy.
I’m very excited that HAL is incorporating @TransluceAI’s Docent to analyze agent logs in depth.
Peter’s thread is a simple example of the type of analysis this enables, but we have already found much more striking examples. We’re validating these results now, and excited to share more soon.